Ende 2020 ist die SAP Datasphere um den Business Builder erweitert worden. Was bedeutet das genau und wofür steht der Business Builder überhaupt? Wir geben Ihnen dazu einen Überblick.
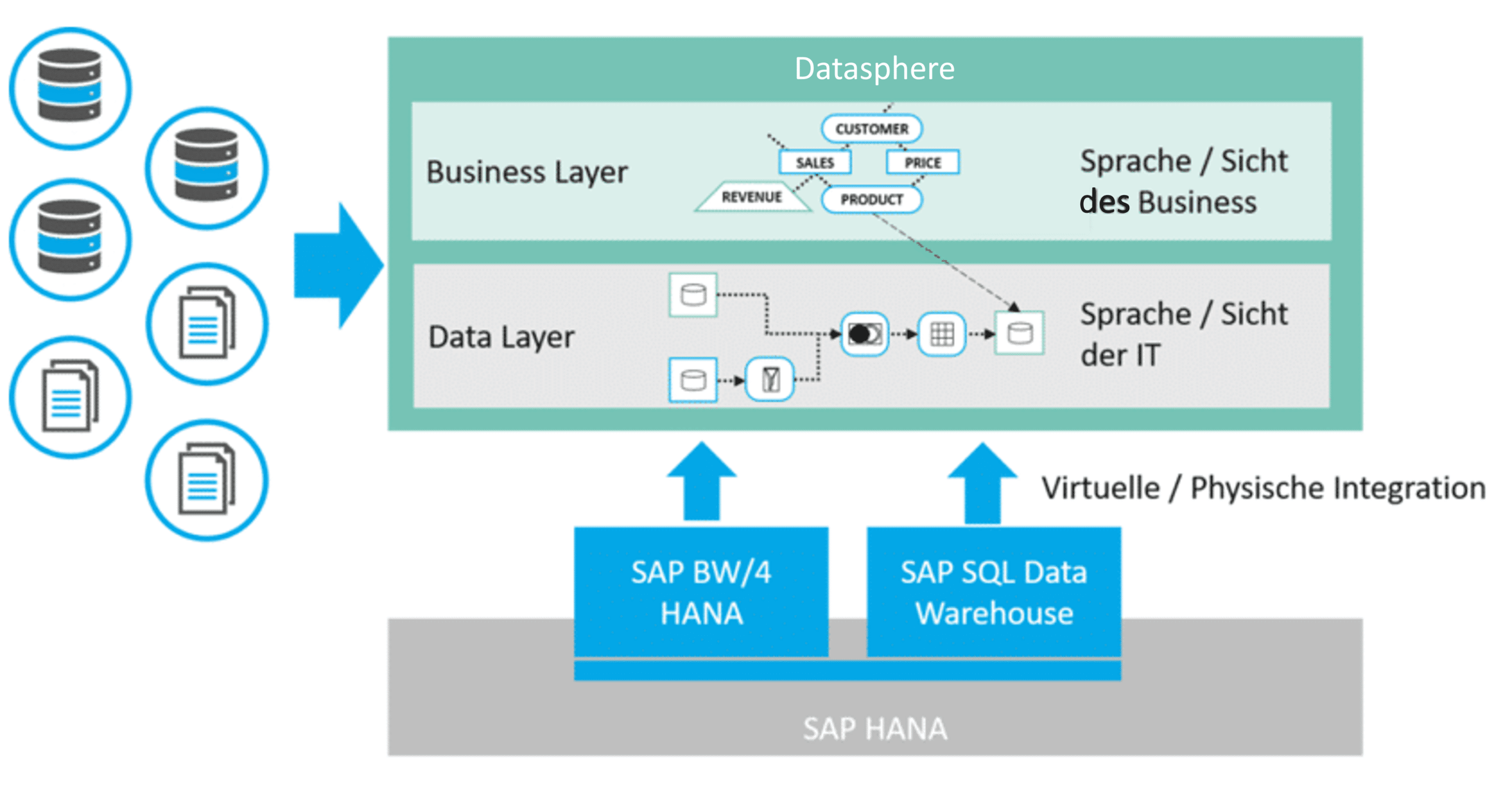
Im Kern geht es bei dem Business Builder darum eine Business Sicht auf die Objekte des Data Layers (siehe auch https://isr.de/news/sap-data-warehouse-cloud-einstieg-in-die-datenmodellierung/) herzustellen, in dem bspw. definiert wird welche technischen Objekte des Data Layers die Business Entität Produkt repräsentieren.
