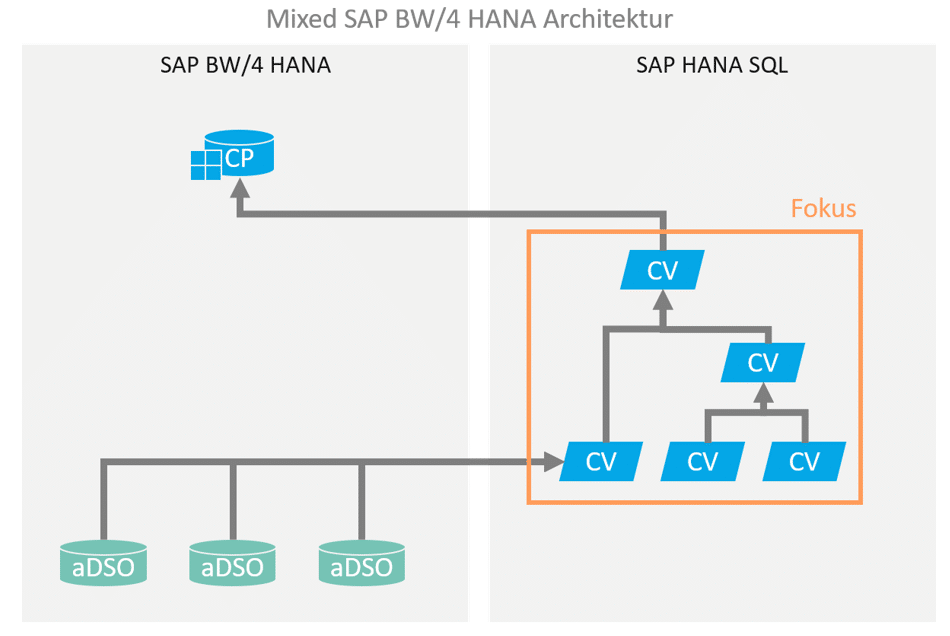
Bei der hybriden oder auch mixed Modellierung eines SAPDie SAP SE mit Sitz im baden-württembergischen Walldorf ist ein… More BW basierten Data Warehouses werden Teile der Datenmodellierung über HANA SQL / native Mittel durchgeführt. Die Modellierung wird dabei in den meisten Fällen durch HANA Calculation Views durchgeführt.
Daher ist es sehr wichtig die Funktionsweisen von HANA Calucation Views zu verstehen, um sie korrekt in ein SAP BW getriebenes Data WarehouseEin Data Warehouse ist für die Ausführung, Überwachung und Steuerung… More zu integrieren. Die meisten SAP BW Entwickler haben langjähriges ABAP Know-how. Die Entwicklung und damit einher gehend auch das Debuggen von ABAP Programmen ist bekannt. In hybriden Datenmodellen verliert das ABAP Wissen jedoch an Bedeutung, wenn Datenflüsse mit Hilfe von Calculation Views virtualisiert worden sind. In diesem Beitrag möchten wir daher eine Hilfestellung dazu geben, wie Calculation Views in Eclipse debuggt werden können.
Debugging DataPreview
Ein grafischer Calculation View kann komplexe Operationen wie beispielweise das Joinen von verschiedenen Tabellen, Views oder sogar anderen Calculation Views abbilden. Die zentralen Entwicklungselemente des Calculation Views werden als Nodes bezeichnet und untergliedern sich in JOIN, Union, Projection, Aggreagtion und Rank-Node. Komplexe Szenarien können schnell mehrere Nodes umfassen und erreichen somit Dimensionen, in welchen eine strukturierte Fehleranalyse unerlässlich wird. Zu diesem Zweck wollen wir uns in diesem Blogbeitrag anschauen welche Möglichkeiten uns die DataPreview im HANA-Studio zur Analyse beziehungsweise Debuggings eines Calculation Views bietet.
