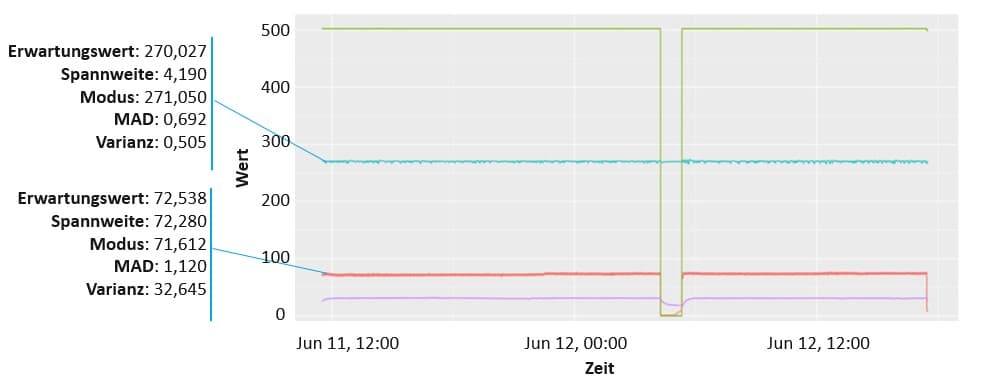
Interquartilsabstand
Bei der Interquartilsmethode wird ein Bereich bzw. eine Range um den Median der Stichprobenmenge herum definiert. Alle Beobachtungen außerhalb dieser Range werden als Ausreißer identifiziert.
GESD (Generlized Extreme Studentized Deviate Test)
Es werden Hypothesentests anhand folgender Teststatistik durchgeführt ![]() , wobei x_Strich das und sigma die Standardabweichung der Stichprobe darstellt.
, wobei x_Strich das und sigma die Standardabweichung der Stichprobe darstellt.
Die Nullhypothese ist, dass keine Ausreißer im Datensatz vorliegen. Die Alternativhypothese lautet, dass bis zu r Ausreißer vorliegen. Es werden r Tests durchgeführt, solange die Teststatistik über einen kritischen Wert liegt. Dabei wird nach jedem Test der Datenpunkt mit dem größten Abstand zum arithmetischen Mittel aus der Datenmenge als erkannter Ausreißer entfernt und die Teststatistik neu berechnet.
Dbscan
Dbscan ist ein Clustering Verfahren, dass Cluster auf Basis der Dichte ermittelt. Ein Punkt wird als dicht bezeichnet, wenn sich mindestens MinPts Punkte in einer Umgebung mit Radius ɛ um den Punkt herum befinden. Zur Ermittlung des Abstands zwischen Punkten existieren diverse Metriken, wie z.B. die Euklidische Metrik, die verwendet werden können.
Das Verfahren unterscheidet drei Arten von Punkten. Die erste Art von Punkten sind Kernpunkte. Dieses sind Punkte, die dicht sind. Die zweite Art sind dichte-erreichbare Punkte. Diese sind Punkte, deren e-Umgebung weniger als MinPt Punkte enthält, jedoch von einem Kernobjekt des Clusters erreichbar sind. Mit erreichbar ist gemeint, dass der Abstand zwischen zwei Punkten kleiner als e ist. Als drittes existieren Ausreißer. Diese sind Punkte, die nicht dichte-erreichbar sind von anderen Punkten.
Ein Cluster wird folgendermaßen charakterisiert: Alle Punkte des Clusters sind dichte-verbunden. Zwei Punkte werden als dichte-verbunden bezeichnet, wenn es einen Punkt gibt, von dem die beiden Punkte dichte-erreichbar sind. Ist ein Punkt dichte-erreichbar von einem beliebigen Punkt des Clusters, so ist dieser Punkt Teil des Clusters. Somit werden mittels dieses Verfahrens Ausreißer als eigenständige, nicht dichte Cluster identifiziert.
Isolation Forests
Dieses Verfahren basiert auf binären Entscheidungsbäumen. Zum Trainieren eines Entscheidungsbaumes, wird ein Feature willkürlich ausgewählt und eine willkürliche Trennung anhand einer Wert-Ausprägung dieses Features durchgeführt.
Der Isolation Forest ergibt sich dann aus der Kombination aller Isolationsbäume, sodass der Durchschnitt ihrer Ergebnisse verwendet wird.
Jede Beobachtung wird in einem Knoten mit dem Isolationswert verglichen. Die Anzahl der Isolationen wird Pfadlänge genannt. Die Annahme ist, dass Ausreißer kürzere Pfadlängen aufweisen als normale Beobachtungen.
Der Ausreißer-Score wird dann wie folgt bestimmt 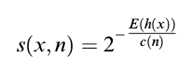 , wobei h(x) die Pfadlänge von Beobachtung x, c(n) die maximale Pfadlänge des Baumes und n die Anzahl der Knoten des Baumes sind. Der Wert liegt zwischen 0 und 1. Je höher der Wert ist, desto wahrscheinlicher handelt es sich bei der Beobachtung um einen Ausreißer.
, wobei h(x) die Pfadlänge von Beobachtung x, c(n) die maximale Pfadlänge des Baumes und n die Anzahl der Knoten des Baumes sind. Der Wert liegt zwischen 0 und 1. Je höher der Wert ist, desto wahrscheinlicher handelt es sich bei der Beobachtung um einen Ausreißer.
K-Nearest Neighbour
Mithilfe des K-Nearest Neighbour Algorithmus lassen sich auch Anomalien identifizieren. Dabei ist die Distanz eines Datenpunkts zum k nächsten Nachbar das Maß für den Ausreißer Score.