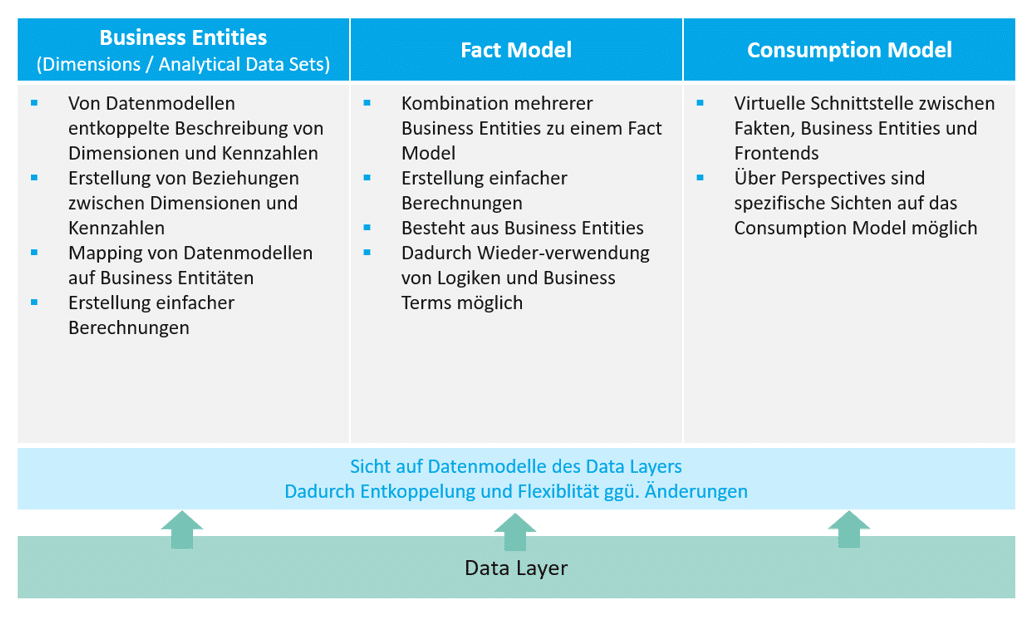
Business Entities sind eine abgeschlossene Sicht auf den Data Layer und repräsentieren eine betriebswirtschaftliche Entität (z.B. Produkt, Zeit, Umsatz). Es gibt zwei Typen:
Dimension:
Dimensionen bilden reine Stammdatentabellen ab, welche sowohl Attribute als auch Texte enthalten können. Diese können in der weiteren Modellierung entweder in Analytical Datasets assoziiert werden, oder aber als “Exposed Dimension” für Fact Models sichtbar gemacht werden.
Analytical Dataset:
Analytical Datasets enthalten Faktentabellen, welche Kennzahlen sowie Fremdschlüssel enthalten. Anhand der Fremdschlüssel können dann aus assoziierten Dimensions die entsprechenden Stammdaten nachgelesen werden.
Fact Model
Ein Fact Model ermöglicht es, mehrere Business Entities als Fakten und Dimensionen zu kombinieren und Berechnungen über mehrere Kennzahlen zu erstellen. Typischerweise werden Fact Models verwendet, um komplexere, aber generische Metriken oder KPIs abzubilden (z. B. Pipeline Coverage). Die Komplexität kann beispielsweise durch die Verknüpfung mehrerer Analytical Data Sets zustande kommen.
Consumption Model
