Eine Reportinglösung besteht in einer Basiskonfiguration aus mindestens einer Datenbank und einem Reportingtool jeweils in einer Entwicklungs- und Produktivumgebung. Dadurch können Änderungen effizient, aber auch sicher für Endnutzer bereitgestellt werden.
Zwischen diesen Umgebungen müssen in einem geregeltem Prozess Datenmodelle und Dashboards ausgetauscht werden, wobei bestimmte Datenmodelle und Dasboards, die sich in der Entwicklung befinden, nicht in der Produktivumgebung betrachtet werden sollten.
Wir geben einen ersten Überblick darüber, welche Herausforderungen bei dem Deployment von Datenmodellen und Artefakten eines Frontend-Reportingtools gelöst werden müssen. Des Weiteren werden die Schritte zum Aufbau eines geregelten Deploymentprozesses an einem konkreten Beispiel mit einer SAP HANA Datenbank und Apache Superset durchgegangen.
Unser Szenario
In diesem Blogartikel möchten wir uns mit der Umsetzung einer Mehrsystemlandschaft zur Darstellung von Dashboards und Charts auf Basis eines SAP HANA Datenmodells beschäftigen. Grundlage des Artikels ist eine Zweisystemlandschaft mit jeweils einer HANA-Datenbank sowie einem Frontendserver in einer Entwicklungs- und Produktivumgebung. Im konkreten Fall können aber auch mehr Server und eine Testumgebung genutzt werden.
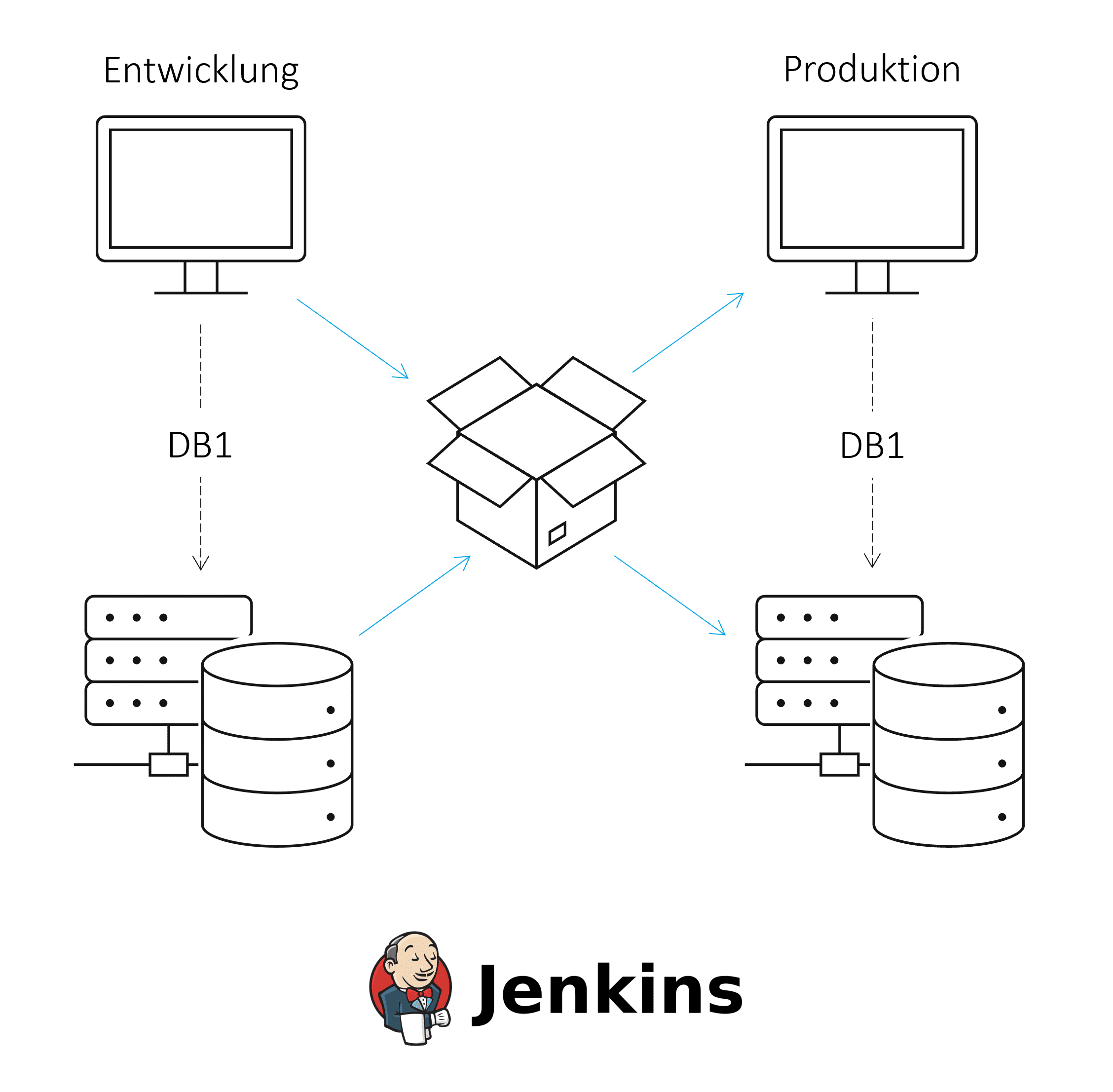
Für einen geregelten Deploymentprozess zwischen den Umgebungen sollte ein moderner, automatisierter und überwachter Continuous Integration und Continuous Delivery Prozess (CI/CD) entwickelt werden. Beim Continuous Integration werden Softwarekomponenten oder Änderungen regelmäßig zusammengeführt und getestet. Continuous Delivery erlaubt die Bereitstellung von Software in die Produktion. Durch CI/CD kann die Softwarequalität gesteigert und die Dauer der Bereitstellung von Änderungen minimiert werden.
