Auch heute ist das Thema Data Warehouse immer noch in Bewegung. Neue Technologien und wirtschaftliche Rahmenbedingungen erfordern Anpassungen, die, in die Jahre gekommene, Lösungen nicht unbedingt leisten können.
Sich einen Überblick über das breite Angebot moderner Data-Warehouse-Lösungen zu verschaffen ist jedoch keine leichte Aufgabe. In diesem Blog wollen wir Ihnen das SAP HANA SQL Data Warehousing vorstellen und die Frage klären, was diesen DWH-Ansatz gegenwärtig zu einer attraktiven Lösung macht. Dazu erläutern wir die wesentlichen Elemente und Vorteile des SAP HANA SQL Data Warehousing vor und liefern Argumente aus der Praxis, die für den nativen SQL-Data-Warehousing Ansatz auf Basis der SAP-HANA-Plattform sprechen.
Das SAP HANA SQL Data Warehousing
Das SAP HANA SQL Data Warehousing beruht auf der Idee, die SQL-basierenden Werkzeuge der SAP-HANA-Plattform zum Aufbau eines in dem Sinne nativen SAP-HANA-Data-Warehouse zu nutzen. Da die graphischen Werkzeuge und Editoren SQL erzeugen und jegliche Kommunikation mit der SAP-HANA-Datenbank letztlich in SQL erfolgt, ergibt sich die Beschreibung als SQL-Data-Warehousing-Ansatz. Darüber hinaus liegt in dieser Eigenschaft eine der großen Stärken des Produktes. SQL ist die universelle Sprache der, trotz des Rummels um Big Data und NoSQL, immer noch führenden relationalen Datenbankmanagementsysteme (RDBMS). SQL, als lingua franca der Datenwelt, macht die Lösung in vielen Belangen flexibel und ermöglicht eine weitgehende Systemoffenheit, die in den gegenwärtigen Zeiten des disruptiven technologischen Fortschritts und der zunehmenden Dynamik des Geschäftslebens, einen Wettbewerbsvorteil verspricht. Dies gilt gleichwohl vor allem im Zusammenspiel mit weiteren Eigenschaften der SAP-HANA-Plattform, die wir nachfolgend im Überblick beschreiben.

Einbettung in die SAP-HANA-Plattform
Datenmanagement
Das Datenmanagement ist in der jüngeren Vergangenheit insbesondere vom Begriff „Big Data“ geprägt, der die heute zumeist gegebenen Eigenschaften eines großen Datenvolumens, einer großen Datenvielfalt und der Schnelligkeit der Datenproduktion bzw. Verarbeitung betont (Volume, Variety, Velocity). Die In-Memory-Technologie der SAP-HANA-Datenbank sowie umfassende Schnittstellen stellen das SAP HANA SQL Data Warehousing hier gut auf. So ist es möglich, über verschiedene Konnektoren nahezu jede Datenquelle anzubinden und den Datenzugriff vollständig zu virtualisieren.
Advanced Analytics
Advanced Analytics ist ein Feld, das in den letzten 10 Jahren stark an Bedeutung gewonnen hat. Im Vergleich zur üblichen Business-Intelligence-Ansätzen unterscheiden sich entsprechende Maßnahmen durch ihren Schwerpunkt auf der Vorhersage („predictive“) spezifischer Ereignisse und nicht nur der rückwärtsgewandten Beurteilung. Die SAP-HANA-Plattform bietet den Vorteil, dass sie entsprechende Analytics Engines bereits voll integriert mitbringt, so dass prädiktive Auswertungen von u.a. Text-, Geo- oder Graphdaten im Rahmen des SAP HANA SQL Data Warehousing sehr leicht möglich sind.
