In dieser Blogserie widmen wir uns dem HANA SQL Data Warehouse als offene Plattform. Dieser erste Artikel dient dabei als Orientierung und skizziert zunächst vier zentrale Aspekte, die die Offenheit des SAP HANA SQL Data Warehouse ausmachen.
Sobald die Blogbeiträge veröffentlich wurden, können Sie diese hier aufrufen. Über die Veröffentlichung informieren wir Sie über unseren Newsletter sowie die sozialen Netzwerke. Im Folgenden finden Sie eine Vorschau zu jedem Blogbeitrag, die kurz zusammenfasst, was Sie erwartet.
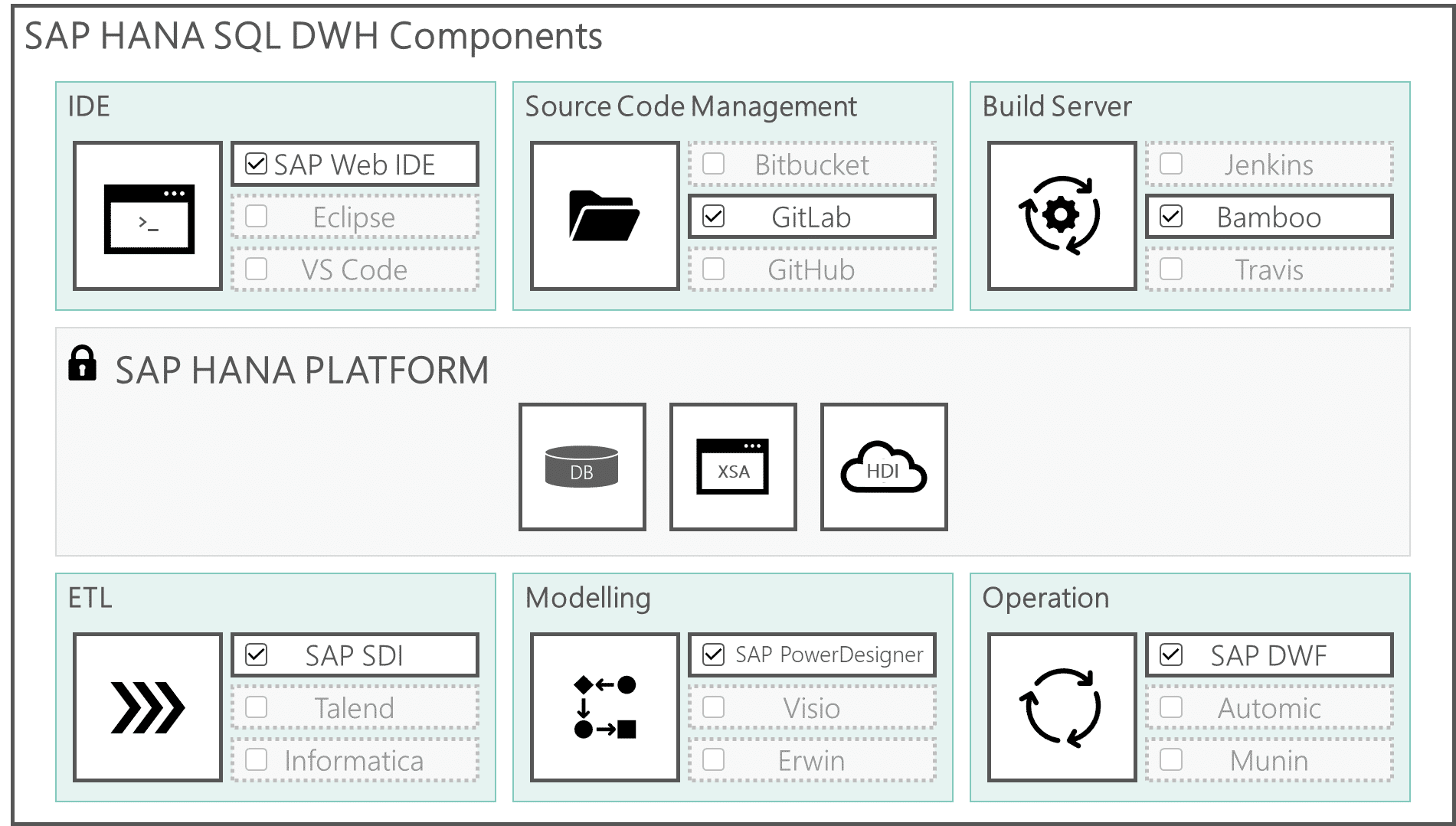
Vorschau zu Blogbeitrag 1: Generelle Austauschbarkeit von Komponenten
Das SAP HANA SQL Data Warehouse basiert, wie bereits der Name impliziert, auf der SAP–HANA–Plattform. Diese Plattform bietet “von Werk” aus ein DBMS, einen Applikationsserver sowie eine Transportinfrakstruktur und weitere nützliche Werkzeuge an, die für die Entwicklung und den Betrieb des DWH genutzt werden können.