Basis eines CI/CD Prozesses sind Tools zur Versionskontrolle, für den automatischen Build und zur Verwaltung der resultierenden Artefakte. Für weitere Informationen zum Thema CI/CD mit HANA siehe diesen ISR-Blogartikel.
Herausforderungen dieser Mehrsystem-Landschaft
Mehrere Herausforderungen müssen bei der Umsetzung beachtet werden:
Herausforderung 01: Laden der Dashboards in das Repository
Voraussetzung für den Transport der Dashboards in das Repository ist, dass diese dateibasiert vorliegen. In einer Datei sollten alle nötigen Informationen zur Definition des Objektes inkludiert sein. Dazu können unter anderem die Elemente des Dashboards mit Datenquelle und Platzierung, der Name oder auch das Erstelldatum gehören. Somit kann sichergestellt werden, dass jedes Dashboard auf Basis dieser Datei in anderen Umgebungen erstellt werden kann.
Herausforderung 02: Angleichung der Quellennamen der Datenbank
In einer Landschaft mit mindestens Entwicklungs- und Produktionsumgebung müssen die Dateiquellennamen in den Frontendsystemen verglichen werden, da jeweils auf das richtige Datenbanksystem zugegriffen werden muss.
Im Fall unterschiedlicher Quellnamen der Datenbanken müssen diese während des Transportes in die Produktivumgebung angepasst werden (bspw. via sed Kommando in Linux). Der Nachteil an dieser Lösung ist, dass erstens alle Stellen in den Dateien identifiziert werden müssen, bei denen auf die Datenbank referenziert wird. Diese Stellen können sich dynamisch verändern auf Basis der Inhalte und Struktur eines Dashboards. Zweitens ist ein automatisiertes Vorgehen fehleranfällig, da z.B. Stellen ersetzt werden, bei denen es eigentlich nicht gewünscht ist.
Auf der anderen Seite müssen bei gleichlautenden Quellnamen die Dateien nicht modifiziert werden, die Unterscheidbarkeit zwischen den Datenquellen in der Entwicklungs- und Produktivumgebung leidet aber.
Herausforderung 03: Transport des Datenmodells (siehe ISR-Artikel)
Bei dem Transport der Datenmodelle aus der HANA-Plattform ist es von Vorteil, dass bei Datenbankobjekte zwischen Designtime-Objekten und Runtime-Objekten unterschieden wird. Dadurch ist es möglich, z.B. Calculation Views wie gehabt in der Web IDE zu erstellen, und das Deployment manuell in Skripten zu steuern.
Herausforderung 04: Beachtung der Abhängigkeiten zwischen Version des Dashboards und des Datenmodells
Um die Abhängigkeiten zwischen den Dateien für die Dasboards und den Datenmodellen zu erfüllen, bieten sich zwei Wege an. Im Git kann für Dashboards und Datenmodelle jeweils ein Ordner erstellt werden. Alternativ kann man die Dateien in einem Artifact Repository kombiniert ablegen. Dabei ist es wichtig die Versionen der deployten Datenmodelle und Dashboards nachzuhalten, um Fehler im Transportprozess oder in der Produktion schnell lösen zu können.