Anwendungsentwicklung
Ein wesentlicher Schritt auf dem Weg der SAP HANA von der Datenbank zur Plattform war die Einführung eines eigenen Anwendungsservers (SAP HANA Extended Application Services – kurz XS). Die grundlegende Idee hinter dieser Entscheidung war es, die übliche 3-Schicht-Softwarearchitektur, in der die Datenbank mehr oder weniger als reiner Datenspeicher fungiert, in eine 2-Schicht-Architektur zu verwandeln. Die Rolle des Anwendungsservers, als zentrales Element zur Ausführung von Berechnungen und Logiken, sollte aufgrund der Leistungsstärke von der SAP-HANA-Datenbank übernommen werden, um so die Performance von Abfragen insgesamt zu erhöhen. Mit SAP HANA Extended Application Services Advanced (SAP HANA XSA) steht seit Ende 2015 die zweite Version dieses Anwendungsservers zur Verfügung, der durch eine Mircoservice-Architektur, die mehrere Laufzeiten unterstützt, eine eigene Entwicklungsumgebung (SAP Web IDE) und die Anbindung der verteilten Quellcodeverwaltung Git die Full-Stack-Entwicklung auf der SAP-HANA-Plattform weiter optimiert. Von diesen Entwicklungsmöglichkeiten profitiert das SAP HANA SQL Data Warehousing sehr stark, da hierdurch auch die Data-Warehouse-Strukturen sehr agil entwickelt werden können (Ausführlich dazu 1.2 Agile DWH-Entwicklung)
Cloud
Für SAP HANA bieten sich viele Optionen für den Betrieb in der Cloud. Neben der Einrichtung in einer selbstverwalteten Cloud, wie beispielsweise Amazon Webservice, in der nur die Infrastruktur zur Verfügung stellt wird (IaaS) gibt es mit SAP Cloud Platform die komplette SAP-HANA-Plattform als Online-Service (PaaS). Das Angebot beruht auf der Open-Source-Technologie Cloud Foundry und unterscheidet sich prinzipiell nicht von der On-Premise-Struktur mit dem Anwendungsserver SAP HANA XSA. Hierdurch ergibt sich eine große Flexibilität im Hinblick auf die Entwicklung verschiedenster Anwendungen, da diese durch die spezifische Containerstruktur der SAP-HANA-Plattform sowohl mit der XSA On-Premise als auch mit Cloud Foundry in der Cloud entwickelt und unkompliziert in der jeweils anderen Umgebung betrieben werden können. Für das SAP HANA SQL Data Warehousing bedeutet dies, dass Sie die DWH-Strukturen und -Objekte zunächst On-Premise entwickeln und anschließend einfach in die Cloud schieben können oder andersherum. Sie genießen also die volle Cloud-Flexibilität.
Agile DWH-Entwicklung
Die guten Voraussetzungen zur agilen Entwicklung des SAP HANA SQL Data Warehouse ergeben sich in gewisser Weise als Abfallprodukt der kontinuierlich verbesserten Anwendungsentwicklung der SAP-HANA-Plattform. Die Funktionen der Entwicklungsumgebung SAP Web IDE bzw. der zugrundeliegenden XSA/Cloud Foundry-Struktur, mit einer Differenzierung von Entwicklungs- und Laufzeitumgebung, der Auslieferung von Entwicklungsartefakten in Containern und die Anbindung der verteilten Quellcodeverwaltung Git, eignen sich hervorragend für einen modellgetriebenen, inkrementellen und iterativen Aufbau eines Data Warehouse. Aufgrund dieser Entwicklungsmöglichkeiten setzt SAP HANA SQL Data Warehousing zentral auf die DevOps-Philosophie und bringt auf diese Weise die Vorteile der agilen Softwareentwicklung in das Data Warehouse.

Verteilte Quellcodeverwaltung in Git
Der Quellcode für die Datenbankartefakte wird in der verteilten Versionsverwaltung (Version Control System – VCS) Git gespeichert. In der Softwareentwicklung ist dieses Vorgehen aufgrund der verbesserten Möglichkeit von parallelen Entwicklungen gängig. In Verbindung mit der Unterscheidung zwischen Entwicklungs- und Laufzeitumgebung und der Containerisierung der Datenbankartefakte birgt es auch für die Entwicklung des SAP HANA SQL Data Warehouse Vorteile bezüglich der Beschleunigung der Entwicklungsprozesse.
Kontinuitätsprozesse
DevOpsWas ist DevOps?Der Begriff DevOps setzt sich aus den Wörtern… Mehr beschreibt zunächst einmal die engere Verzahnung der Bereiche Entwicklung und Betrieb bzw. der Entwicklungs- und Laufzeitumgebung. Möglichst kleine Entwicklungsartefakte sollen diese beiden Bereiche schnell und kontinuierlich durlaufen, um frühzeitig operativen Mehrwert zu schaffen. Neben spezifischen Phasen haben sich daher auch einige Kontinuitätsprozesse etabliert, die dieses Ziel unterstützen (Abbildung 1.1). Continuous Integration beschreibt im Wesentlichen den Vorgang der parallelen Entwicklung mehrerer Personen mithilfe des Git-Repository, bei dem kontinuierlich Quellcode-Bestandteile in das Repository des Gesamtprojektes eingebunden werden. Continuous Delivery verfolgt die kontinuierliche Auslieferung in Produktivsysteme. Auch hier übernimmt das Git-Repository wesentliche Aufgaben und macht automatische Deployments von Entwicklungen des SAP HANA SQL DWH möglich. Wichtig sind dabei auch kontinuierliche und im besten Fall ebenfalls weitgehend automatisierte Tests sowie ein generell möglichst durchgängiges Feedback durch Kommunikation aller Beteiligten Personen.