Szenario
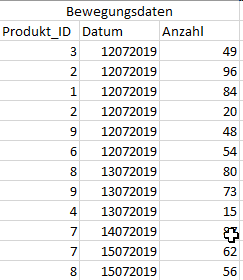
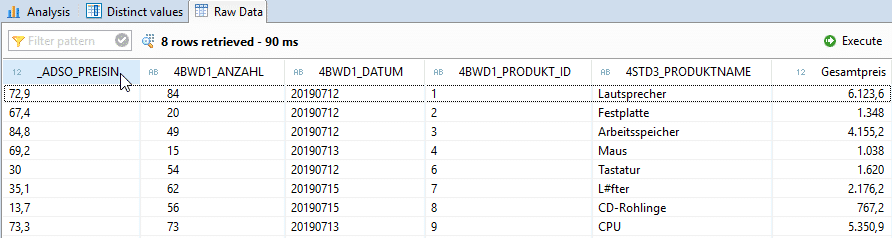
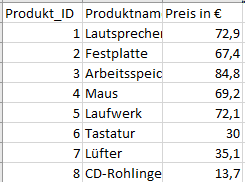
Ein klassischer Fall eines Joins im SAP-BW4/HANA Umfeld ist die Anreicherung von Bewegungsdaten um Stammdaten. Als Beispiel nehmen wir den Verkauf von Produkten zu einem bestimmten Datum und die verkaufte Menge.
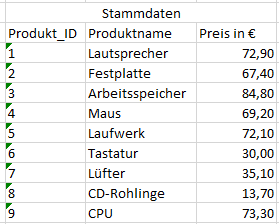
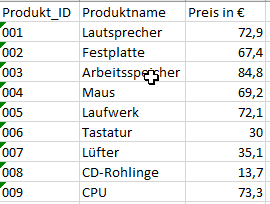
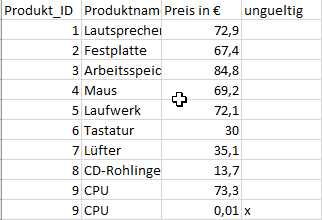
Diesen Datensatz erweitern wir um die Stammdaten der Produkte, welche die Produkt-Texte und -Preise beinhalten.
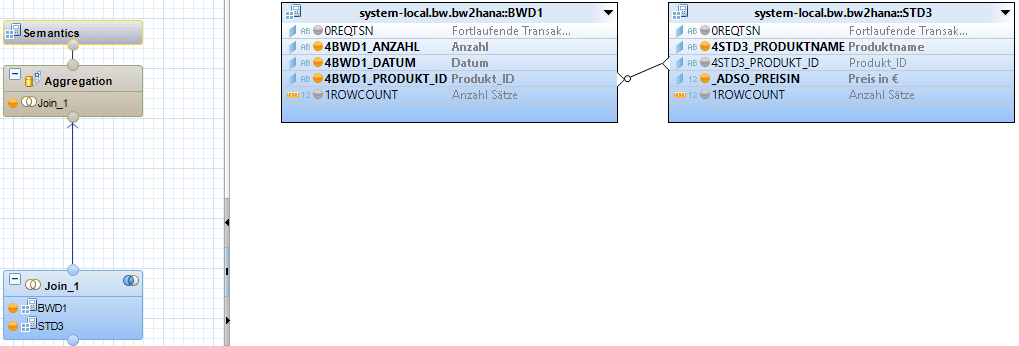
Die Umsetzung in einem Calculation View könnte folgendermaßen aussehen.
Die DataPreview
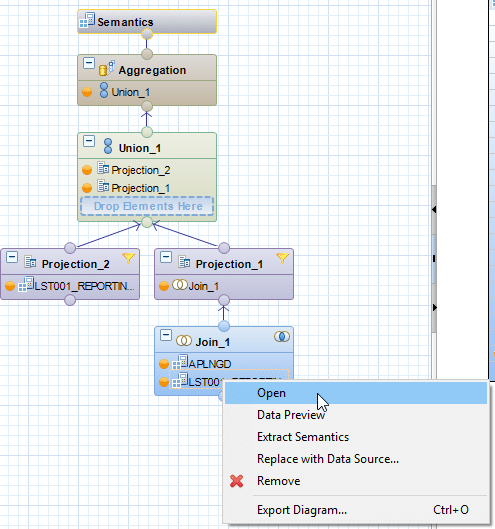
Generell lässt sich die Data Preview entweder auf einem Calculation View anwenden oder direkt auf einem der zugrunde liegenden Nodes (Aggregation, Projection, Rank, Join) oder DataSource.