CI/CD am Realbeispiel mit HANA-Datenbanken und Apache Superset
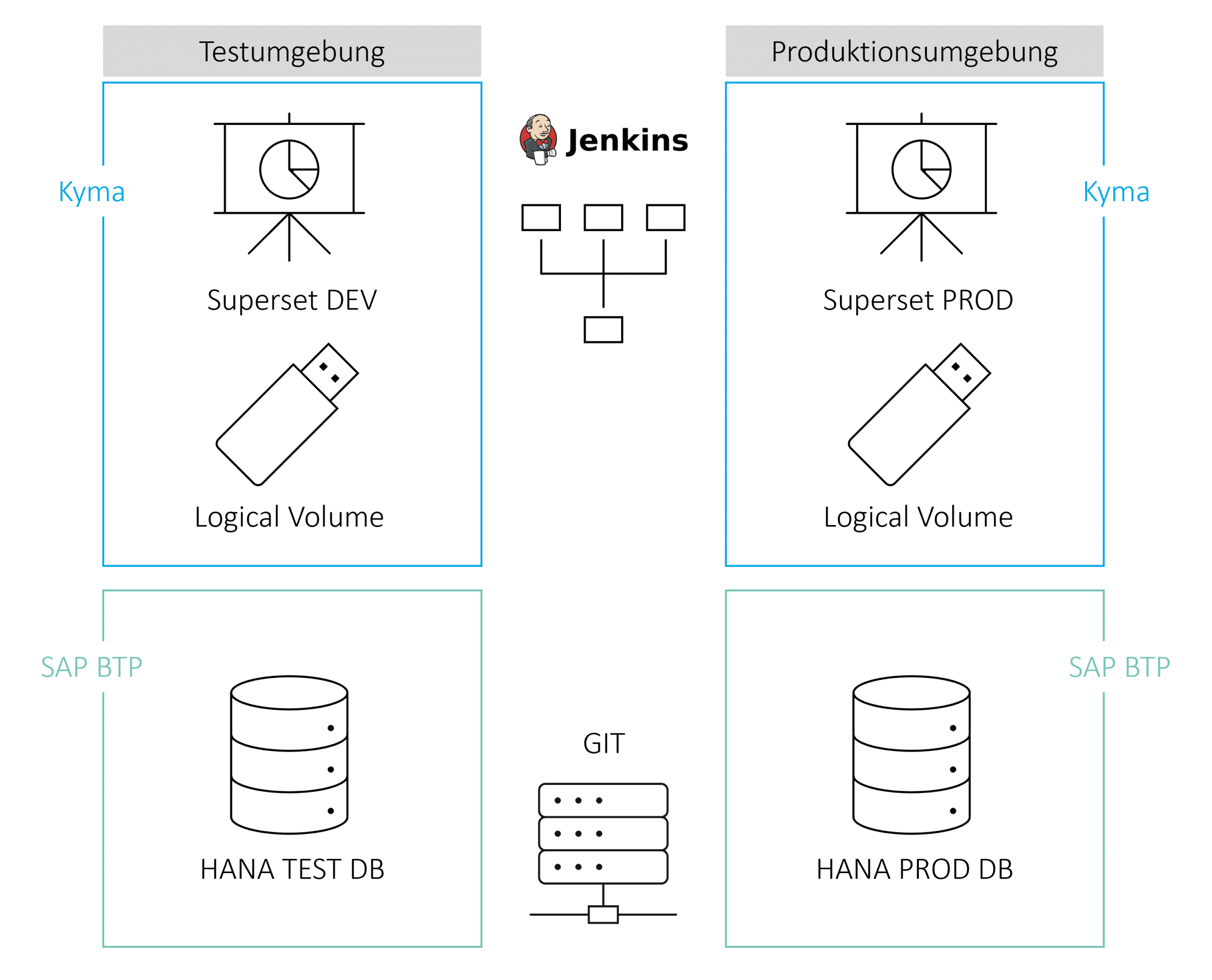
Die Architektur besteht aus einer Entwicklungs- und Produktivumgebung mit einer HANA-Datenbank in der SAP BTP und einer Apache Superset Instanz in der Kyma-Umgebung. Apache Superset wird als Frontend Tool zur Visualisierung der Daten genutzt und besteht aus Dashboards, Charts, Datasets und hinterlegten Datenquellen. Diese Artefakte werden in einem Logical Volume in der Kyma Umgebung gespeichert und können manuell als Zip-gepackte Yaml-Dateien runter- und hochgeladen werden.
Bitbucket wird als Repository für die Superset-Dateien und HANA-Datenstrukturen genutzt. Jenkins greift auf die Daten im Repository zu und kümmert sich um den automatisierten Build und Deploy in die Produktivumgebung.
Die folgenden Prozessschritte müssen dabei durchlaufen werden:


Schritt 1: Transport des HANA-Datenmodelle ins Git
Da das HANA-Datenmodell innerhalb des Business Application Studio entwickelt wird, gibt es mehrere Möglichkeiten, das Modell ins Git zu transportieren. Innerhalb der GUI kann man über das Source Control Symbol im Activity Bar die Dateien in ein Repository pushen oder alternativ diese Schritte in einem Terminal Fenster durchführen. Weitere Informationen gibt es in der SAP Dokumentation zum Business Application Studio.
