Über das Python Paket hdbcli kann auf Daten in der SAP Datasphere zugegriffen werden, sodass komplexe Advanced-Analytics-Use Cases umgesetzt werden können. Das Paket wird direkt von SAP betreut, weshalb der Zugriff lizenzkonform erfolgt. Über die Schnittstellen der Datasphere kann so auch auf Daten von anderen SAP-Quellsystemen (SAP ERP, BW oder HANA Db) zugegriffen werden.
Dieser Artikel zeigt, wie die Programmiersprache Python genutzt werden kann, um auf Daten in der SAP Datasphere zuzugreifen. Dabei können nicht nur Daten gelesen werden, sondern jegliche Datenbankoperationen durchgeführt werden. Das bedeutet, es können auch Daten zurück in die Datasphere geschrieben werden.
Python ist eine weit verbreitete Programmiersprache, die vor allem für Data-Science und Data-Analytics-Use Cases genutzt wird. Für eine hohe Flexibilität kann es also sinnvoll sein, die Daten aus der Datasphere mit Python zu analysieren. Die Datasphere bietet zwar eine Möglichkeit, Python zu nutzen, allerdings sind die Möglichkeiten dabei eingeschränkt. Der folgende Artikel dient dabei als Einstieg und konzentriert sich auf die SAP Datasphere und den Datenzugriff durch das hdbcli Paket.
1. Der Use Case
In diesem Artikel wird ein Beispiel präsentiert, bei dem auf Basis historischer Daten eine Vorhersage erstellt werden soll. Dabei werden die relevanten Daten in der SAP Datasphere abgelegt und dann mit Python analysiert. Für den Datentransfer sind zunächst einige Vorbereitungen in der Datasphere und in der Python Umgebung nötig, die im folgenden Schritt für Schritt erklärt werden. Das Ganze wird an einem praxisnahen Beispiel demonstriert.
In unserem Beispiel befinden sich nun historische Geschäftsdaten in der SAP Datasphere. Auf Basis dieser Daten soll eine Vorhersage für die Zukunft erstellt werden. Für die Vorhersage sollen spezielle Python Bibliotheken für Zeitreihenanalyse genutzt werden und die Leistung soll flexibel skalierbar sein.
Dieses Skript nutzt eine Reihe an Python-Bibliotheken, die über die, von der Datasphere unterstützen, Bibliotheken Numpy und Pandas hinausgehen. Dazu könnten beispielsweise sklearn oder im Machine Learning Kontext tensorflow oder pytorch zählen.
Selbstverständlich sind auch andere Use Cases aus dem Bereich Data Analytics und Data Science umsetzbar.
2. Lösungsszenario
Ein möglichen Lösungsszenario sieht so aus, dass eine separate Python-Umgebung geschaffen wird. Diese kann ein lokaler Rechner oder eine cloudbasierte Containerlösung sein. Dort wird ein Skript ausgeführt, das die Daten aus der Datasphere ausliest und anschließend eine Vorhersage auf Basis dieser Daten erstellt. Letztlich werden die Vorhersagedaten zurück in die Datasphere geschrieben.
Aber wie genau funktioniert die Verbindung zwischen dieser Python Umgebung und der Datasphere? Dieser Fragen möchten wir im Folgenden auf den Grund gehen.