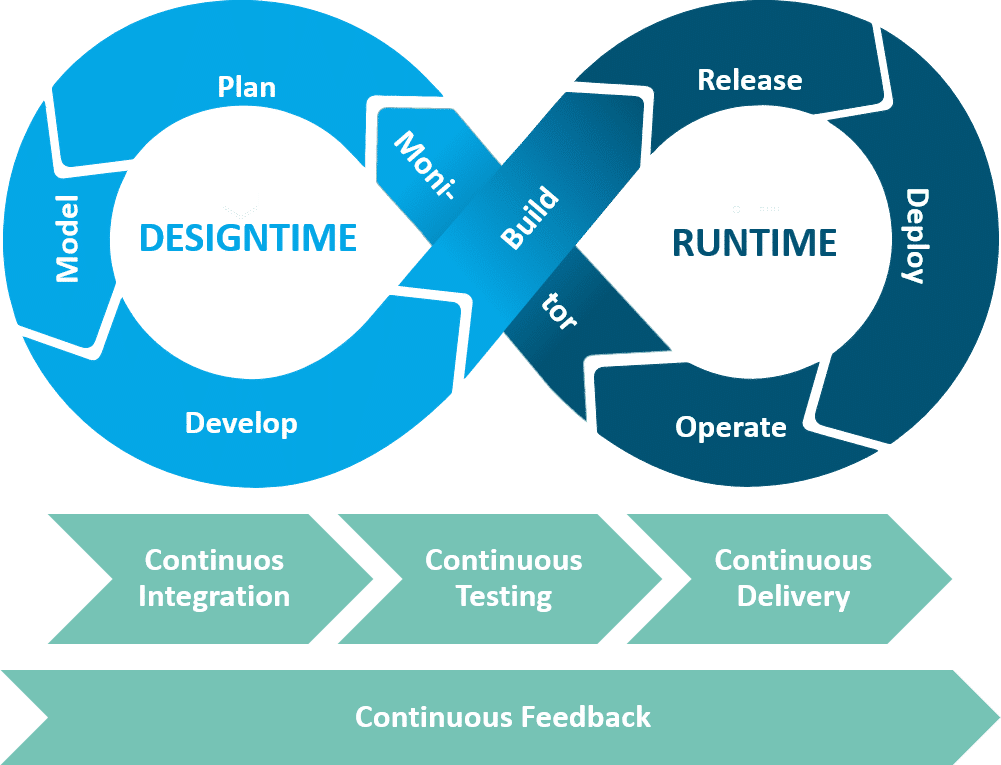
Grafik 01: DevOps-Phasen und Prozesse SAP HANA SQL Data Warehousing
Modellgetriebene Entwicklung
Im SAP HANA SQL Data Warehousing kann die Datenmodellierung nach verschiedenen Formen, wie Dritter Normalform (3NF), Multidimensional oder Data Vault erfolgen. Diese Freiheit erfährt eine immer größere Nachfrage. Speziell die Data-Vault-Modellierung, die wir für das SAP HANA SQL Data Warehousing empfehlen, hat in den letzten Jahren an Bedeutung gewonnen, da sie eine größere Flexibilität gegenüber laufenden Veränderungen des Datenmodells aufweist. Insgesamt stellt die sukzessive Erstellung des Datenmodells die wichtigste Aufgabe innerhalb der Entwicklung des DWH dar, weshalb auch von einem modellgetriebenen Ansatz gesprochen wird. Die Fachleute der Geschäftsbereiche und der IT rücken durch die graduelle Entwicklung der Modelle näher zusammen und es wird eine bessere Kommunikationsbasis geschaffen. Darüber hinaus ergeben sich bei der Generierung der Objekte in den zusammenhängenden Modellen Automatisierungspotentiale, beispielsweise durch Reverse Engineering. Durch die Verbindungen entsteht zudem eine höhere Transparenz der Datenverwendungen und -Abhängigkeiten der unter dem Stichwort Data-Lineage bekannt ist. Bei der Entwicklung der Modelle, aber auch anderen Artefakten, wie Calculation Views, kann überwiegend auf graphische Editoren zurückgegriffen werden und der SQL-Code wird effizient im Hintergrund erzeugt. Diese Vorgehensweise verringert die Komplexität und erleichtert den Einstieg in die Data-Warehouse-Entwicklung.