Ein Consumption Model bildet einen bestimmten Anwendungsfall ab und ermöglicht die Kombination von Business Entitites sowie Fact Models. Sie bilden, zusammen mit der Perspective, die höchste Ebene innerhalb des Business Builders. Perspectives ermöglichen es, die exponierten Attribute und Kennzahlen einzugrenzen, sodass den konsumierenden Frontend-Tools (z. B. SAC) nur die jeweils relevanten Daten übergeben werden. Auf Grundlage eines Consumption Models können mehrere Perspektiven fußen.
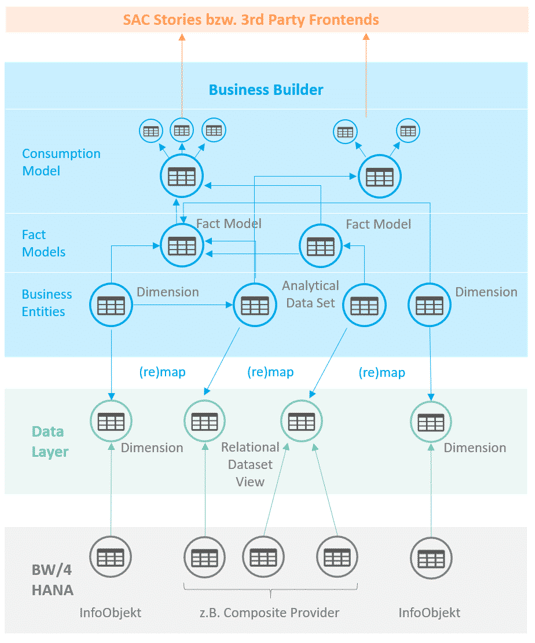
Zusammenhang zwischen dem Data Layer und den Modellierungsobjekten des Business Builders
Abb. 3: Modellierungsobjekte Business Builder | isr.de
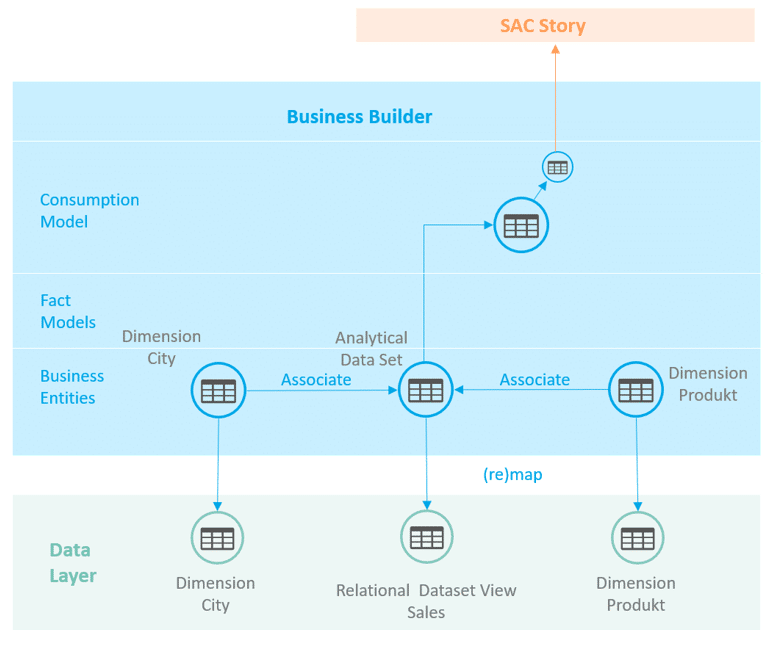
In dem einfachen Modell legen wir zwei Dimensionen sowie ein Analytical Data Set an, welches auf Objekte des Data Layers gemappt wird. Durch die virtuelle Verbindung wäre es theoretisch denkbar, dass die Tabellen des Data Layers auch getauscht werden können. Das macht die Flexibilität des Business Builders aus. Das Analytical Data Set inkl. der Assoziationen integrieren wir in ein Consumption Modell auf dessen Perspektive eine Story in der Analytics Cloud aufgebaut werden kann.
Abb. 4: Beispiel Modellierung Business Builder | isr.de
Dimensionen City und Produkt
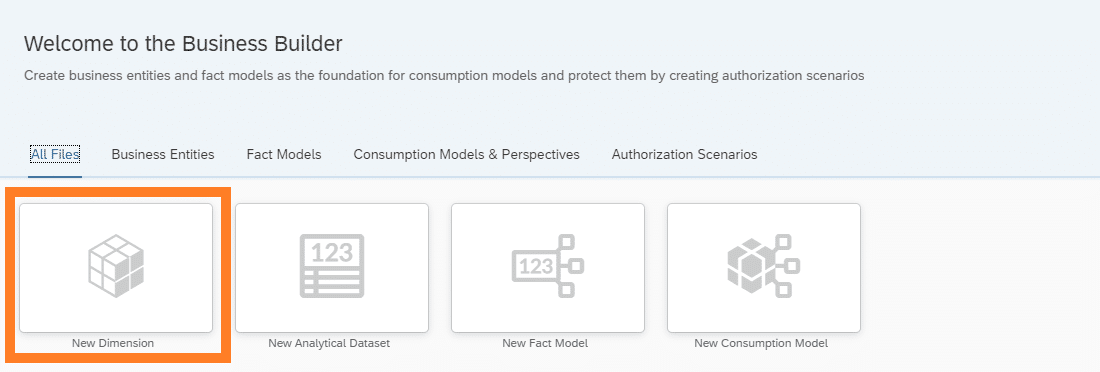
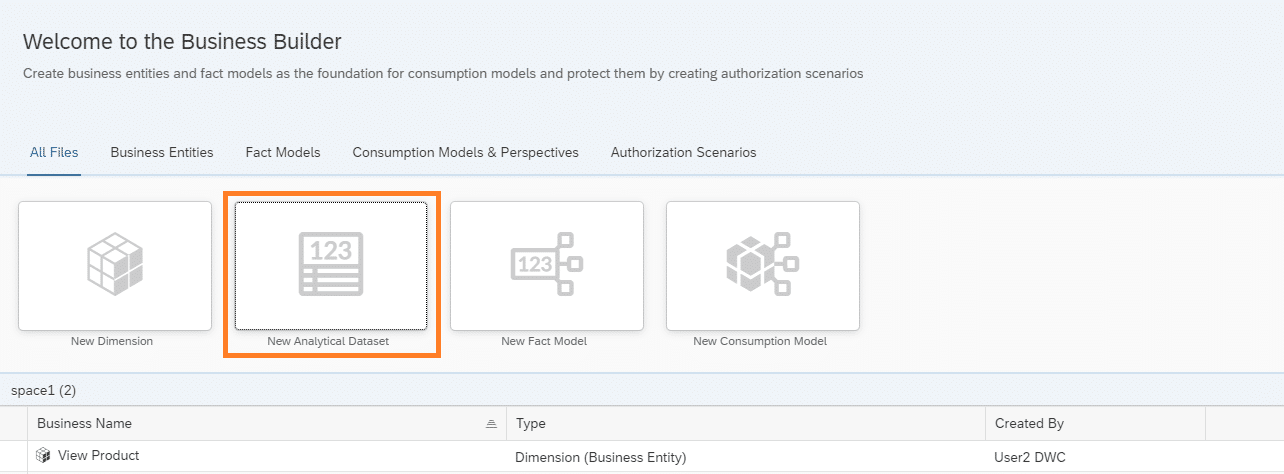
Zu Beginn wird eine Dimension von der Produkt-Tabelle erstellt, dafür muss im Business Builder der Reiter “New Dimension” ausgewählt werden.