3. Vorbereitungen in der SAP Datasphere
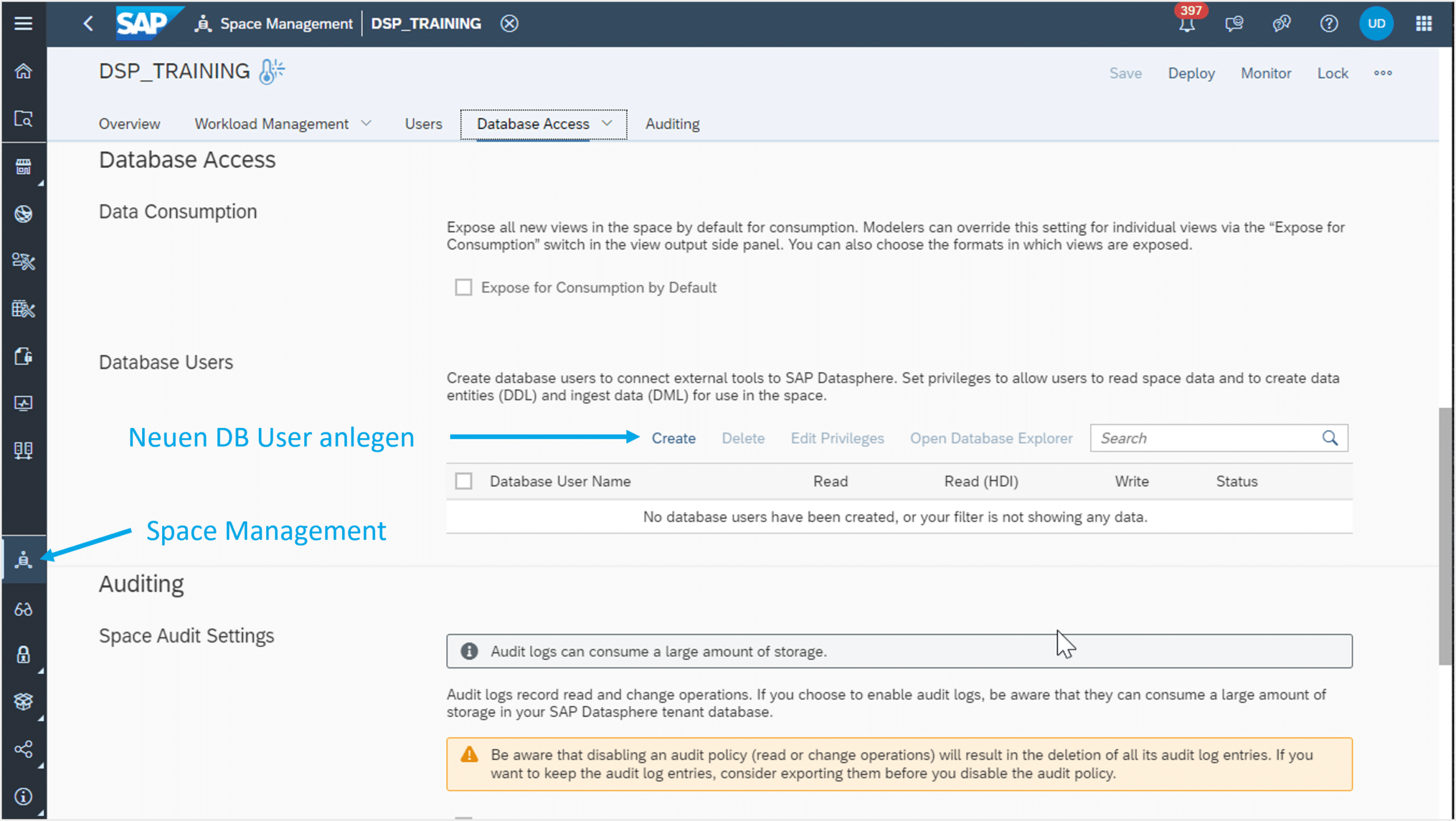
Zunächst muss ein Datenbank-User in der Datasphere erstellt werden. Dieser kann dort im Space Management, wie in Abbildung 1 zu sehen ist, angelegt werden
Abb.1: Anlegen eines neuen DB-Users | isr.de
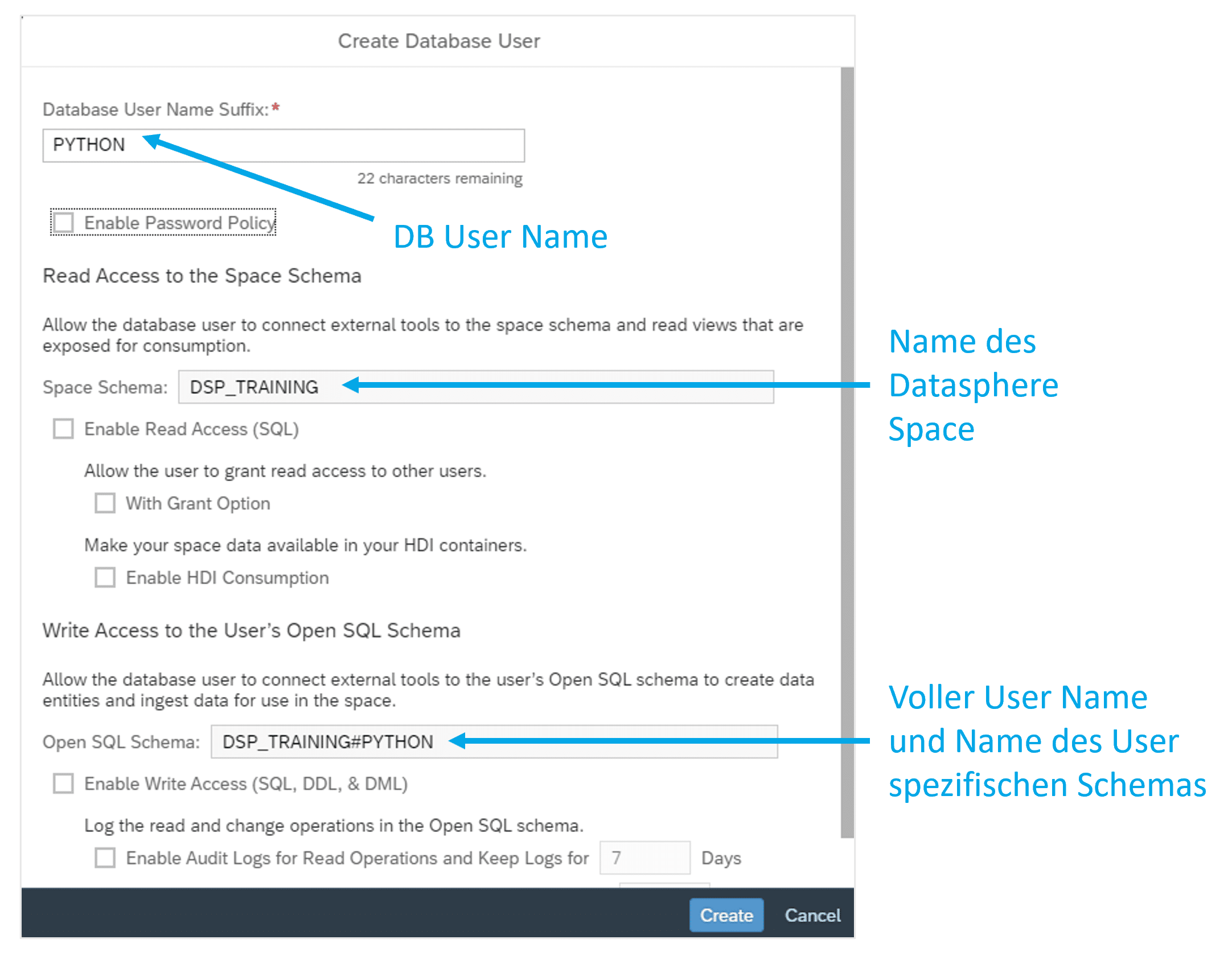
Der User erhält dabei stets einen Namen, der sich aus dem technischen Names des Datasphere Space, einer Raute und einem frei wählbaren Namen ergibt. Heißt der Space DSP_TRAINING, könnte der User den Namen DSP_TRAINING#PYTHON erhalten, wie in Abbildung 2 dargestellt. Dieser Name ist gleichzeitig auch ein Datenbankschema, das automatisch mit angelegt wird.