Cloudfähigkeit
In dieser Hinsicht kann das SAP HANA SQL Data Warehousing die Cloud-Optionen der SAP-HANA-Plattform voll ausnutzen (s.o. 1.1). Durch die Containerisierung der Entwicklungen in sogenannten MTAR-Archiven können diese sehr leicht zwischen On-Premise- (XSA) und Cloud-Umgebungen (Cloud Foundry) hin- und hergeschoben werden (Abbildung 1.2). Das SAP HANA SQL Data Warehouse ist damit vollkommen unabhängig von der zugrundeliegenden technischen Infrastruktur. Dies gilt dabei nicht nur für die Datenbankartefakte. Dadurch, dass die SAP-HANA-Plattform eine Möglichkeit zur Full-Stack-Entwicklung bietet, können auch Applikationslogiken und Entwicklungen zum User Interface separat zwischen On-Premise- und Cloud-Plattform ausgetauscht werden.
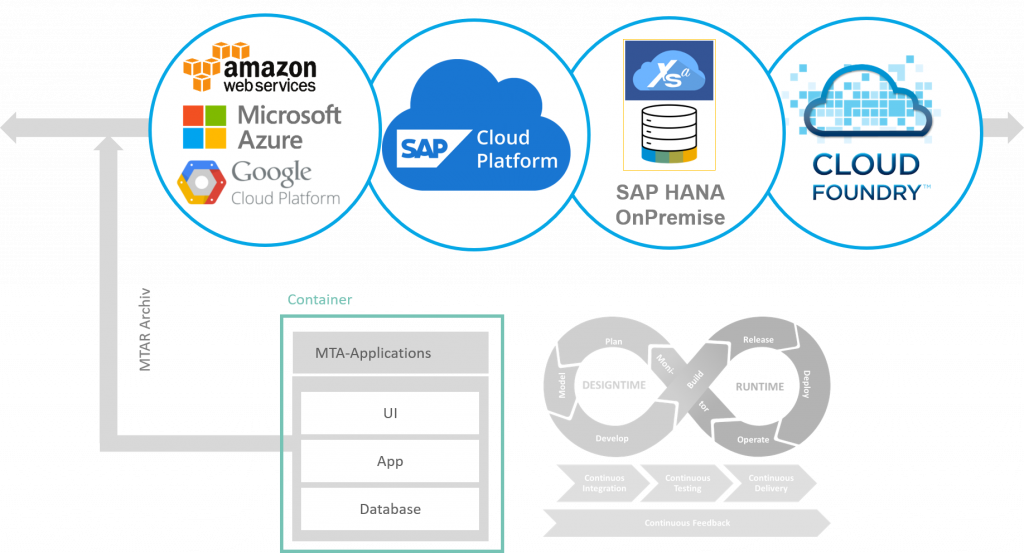
Grafik 02: Plattformübergreifende Auslieferung von Entwicklungen
Systemoffenheit
Das SAP HANA SQL Data Warehouse ist aus mehreren Gesichtspunkten ein vergleichsweise offenes System. Zum einen sorgt der SQL Standard für universelle Anbindungsmöglichkeiten, da er von den meisten anderen Systemen und Werkzeugen unterstützt wird. So können beispielsweise die heute immer wichtiger werdenden Self-Service-Datenvisualisierungstool frei gewählt werden. Sowohl Platzhirsche wie Tableau und Power BI, SAP-Lösungen wie SAP Analytics Cloud (SAX) oder sonstige sind leicht an das SAP HANA SQL Data Warehouse anbindbar. Darüber hinaus besteht auch eine große Offenheit gegenüber Tools, die agile Entwicklungsmethoden unterstützen. Hier sind Automatisierungstools wie Jenkins oder Bamboo sowie Issue Tracker wie Jira zu nennen. Diese interagieren mit dem Git-Repository des SAP HANA SQL Data Warehouse und reagieren unmittelbar und falls gewünscht automatisiert auf Veränderungen des Quellcodes. Zuletzt ist auch in dieser Hinsicht die zuvor genannte Flexibilität in Bezug auf On-Premise- oder Cloud-Plattform zu nennen. Hier ist ein plattformübergreifender, offener Austausch von Entwicklungen möglich.