Schritt 2: Build des Datenmodells
Wenn der Code für das Datenmodell in die Produktivumgebung geschoben werden soll, ergibt die Erstellung eines Containers zum Deployen Sinn. Zuerst muss Jenkins die Daten von GIT in den Container transportieren. In dessen Umgebung werden nacheinander mit Hilfe von Jenkins alle Schritte zum Deployment von Multi Target Applikationen automatisiert und gekapselt durchgeführt.
Schritt 3: Transport der Dashboards ins Git
Es gibt 3 Möglichkeiten mit individuellen Vor- und Nachteilen, Superset Dashboards in das Repository zu überführen.
- Manueller Export von bestimmten Dasboards in der Superset GUI: Das Ergebnis ist eine Zip-Datei, die aus den Charts, den zugrundeliegenden Datensätzen und Datenbanken sowie Metadaten als Yaml-Dateien besteht. Diese Dateien können in das Bitbucket gepusht werden.
Vorteil: Präzise Steuerbarkeit, welche Dasboards exportiert werden sollen
Nachteil: Vergleichsweise hoher manueller Aufwand - Export aller Dashboards im Superset Container über den Befehl ’superset export-dashboards’: Ergebnis ist die gleiche Zip-Datei, die in diesem Fall aber alle Dashboards beinhaltet. Auch diese Zip-Datei kann in das Bitbucket gepusht werden. Bei diesem Schritt werden damit zwar alle Dashboards (auch Dashboards in Entwicklung) in die Produktiv-Umgebung deployt, innerhalb der Umgebung lässt sich aber trotzdem über die Zugriffsberechtigungen steuern, ob User jeweils überhaupt auf ein Dashboard zugreifen dürfen.
Vorteil: Automatisierung der Schritte mit Hilfe von Jenkins und einem Container möglich
Nachteil: Zwingende Anmeldung und Export der Dateien aus dem Container - Export aller Dashboards über Superset REST API: Der Export über die REST API bietet Ähnlichkeiten zum ‘superset export-dashboards‘ Befehl, wobei die Anmeldung im Container entfällt.
Vorteil: Automatisierung der Schritte mit Hilfe von Jenkins und einem Container möglich
Schritt 4: Transport der Dashboards aus dem Git in die Produktivumgebung
Wie beim Export der Dashboards aus Superset gibt es auch beim Import drei Möglichkeiten mit gleichen Vor- und Nachteilen.
- Manueller Import von bestimmten Dasboards in der Superset GUI: Eine Zip-Datei wird importiert, die aus den Charts, den zugrundeliegenden Datensätzen und Datenbanken sowie Metadaten als Yaml-Dateien besteht.
Vorteil: Präzise Steuerbarkeit, welche Dasboards importiert werden sollen
Nachteil: Vergleichsweise hoher manueller Aufwand - Import aller Dashboards im Superset Container über den Befehl ’superset import-dashboards’: Eine Zip-Datei mit gleichem Aufbau wird importiert, die in diesem Fall aber alle Dashboards beinhaltet. Bei diesem Schritt werden damit zwar alle Dashboards (auch Dashboards in Entwicklung) in die Produktiv-Umgebung deployt, innerhalb der Umgebung lässt sich aber trotzdem über die Zugriffsberechtigungen steuern, ob User jeweils überhaupt auf ein Dashboard zugreifen dürfen.
Vorteil: Automatisierung der Schritte mit Hilfe von Jenkins und einem Container möglich
Nachteil: Zwingende Anmeldung und Import der Dateien aus dem Container - Import aller Dashboards über Superset REST API: Der Import über die REST API bietet Ähnlichkeiten zum ‘superset import-dashboards‘ Befehl, wobei die Anmeldung im Container entfällt.
Vorteil: Automatisierung der Schritte mit Hilfe von Jenkins und einem Container möglich
Fazit
Für einen geregelten CI/CD-Prozess von Dashboards und Datenmodellen aus einer Entwicklungs- in die Produktivumgebung müssen mehrere Herausforderungen gelöst werden. Dazu gehören sowohl die individuellen Transporte der Datenmodelle und Dashboards jeweils als auch die Betrachtung der Abhängigkeiten zwischen beiden Teilen. Dazu benötigt werden Tools zur Versionierung (wie Git) und zur Automatisierung (wie Jenkins).
Im konkreten Beispiel mit Apache Superset und der HANA DB gibt es für die einzelnen Transporte mehrere Möglichkeiten, die sich unter anderem über den Automatisierungs- und Individualierungsgrad charakterisieren. Das bedeutet, dass man auf Basis der eigenen Anforderungen individuelle die Prozessschritte individuell realisieren kann.
Autor: Tristan Beger

KONTAKT
Bernd Themann
Managing Consultant
SAP Information Management