Neben SAP proprietärer Software stehen auch viele Open-Source-Werkzeuge zur Verfügung, die sich integrieren lassen. Nahezu alle Komponenten sind dabei grundsätzlich austauschbar.
In diesem Blogbeitrag werden wir die generelle Austauschbarkeit dieser Komponenten genauer unter die Lupe nehmen sowie Vor- und Nachteile bestimmter Komponenten aufzeigen: Hier geht es zum Artikel.
Vorschau zu Blogbeitrag 2: Modellierungsfreiheit
In Bezug auf Datemodelle gibt es beim SAP HANA SQL Data Warehouse keinerlei Vorgaben oder Limitierungen. Ganz im Gegenteil. Der Modellierer kann vollkommen selbst entscheiden welche Informationen das Modell beinhaltet und ist nicht abhängig von vordefinierten Informationsgerüsten.
Ebenfalls kann er selbst wählen, welche Modellierungstechnik (z.B. dritte Normalform, Sternschema, Data Vault, etc.) er anwenden möchte.
In diesem Blogbeitrag werden wir den Aspekt der Modellierungsfreiheit des SAP HANA SQL Data Warehouse näher betrachten und genauer auf bestimmte Modellierungstechniken eingehen. Das Hauptaugenmerk werden wir dabei der Data-Vault-Methodik schenken. Der Beitrag wird am 03.11.2020 veröffentlicht.