Abb.2: Benennung des neuen DB-Users | isr.de
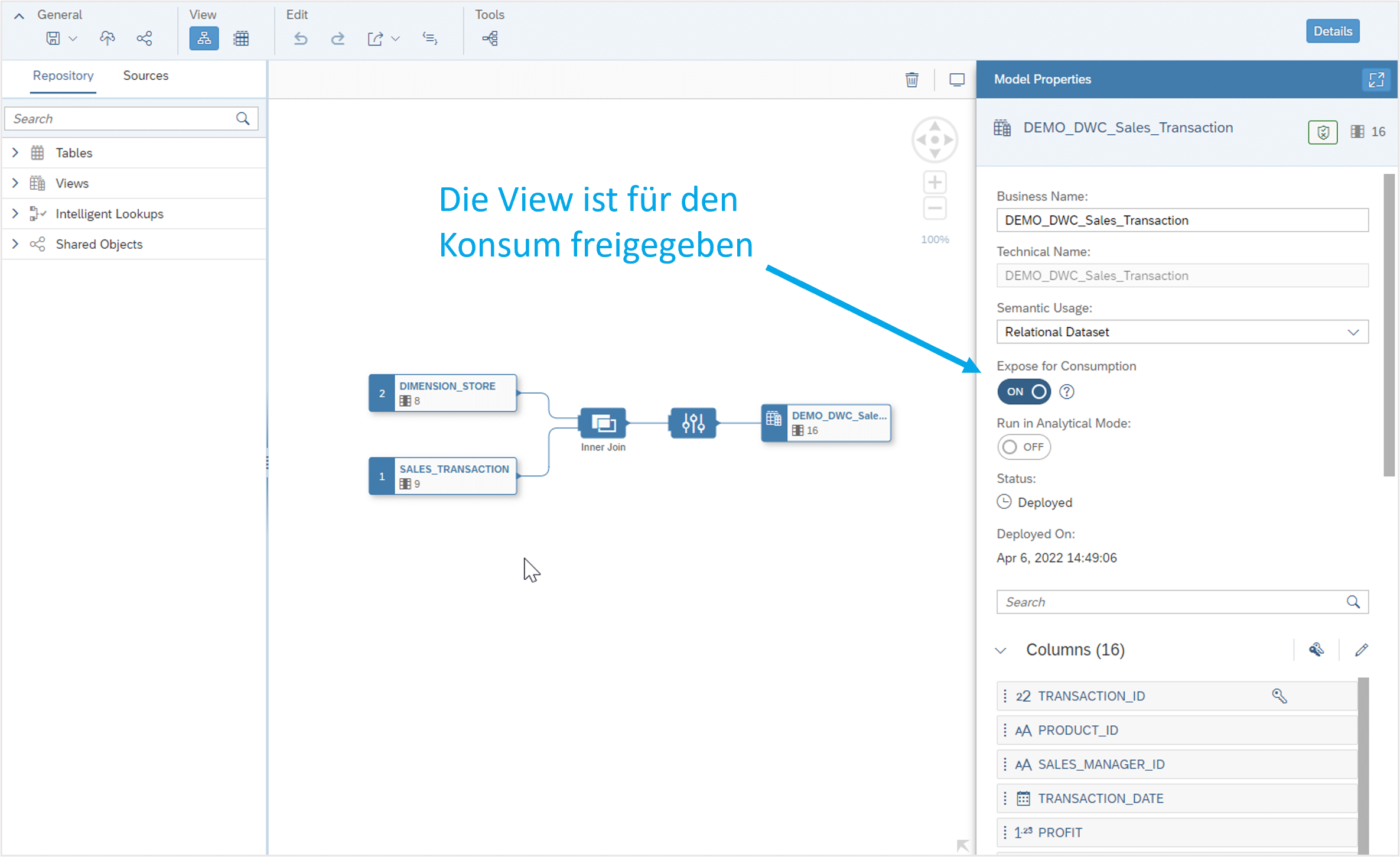
Der User kann aus dem ursprünglichen Datenbankschema (in diesem Fall einfach nur DSP_TRAINING) nur auf Daten in Views zugreifen, die für den Konsum freigegeben sind (s. Abbildung 3).
Abb.3: Zugriff auf Daten in Views | isr.de
In seinem eigenen Schema kann der User über Python auf alle Daten zugreifen und auch Daten zurückschreiben. Sobald in dem Schema des Users eine Tabelle erstellt wurde, kann diese über die Benutzeroberfläche der Datasphere auch in das ursprüngliche Schema des Space importiert werden.