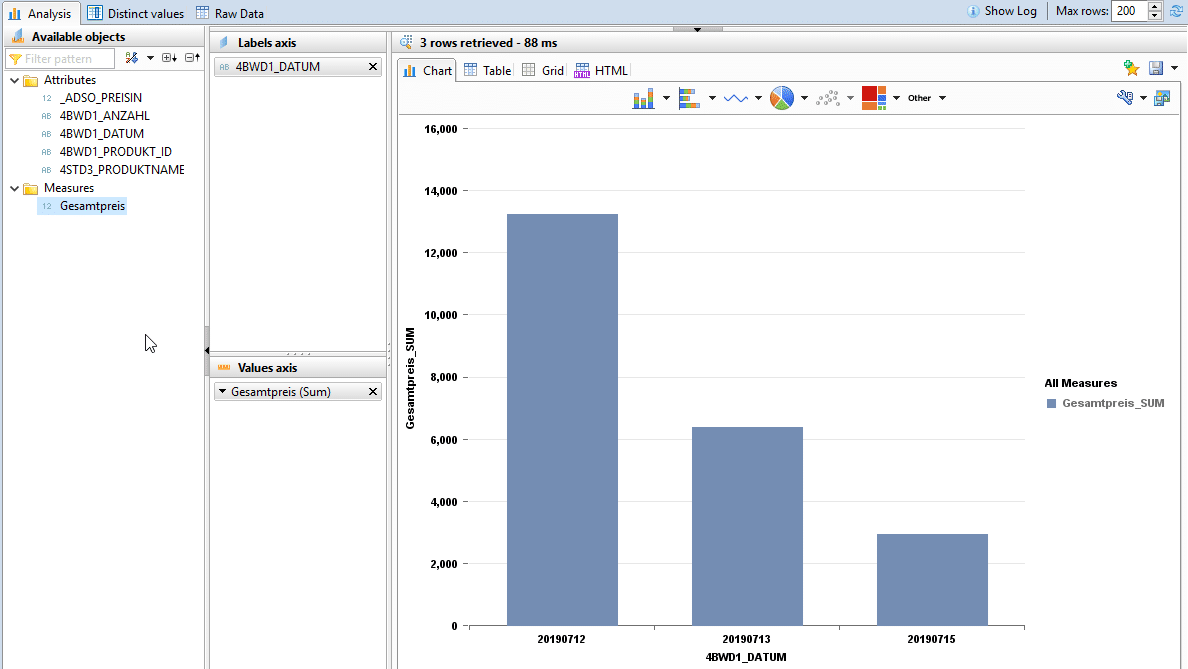
Die DataPreview ermöglicht dem Entwickler drei verschiedene Sichten auf die Daten.
1) Mittels der Analysis-Sicht lassen sich erste einfache Analysen und grafische Darstellungen realisieren.
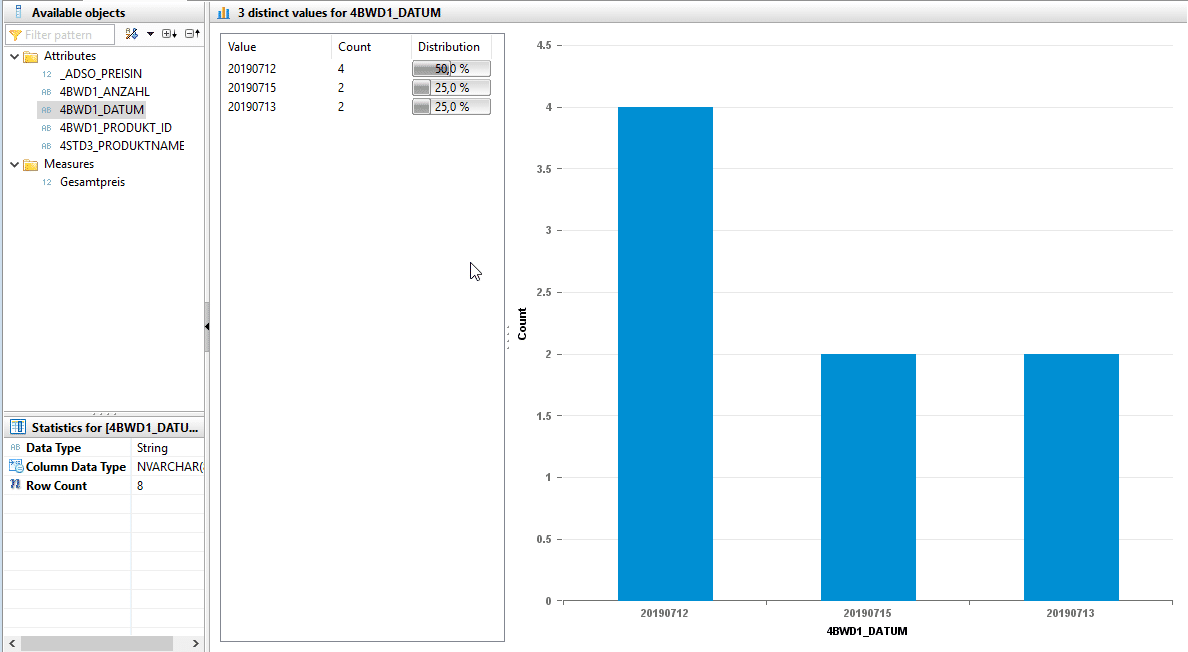
2) Die Distinct Value-Sicht ermöglicht eine Sicht auf die verschiedenen Ausprägungen eines Attributes.
3) Die Raw-Data-Sicht bietet einen Blick auf die Rohdaten.
Beispiel Testfälle
Um die Möglichkeiten des Debuggings mittels Data Preview zu verdeutlichen, wurden folgende Testfälle aufgestellt und angepasste inkorrekte-Datensets bereitgestellt.
1. Test erfolgreicher JOIN (NULL-Test)
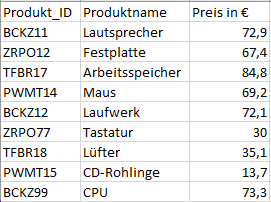
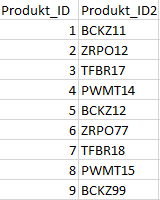
Das Datenset beinhaltet Produkt_IDs, welche ein anderes Datenformat, als die Produkt_IDs der Bewegungsdaten aufweist.