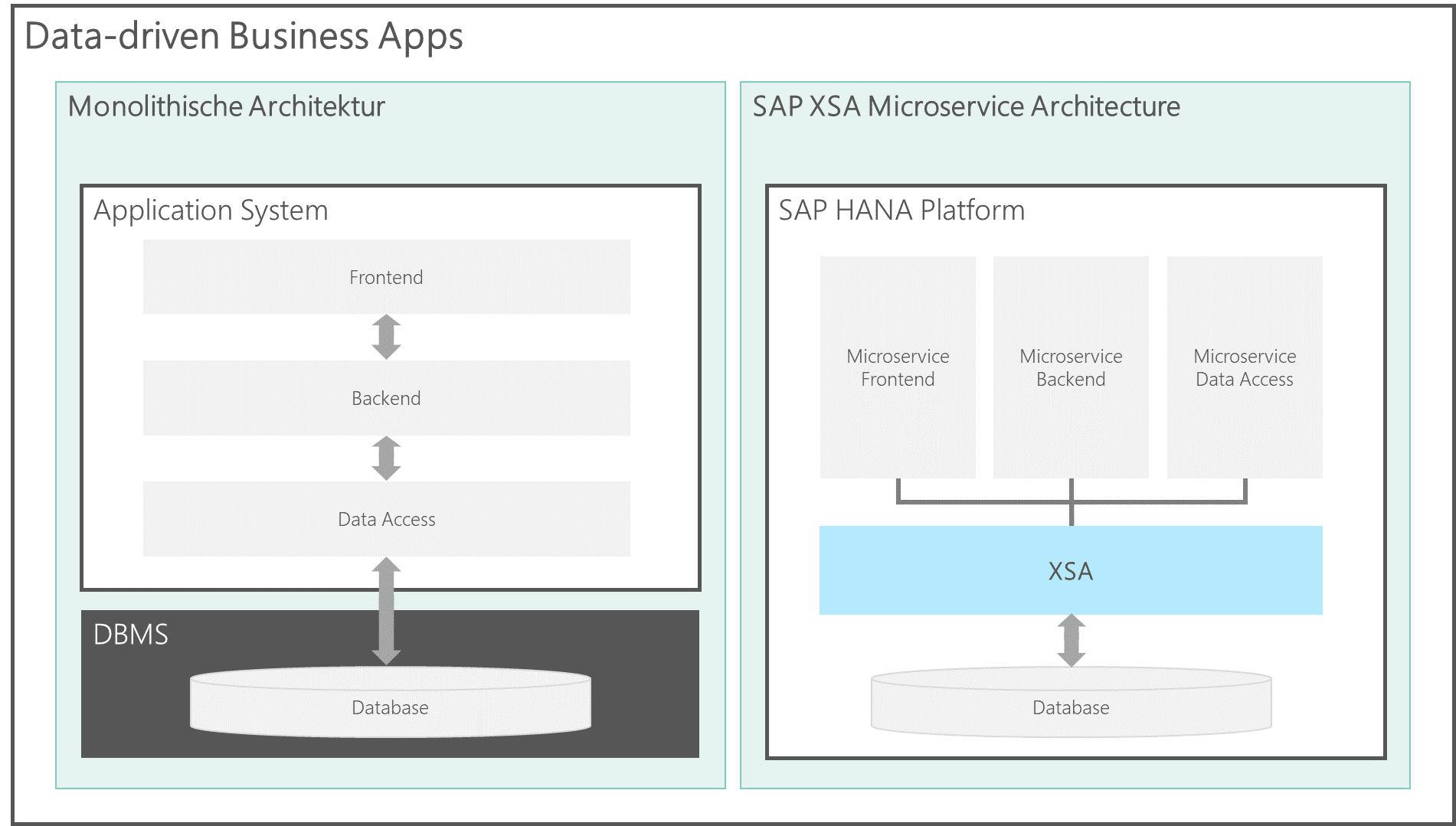
Vorschau zu Blogbeitrag 3: Data-driven business apps
Wie schon in Blogbeitrag 1 (Generelle Austauschbarkeit von Komponenten) erwähnt, basiert das SAP HANA SQL DWH auf der SAP-HANA-Plattform. Technisch baut diese Plattform auf einer microservice-basierten Cloud-Architektur (CloudFoundry) auf.
Diese Architektur ermöglicht es, vollständige Full-Stack-Applikationen auf ein und derselben Plattform zu entwickeln und zu betreiben. Da sich in diesen Applikationen Frontend, Backend und Datenbank eine Plattform teilen weisen Sie eine hohe Performance auf – gerade bei der Verarbeitung von großen Datenmengen.
Unter dem Stichwort “Data-driven Business Apps” zeigen wir Ihnen in diesem Blogbeitrag, wie Sie individuelle und performante Applikationen auf der SAP-HANA-Plattform entwickeln, die unmittelbar auf die Datenpersistenz des SAP HANA SQL Data Warehouse zugreifen. Der Beitrag wird am 29.12.2020 veröffentlicht.