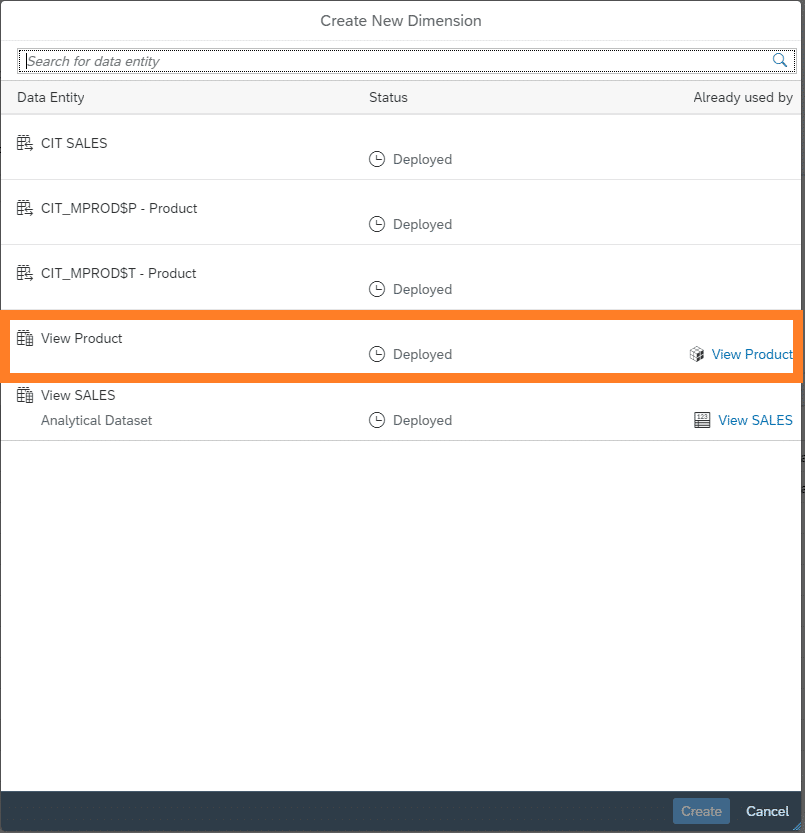
Danach wird die in das Datasphere “geladene” Tabelle bzw. View Produkt ausgewählt.
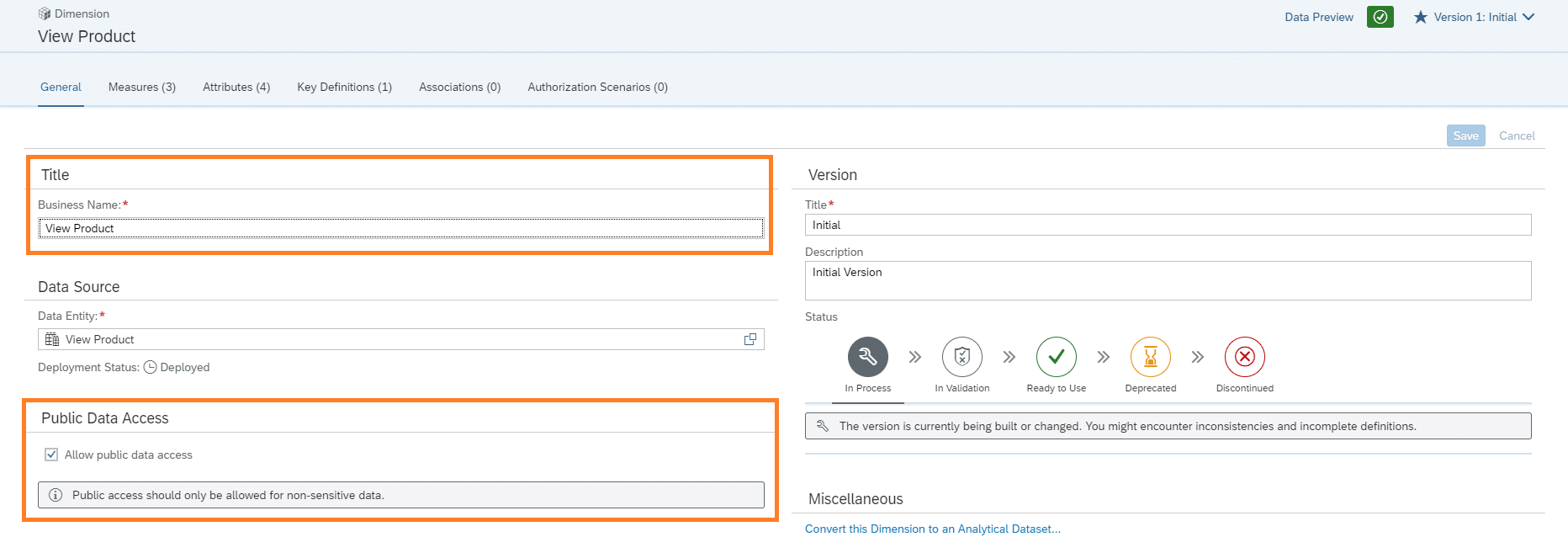
Folgend müssen Einstellung wie die Sichtbarkeit oder der Name für die Dimension ausgewählt werden. Danach muss über den Save Butten gespeichert werden.