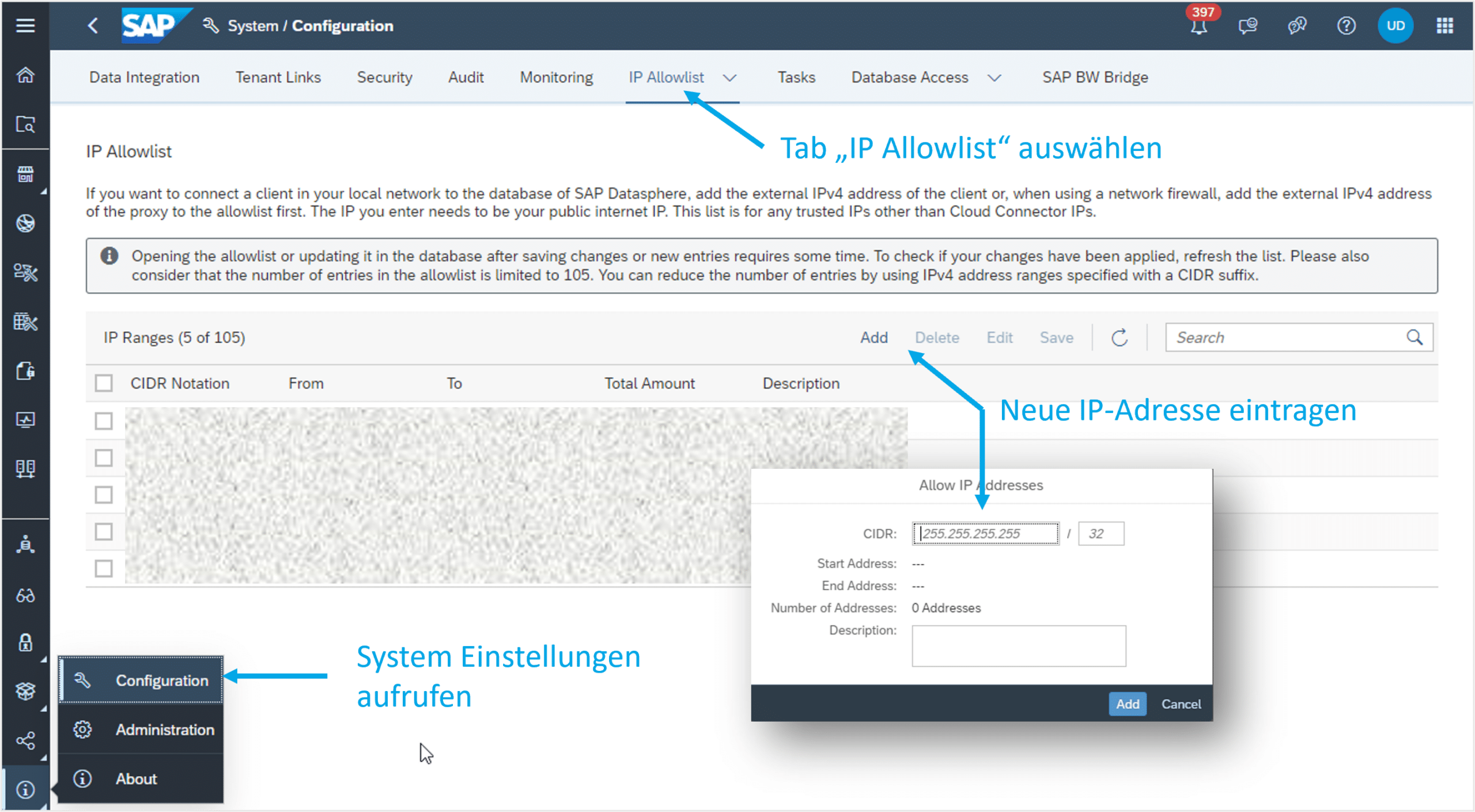
Auf das Konzept kommen wir am Ende des Artikels zurück und veranschaulichen dieses mithilfe einer Grafik (s. Abbildung 5). (Sprungmarke) Um auf die HANA Datenbank zuzugreifen, muss die IP-Adresse, über die der Zugriff erfolgt, ggf. auf die IP-Whitelist der Datasphere gesetzt werden. Andernfalls kann die Verbindung abgelehnt werden und folgende Fehlermeldung erscheint: “Connection failed (RTE:[89013] Socket closed by peer.”