Argumente aus der Praxis
Das SAP HANA SQL Data Warehouse besticht durch seine Flexibilität und Agilität im Hinblick auf Architektur und Entwicklungsansatz. Durch die Universalität der Datenbanksprache SQL und die Offenheit der SAP-HANA-Plattform ergibt sich ein hoher Freiheitsgrad in Bezug auf die Gestaltung der Datenstrukturen und Datenmanagementprozesse. Die SAP-HANA-Plattform bringt viele nützliche Tools und Services bereits vollintegriert mit. Darüber hinaus kann Software von Drittanbietern frei gewählt und in die DWH-Landschaft eingebunden werden. Mit diesen Eigenschaften verfügt das SAP HANA SQL Data Warehouse über Stärken, die von BI-Fachleuten hinsichtlich der Modernisierung ihrer Data Warehouses gegenwärtig sehr stark nachgefragt werden.
So kommt die aktuelle Forschungsstudie »Modernizing the Data Warehouse: Challenges and Benefits« des Forschungs- und Beratungsinstituts Business Application Center (BARC) zu dem Schluss, dass die wichtigsten Trends im BI-Umfeld auf ein effizienteres, effektiveres und agiles Datenmanagement auf Basis von Datensteuerung, Automatisierung und Self-Service gerichtet sind (BARC, Modernizing the Data Warehouse: Challenges and Benefits, 2019, S. 7). Grundlage dieser These ist eine Befragung von knapp 400, überwiegend aus Europa stammenden Fachleuten, zu den größten Herausforderungen des Data Warehousing. Zeitraubende Entwicklungsprozesse und die nur eingeschränkte Unterstützung von Self-Service-BI werden dort als größte Hürden genannt. Darüber hinaus wird die Unfähigkeit zur Anpassung an neue Anforderungen / Änderungen als bedeutendes Hindernis auf dem Weg zu einem effizienterem Datenmanagement betrachtet. Unsere Praxiserfahrung bestätigt diese Studienergebnisse.
Gerade die agilen Entwicklungsmöglichkeiten des SAP HANA SQL Data Warehousing mit schnellen Iterationen und kleinen, produktiven Auslieferungen kommen bei unseren Kunden gut an. Die Fachbereiche sind durch den modellgetriebenen Ansatz von Beginn an stark involviert und haben aufgrund der kurzen Durchlaufzeiten den Vorteil, unmittelbar korrigierend einwirken zu können. Dabei ist die automatisierte Nachverfolgung mit Issue-Tracking-Systemen wie Jira von großem Wert, da die betrieblichen Entscheider hier an einem Ort die Entwicklung des Data Warehouse sehr gut nachvollziehen und managen können. Die in der Praxis zumindest teilautomatisierte Auslieferung von Entwicklungen erspart zudem Aufwand und Nerven, die zuvor im Rahmen von großen Deployments häufig in großem Umfang benötigt wurden.
Darüber hinaus überzeugt die offene und flexible Struktur des SAP HANA SQL Data Warehouse. Fachbereiche freuen sich, dass Anpassungen möglich sind und bestehende IT-Strukturen nicht die betriebswirtschaftliche Strategie bestimmen. In der Regel finden wir in der Praxis drei Szenarien, in denen das SAP HANA SQL Data Warehousing seine spezifischen Stärken ausspielen kann.
- Im Unternehmen gibt es mehrere Data Warehouses, sowie ein SAP Business Warehouse (BW). Hier bietet das SAP HANA SQL Data Warehousing eine perfekte Ergänzung, die gesamte BI-Landschaft im Unternehmen zu integrieren und harmonisieren.
- Im Unternehmen wird SAP-Software genutzt, aber das Data Warehousing wurde bewusst mit anderen SQL-Ansätzen betrieben. Hier kann ohne großen Aufwand ein Wechsel zum SAP HANA SQL Data Warehousing vollzogen werden, um einerseits die Integration der übrigen SAP Software zu erhöhen und darüber hinaus die Leistungsfähigkeit und Agilität der SAP-HANA-Plattform zu nutzen.