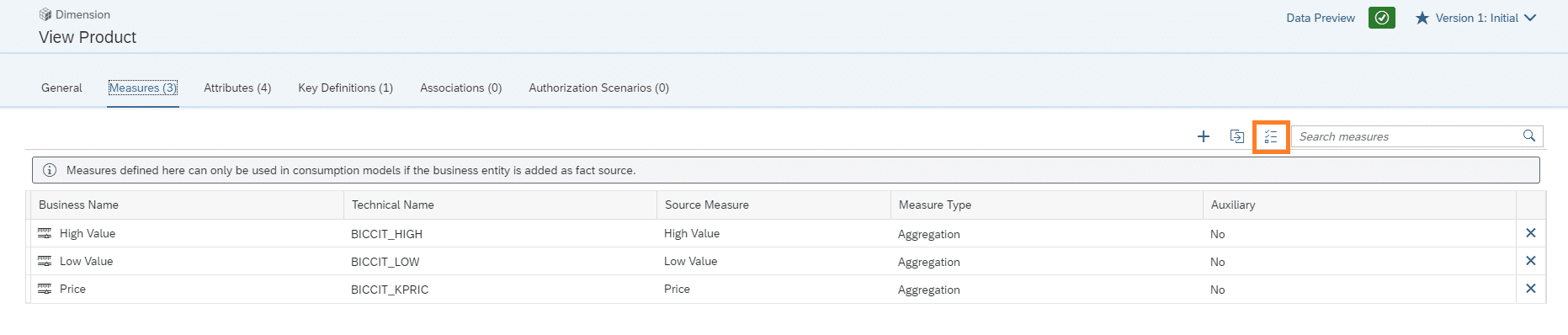
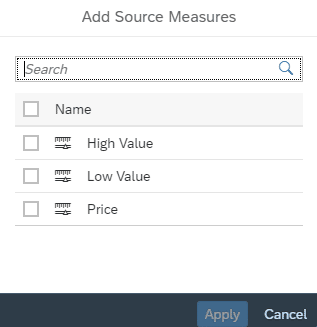
Im nächsten Schritt werden über den markierten Bereich die Measures für die Dimension hinzugefügt.
Auswahl der benötigten Measures erfolgt in einem neuen Dialog.
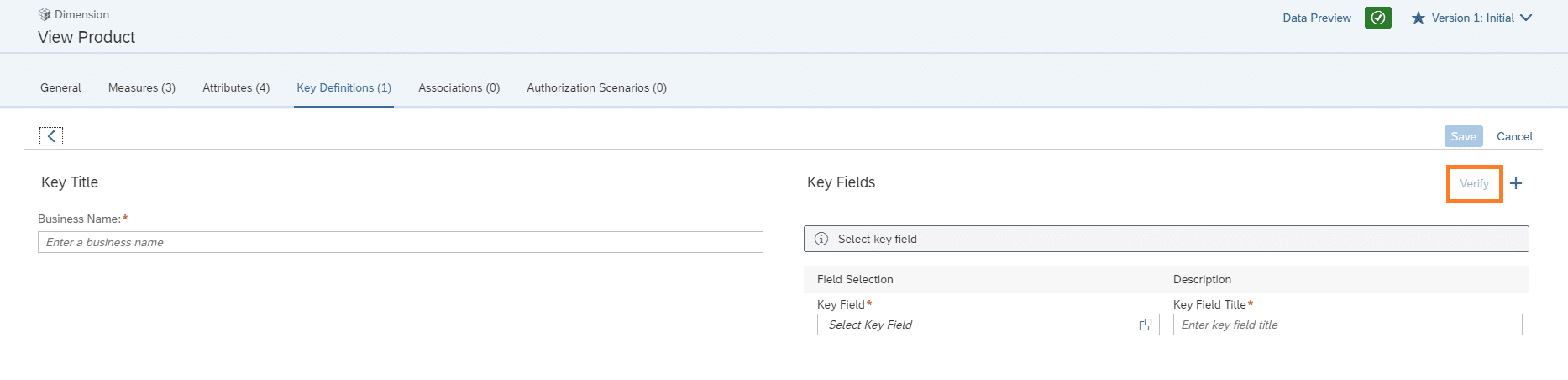
Analog wird das Verfahren für die Attribute durchgeführt. Nach Auswahl der benötigten Measures und Attribute, muss folgend der Key für die Dimension definiert werden, dieser muss durch den Verify-Button verifiziert werden, danach ist die Dimensionserzeugung erfolgreich abgeschlossen.