Dafür müssen zunächst die Systemeinstellungen aufgerufen werden. Unter dem Tab IP Allow-list kann dann eine IP Adresse bzw. eine Liste an IP Adressen eingetragen werden (s. Abbildung 4). Anschließend müssen die Änderungen gespeichert werden, um effektiv zu werden.
Abb.4: IP-Adressen eintragen | isr.de
4. Zugriff auf Python
Um von Python aus auf die Daten der Datasphere zuzugreifen, wird das Paket hdbcli genutzt. Ist dieses noch nicht vorhanden, kann es einfach über die folgende Kommandozeile installiert werden:
pip install hdbcli
Nach der Installation kann dann eine Verbindung aufgebaut werden. Dazu werden die Zugangsdaten des angelegten Database-Users, die Adresse sowie der Port der HANA-Datenbank benötigt. Die Adresse und der Port können im Space Management angezeigt werden, indem die Details des neu angelegten Users über das I-Symbol rechts geöffnet werden:
from hdbcli import dbapi
conn = dbapi.connect(
address=”<address>”,
port=”<port>”,
user=”<username>”,
password=”<password>”
)
cursor = conn.cursor()
Nach der Erstellung der Verbindung wird ein cursor-Objekt erzeugt, dass für die Kommunikation mit der Datenbank genutzt wird. Mit ihm können SQL Statements ausgeführt werden. Im Folgenden finden Sie ein Beispiel, wie Daten aus der Datasphere gelesen werden können:
import pandas as pd
cursor.execute(‘SELECT * FROM DSP_TRAINING.VIEW_INPUT’)
df_input = pd.DataFrame(cursor.fetchall())
Das Ergebnis df_input ist ein Pandas DataFrame, der nun wie gewohnt genutzt werden kann. Werden nun Daten im Python-Skript erzeugt, die zurück in die Datenbank geschrieben werden sollen, muss zunächst eine Zieltabelle erstellt werden:
cursor.execute(“CREATE TABLE DSP_TRAINING#PYTHON.RESULTS (ID INTEGER, MONTH INTEGER, VALUE DECIMAL)”)