- In den Fachbereichen gibt es kleine SQL-Datenbanken, die für analytische Zwecke von versierten Nutzern betrieben werden. Mit SAP HANA SQL Data Warehousing kann der Self Service dieser Fachbereiche beibehalten werden, da sie ihr gewohntes SQL-Knowhow weiter nutzen können.
Fazit
In diesem Blog haben wir Ihnen die Stärken des nativen SAP HANA SQL Data Warehousing erläutert und Ihnen aufgezeigt, was das SAP HANA SQL Data Warehousing zu einer attraktiven Lösung im BI-Umfeld macht. Die strukturelle Flexibilität und Offenheit sowie die Cloud-Optionen der SAP-HANA-Plattform auf der einen Seite und der modellgetriebene, agile Entwicklungsansatz auf der anderen Seite, eröffnen neue Wege die DWH-Landschaft im Unternehmen neu zu gestalten und die organisatorische Komplexität des Datenmanagements zu verringern (Abbildung 3.1). BI-Fachleute und Business User rücken so näher zusammen und generieren auf diese Weise schneller analytische Erkenntnisse, die zur Steuerung unternehmerischer Handlungen immer wichtiger werden. Für ein tiefergehendes Verständnis der einzelnen Aspekte des SAP HANA SQL DWH erscheinen demnächst weitere Blogs auf unserer Website. Sollten sich in der Zwischenzeit schon Fragen ergeben, kommen Sie gerne auf uns zu.
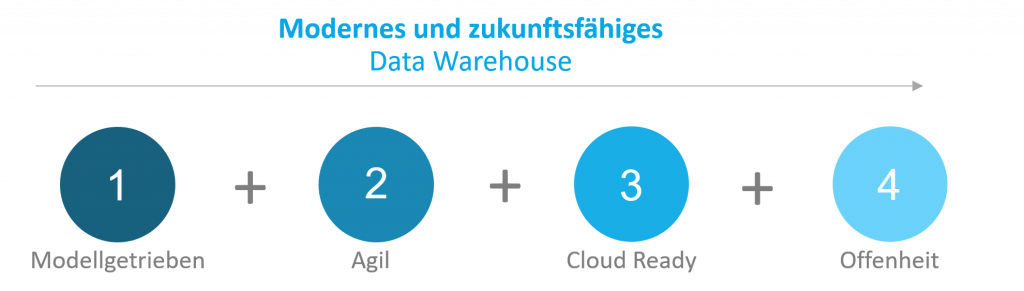
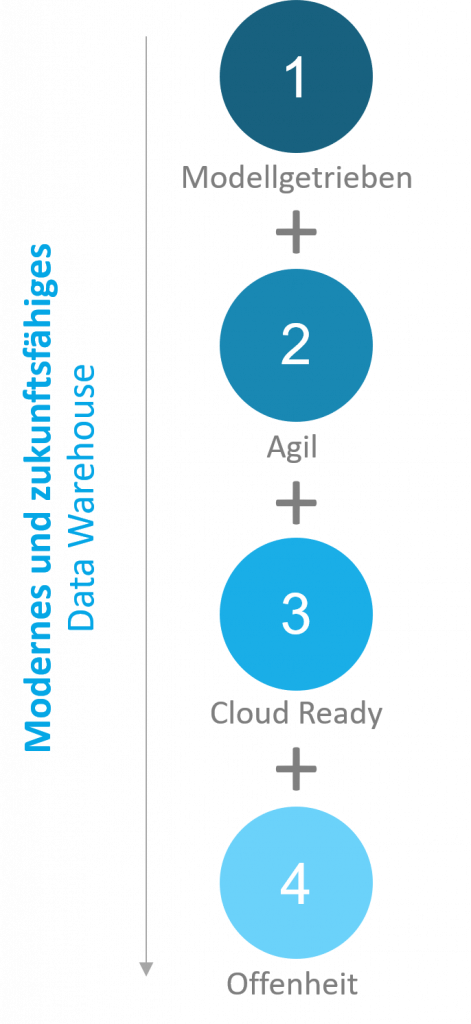
Grafik 03: Die Stärken des nativen SAP HANA SQL Data Warehousing
Autor: Dominik Fischer, Martin Peitz

Marius Wimmers
Service Manager
SAP Information Management
marius.wimmers@isr.de
+49 (0) 151/42205-434