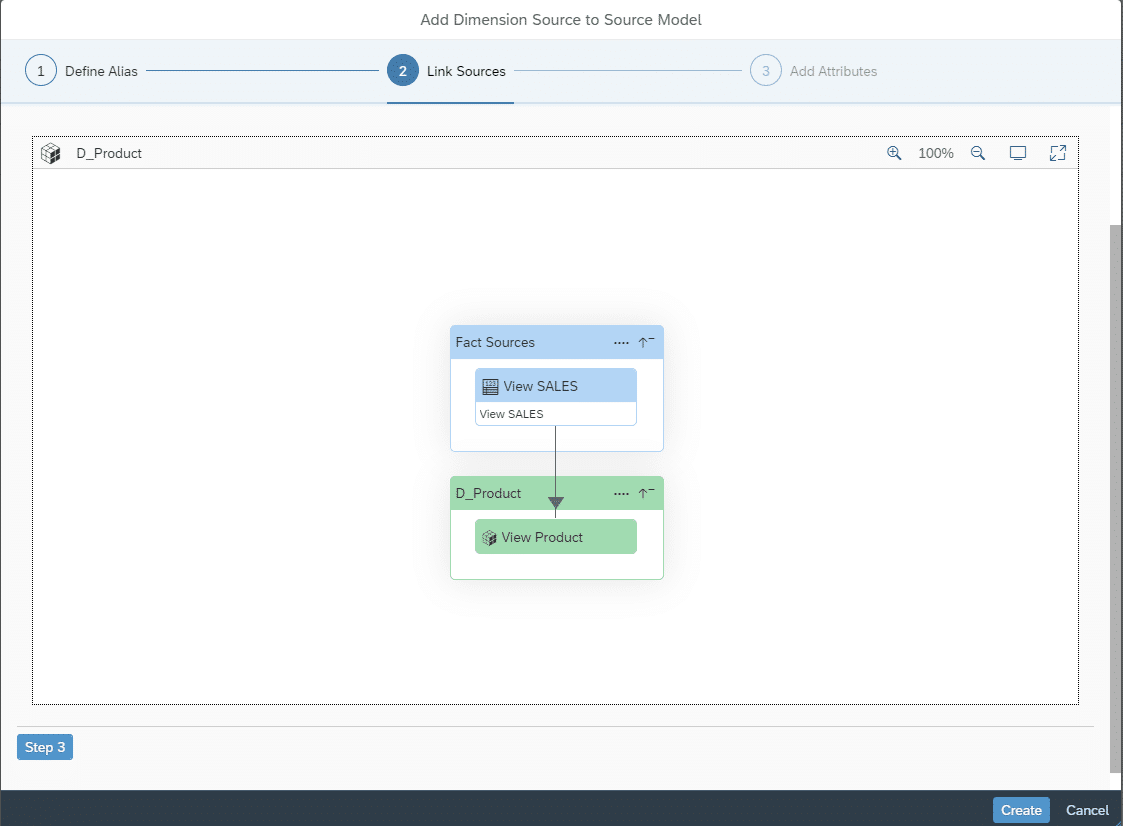
Gleichermaßen wird eine Dimension für die Stammdaten der City erstellt.
Analytical Dataset Sales
Nach dem erfolgreichen anlegen der Dimension auf den Produkt Stammdaten, wird ein neues Analytical Dataset für die Sales Daten benötigt. Dieses wird durch den Reiter “New Analytical Dataset” ermöglicht.
Im nächsten Schritt wird die View der Sales Daten in der Datasphere ausgewählt.