Um die Ergebnisse zurückzuschreiben, müssen noch einige Vorbereitungen getroffen werden. Die Ergebnisse müssen zunächst von einem Pandas DataFrame df_output in eine Liste list_output konvertiert werden. Außerdem wird das SQL-Insert Statement vorbereitet und mit Platzhaltern versehen. Anschließend wird das Statement ausgeführt, wobei die Daten als Argument mit angeführt werden:
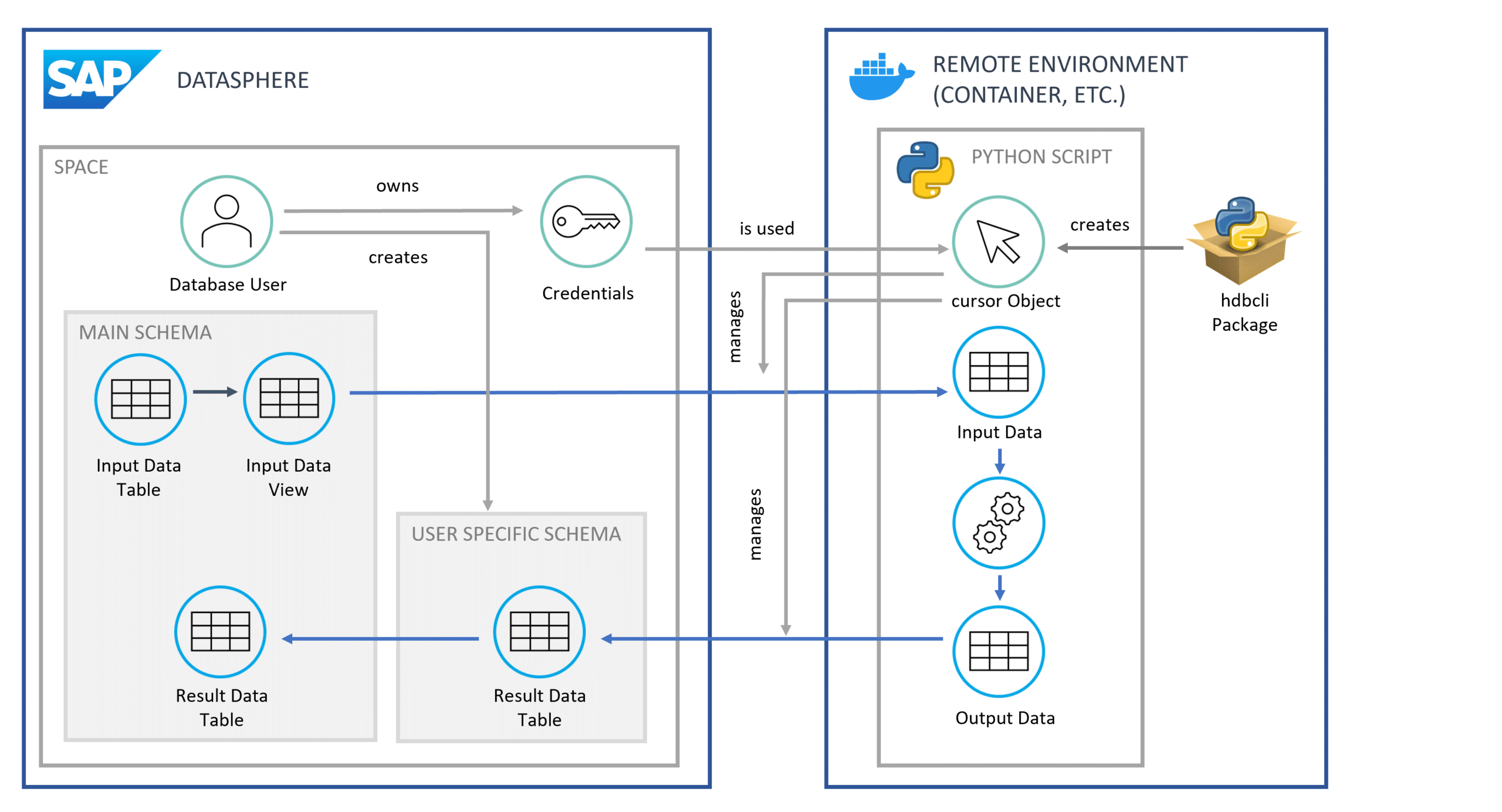
Zuletzt stellen wir in der folgenden Abbildung 5 das Konzept nochmal grafisch für Sie dar.
Abb.5: Grafische Darstellung des Konzepts | isr.de
5. Fazit und Ausblick
Das Paket hdbcli bietet die Möglichkeit, in einer Python-Umgebung auf Daten in einer SAP Datasphere zuzugreifen und Daten zurückzuschreiben.
Dadurch können komplexe Prozesse mit den Daten durchgeführt werden, die über die Funktionen der Datasphere hinausgehen.
Außerdem kann diese Methode als Schnittstelle zu Drittsystemen genutzt werden. Durch die einfache Anbindung der SAP Datasphere an zahlreiche SAP-Systeme wie ein ERP oder BW gelingt so eine relativ einfache Möglichkeit, Daten aus all diesen Systemen für Advanced-Analytics- und Big-Data-Use Cases zu verwenden. Diese Anbindung erfolgt dann vollständig automatisiert ohne manuelle Aktivitäten wie CSV Im- und Exporte.
Mit dem oben beschriebenen Vorgehen gelingt es Ihnen eine SAP-Landschaft reibungslos in eine moderne Cloud Architektur einzubinden.
Sie möchten mehr erfahren? Dann ist unser Discovery Workshop genau das Richtige für SIE.
SAP Datasphere Discovery Workshop
Lernen Sie gemeinsam mit unseren SAP-Experten SAP Datasphere kennen.
Wir agieren seit 1993 als IT-Berater für Data Analytics und Dokumentenlogistik und fokussieren uns auf das Datenmanagement und die Automatisierung von Prozessen. Ganzheitlich und im Rahmen eines umfassenden Enterprise Information Managements (EIM) begleiten wir von der strategischen IT-Beratung über konkrete Implementierungen und Lösungen bis hin zum IT-Betrieb. ISR ist Teil der CENIT EIM-Gruppe.