Das Datenset beinhaltet Produkt_IDs, welche zu den Produkt_IDs der Bewegungsdaten heterogene Stammdaten aufweist.
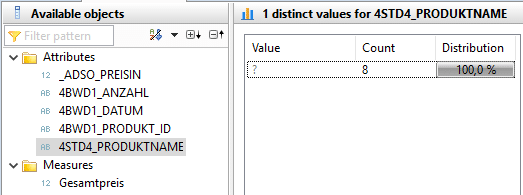
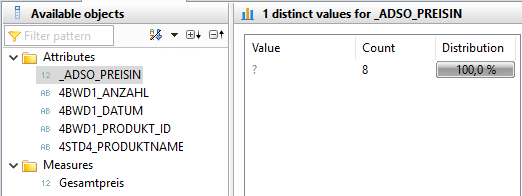
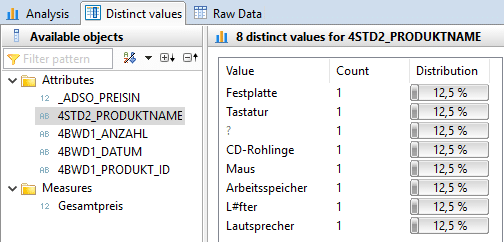
Um zu testen, ob der JOIN mit den Stammdaten der Produkte erfolgreich durchgeführt wurde, bietet sich die Sicht auf die Distinct Values des Produktnamen an.
Es ist erkennbar, dass die Bewegungsdaten durch den Join nicht um die entsprechenden Produktnamen angereichert wurden. Ebenfalls fehlen die Preisinformationen. Dies ist auf die Heterogenität der Produkt_ID zwischen dem Datenset der Bewegungsdaten und Stammdaten zurückzuführen. Um diesen Sachverhalt zu ändern, bedarf es einer Stammdatenharmonisierung. Im Falle der unterschiedlichen Datenformate ist eine Datenformatsanpassung zu empfehlen. Sollten die Stammdaten syntaktisch abweichen, bedarf es einer Übersetzungstabelle, um einen Join zu ermöglichen.