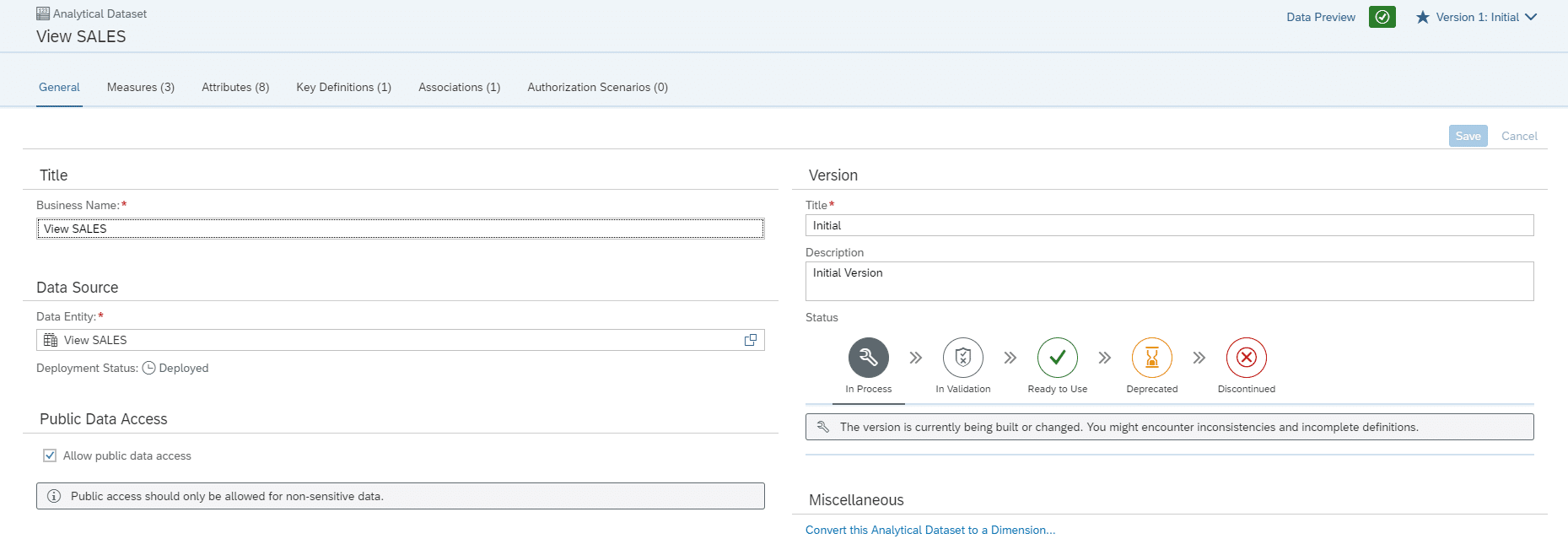
Nach Auswahl der passenden Daten, werden folgend die generellen Einstellungen für das Analytical Dataset getroffen. Dazu gehören unteranderem der Name, die Version und der Data Access.
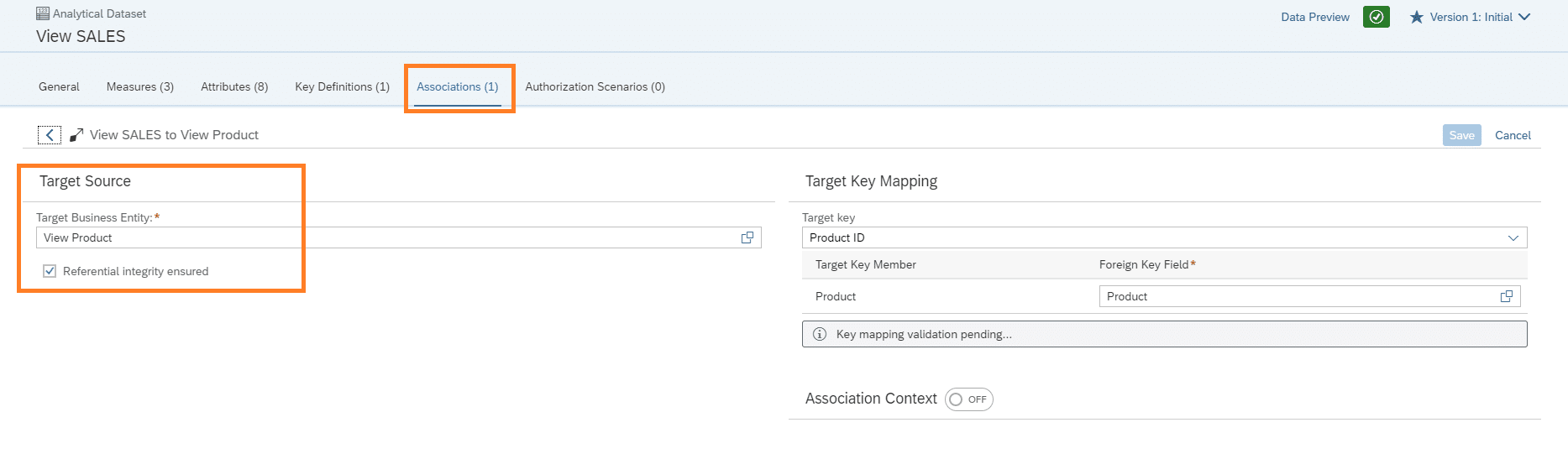
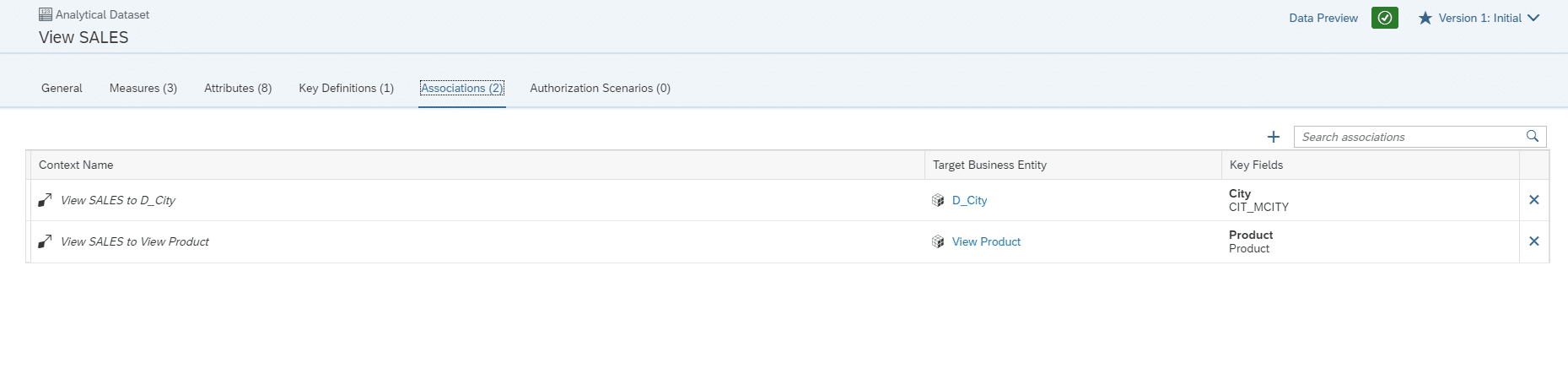
Wie auch bei der Dimension, müssen beim Analytical Dataset die Measures, Attribute und der Key definiert werden. Um eine Verbindung der Produkt Dimension mit den Analytical Dataset der Sales Daten zu erstellen, wird hier eine Assoziation angelegt, die durch den vorher definierten Key realisiert wird.