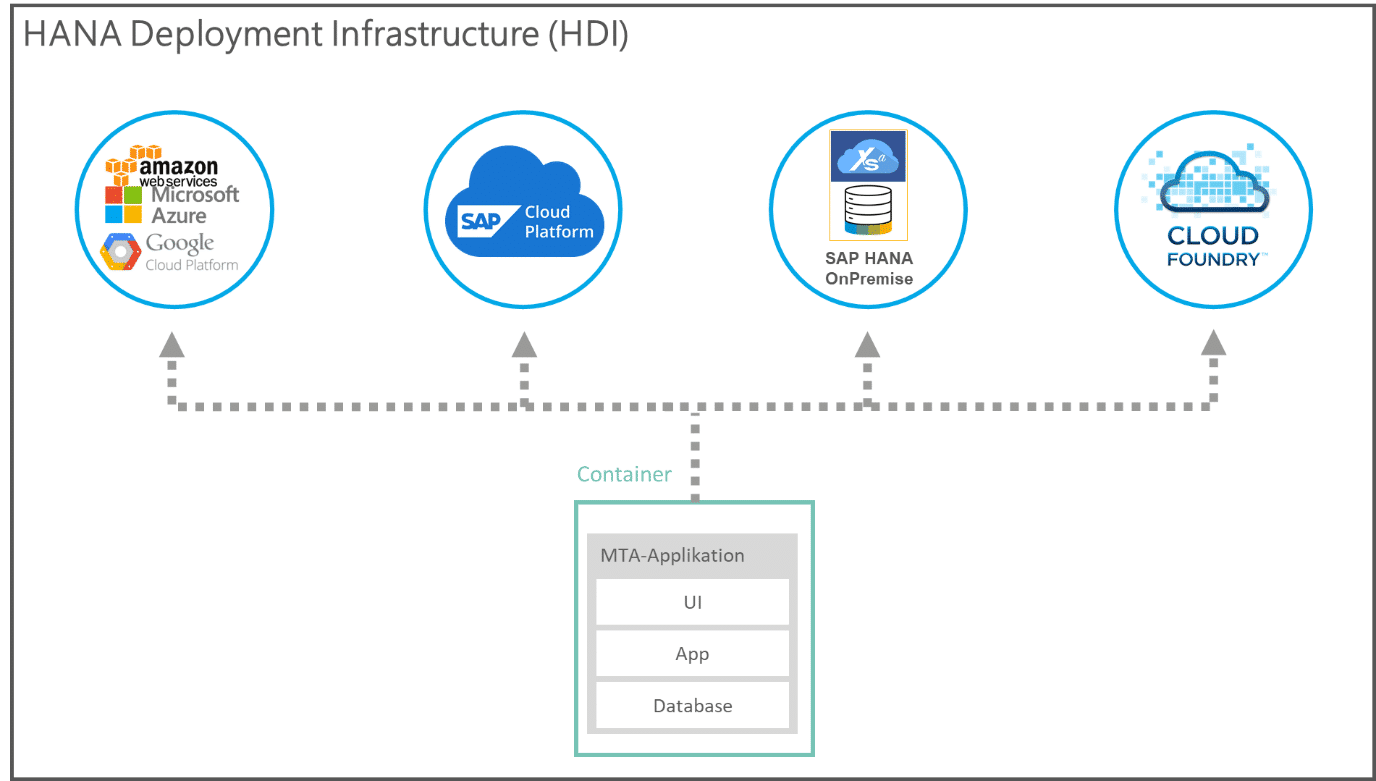
Vorschau zu Blogbeitrag 4: Deploymentinfrastruktur
Ein weiterer Aspekt, in dem das SAP HANA SQL Data Warehouse sich durch besondere Offenheit auszeichnet, ist die Deploymentinfrastruktur, die sich durch den technischen Aufbau der SAP-HANA-Plattform ergibt.
Die SAP HANA Deployment Infrastructure (HDI) ermöglicht es, Objekte in sogenannte Container zu deployen. Diese Container können neben Datenbankobjekten auch komplette (MTA-)Applikationen beinhalten. Mit der SAP HDI besteht die Möglichkeit konventionell auf ein SAP HANA XSA- oder Cloud Foundry-System on-premise zu deployen oder das Deployment in die Cloud zu verlagern. Hierbei steht eine Vielzahl möglicher Deploymentoptionen zur Verfügung.
In diesem Blogbeitrag beleuchten wir die HANA Deployment Infrastructure im Zusammenhang mit der XSA/Cloud Foundry-Architektur und zeigen auf, wie sich die HDI auf die Offenheit des SAP HANA SQL Data Warehouse auswirkt. Dabei werfen wir auch einen gesonderten Blick auf Multi-Target-Applikationen (MTA) und Ihre Bedeutung für das Deployment.
Wir agieren seit 1993 als IT-Berater für Data Analytics und Dokumentenlogistik und fokussieren uns auf das Datenmanagement und die Automatisierung von Prozessen. Ganzheitlich und im Rahmen eines umfassenden Enterprise Information Managements (EIM) begleiten wir von der strategischen IT-Beratung über konkrete Implementierungen und Lösungen bis hin zum IT-Betrieb. ISR ist Teil der CENIT EIM-Gruppe.