2. Test richtige Kardinalität
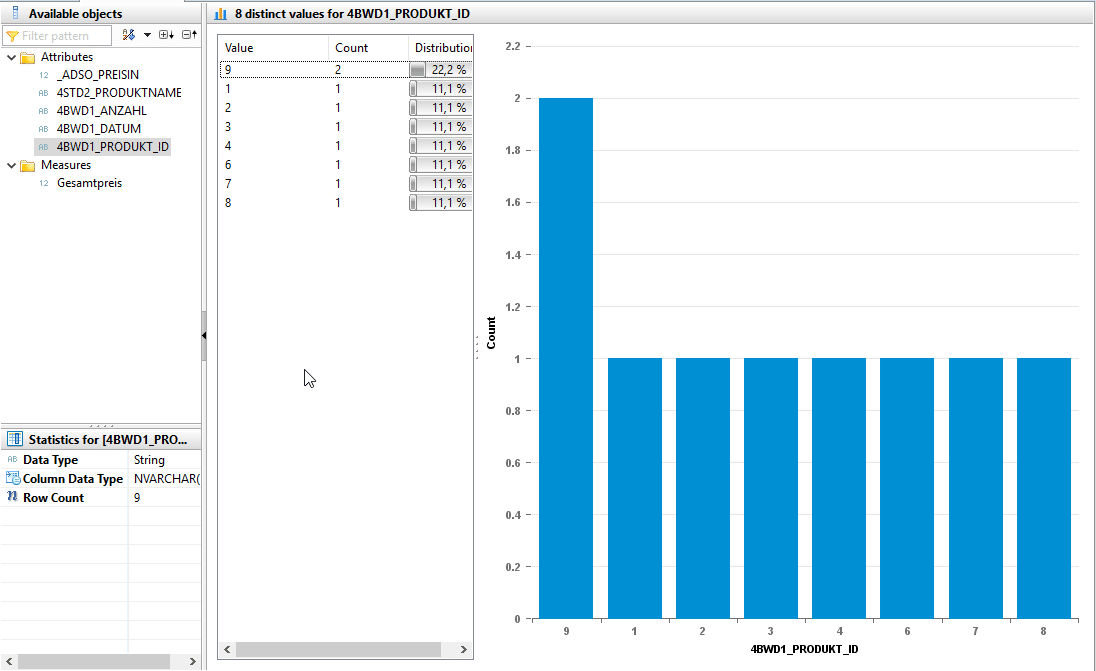
Das Datenset beinhaltet zwei Datensätze mit der Produkt_ID 9.
Mittels der Distinct Values sicht lassen sich ebenfalls die Kardinalitäten untersuchen. Bei der Anreicherung mit Stammdaten erwarten wir eine Kardinalität von 1:1. Anhand der untenstehenden Auswertung, lässt sich allerdings feststellen, dass eine Datenvervielfachung stattgefunden hat. Statt der zu erwarteten 8 Produkt-IDs (1-9) werden auf Grund der doppelten 9’er Produkt_ID 9 Datensätze ausgegeben. Dies ist auf die zweit ungültige Produkt_ID (9) zurückzuführen, welche vor dem JOIN ausgefiltert werden muss.
3. Test vollständige Stammdaten
Der Datensatz mit der Produkt_ID 9 fehlt im Gegensatz zum “Originaldatenset”.
Für den Test, ob im Datenset der Stammdaten sämtliche Produkt_IDs vorliegen, lässt sich ebenfalls die Distinct Value- Sicht nutzen. Es wird ersichtlich, dass die Stammdaten für die Produkt_ID “9” in den Rohdaten nicht vorliegen und somit ergänzt werden müssten.
Analyse Calculation Views
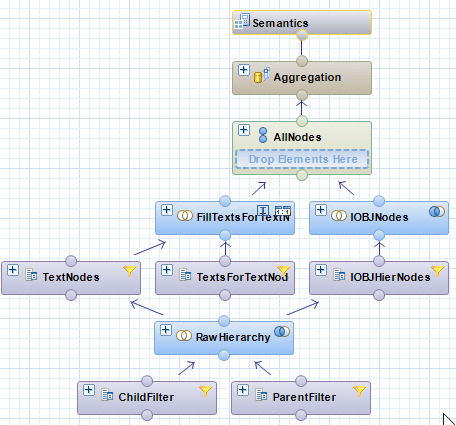
Calculation Views werden verwendet um andere Analytic, Attribute und oder Calculation Views und column tables zu konsumieren. In echten Business Anwendungen lassen sich somit komplexe Szenarien abbilden. Um einzelne Calculation Views nicht zu “überfrachten” besteht die Möglichkeit Calculation Views zu schachteln und somit Logik zu kapseln. Der Calculation View bietet allerdings trotzdem die Möglichkeit eines “Blicks” in den zugrunde liegenden bzw. gekapselten Calculation Views.
In unserem Beispiel handelt es sich um die Reporting-Hierarchy_View eines InfoObjectsInfoObjects sind betriebswirtschaftliche Auswertungsobjekte, welche sich in Merkmale, Kennzahlen, Einheiten,….
Debugging Debugger
Calculation Views lassen sich ebenfalls mittels eines dedizierten Debuggers untersuchen. Dieser lässt sich nach Aktivierung des Calculation Views etwas versteckt über ein Drop-Down-Menü öffnen.
Weitere Informationen
Die Nutzung der Debugging-Funktion setzt einige zusätzliche (HANA-seitige) Berechtigungen voraus, u.a. die Rollen CATALOG READ und DATA ADMIN, sowie SELECT-Berechtigungen im Schema _SYS_REPO, da hier die Laufzeitobjekte der Calculation Views erzeugt werden.
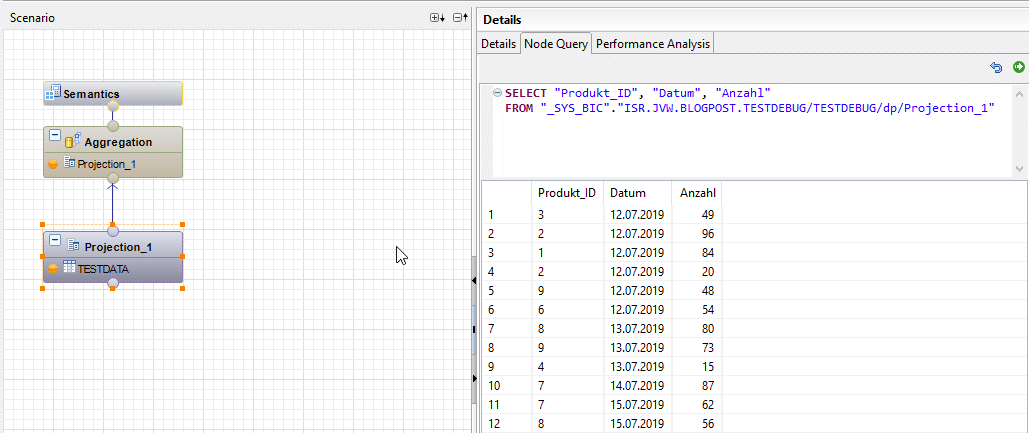
Anschließend schlägt der Debugger automatisiert eine Debugging-Query vor. Diese kann entweder übernommen oder nach eigenen Vorstellungen angepasst werden.
Die Calculation View öffnet sich anschließend im Read-Only Modus.
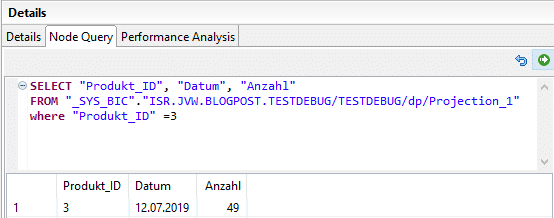
Die Hauptfunktionalität des Debuggers besteht in der Auflösung jeder einzelnen Node in eine entsprechende SQL Query. Die Query der obersten Node entspricht hierbei unserer Debugging-Query, welche wir im Vorhinein definiert haben. Zusätzlich zur übersetzen SQL Query liefert uns der Debugger eine DataPreview auf das Ergebnis der einzelnen Node. Im Gegensatz zur Analyse mit der DataPreview handelt es sich hierbei um kein statisches Ergebnis. Der Debugger bietet die Möglichkeit die Query auf jeder einzelnen Node “on-the-fly” anzupassen und somit das Ergebnis jeder einzelnen Zwischenberechnung zu beeinflussen.
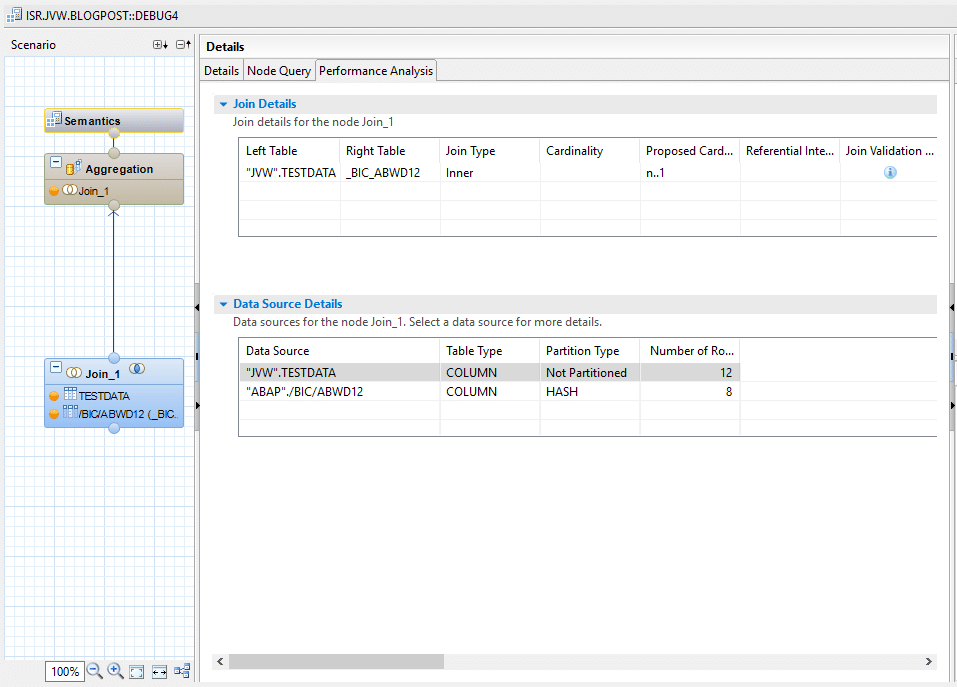
Zusätzlich zu den Query-Informationen bietet der Debugger eine Performanceübersicht mit grundlegenden Informationen zu den einzelnen Data-Sources und gegebenenfalls Informationen zum verwendeten Join. Diese Informationen werden allerdings nur bei HANA-Tabellen angezeigt.
Fazit
In diesem Blogbeitrag wurden die zwei unterschiedlichen technischen Möglichkeiten & unterschiedliche Herangehensweisen zum Debugging von Calculation Views dargestellt. Letztendlich lässt sich festhalten, dass mit der DataPreview & dem Debugger die gleichen Probleme auf unterschiedliche Art lösbar sind.
Man kann jedoch empfehlen den Debugger in den ersten Entwicklungsschritten einer Calculation View zu nutzen & die Datapreview erst im späteren Verlauf einzusetzen. In frühen Entwicklungsphasen kann der Debugger eindeutig seine Stärke der flexiblen Query-Modellierung ausspielen, wo bei der DataPreview vorher eine Anpassung der Calculation View notwendig wäre.
In späteren Entwicklungsphasen kann die DataPreview allerdings ihre Stärken der Datenanalyse ausspielen, welche beim Debugger nicht gegeben ist.
Wir agieren seit 1993 als IT-Berater für Data Analytics und Dokumentenlogistik und fokussieren uns auf das Datenmanagement und die Automatisierung von Prozessen. Ganzheitlich und im Rahmen eines umfassenden Enterprise Information Managements (EIM) begleiten wir von der strategischen IT-Beratung über konkrete Implementierungen und Lösungen bis hin zum IT-Betrieb. ISR ist Teil der CENIT EIM-Gruppe.