Analog wird auch die Dimension der Stores assoziiert.
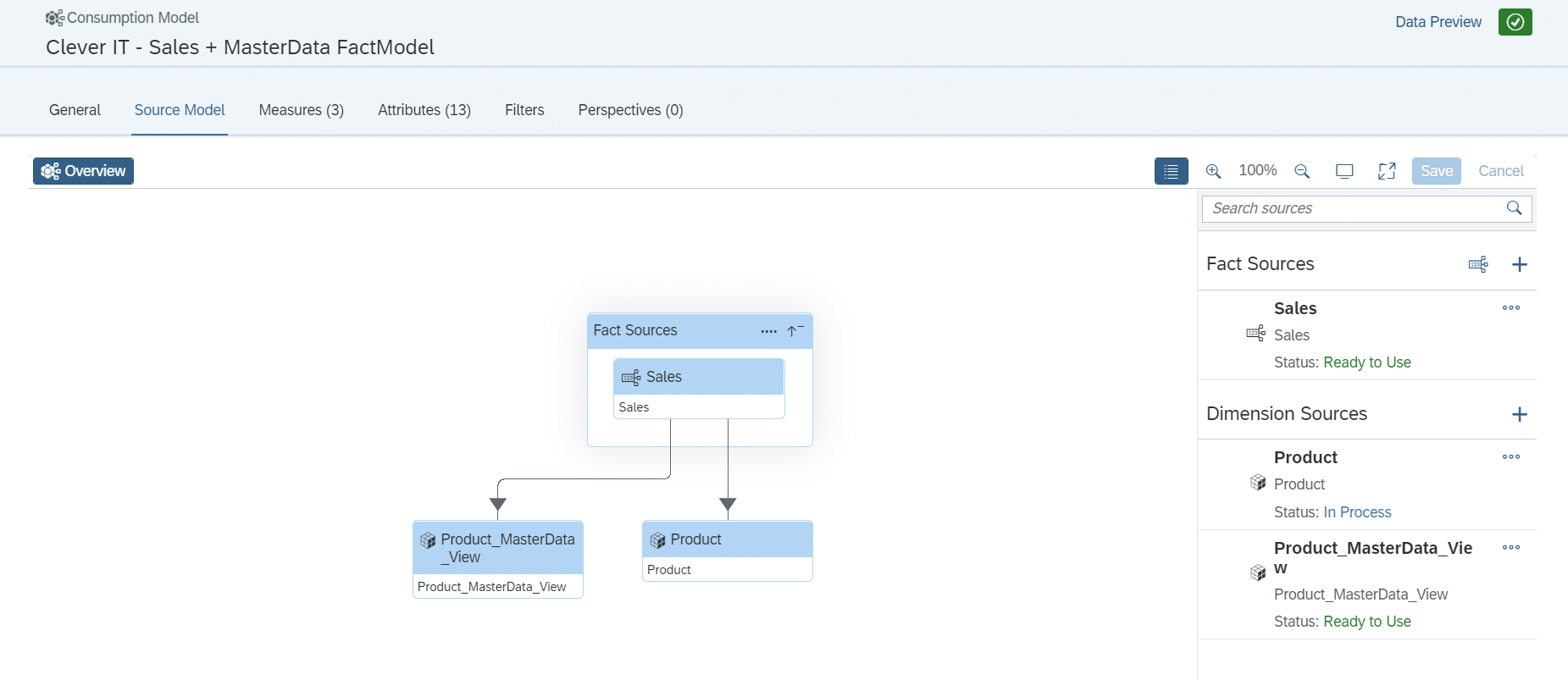
Consumption Model
Nachdem das Analytical Dataset deployed worden ist, kann mit der Modellierung des Consumption Models begonnen werden. Das Consumption Model wird benötigt, um im weiteren Verlauf eine Story auf dessen Basis zu erstellen.
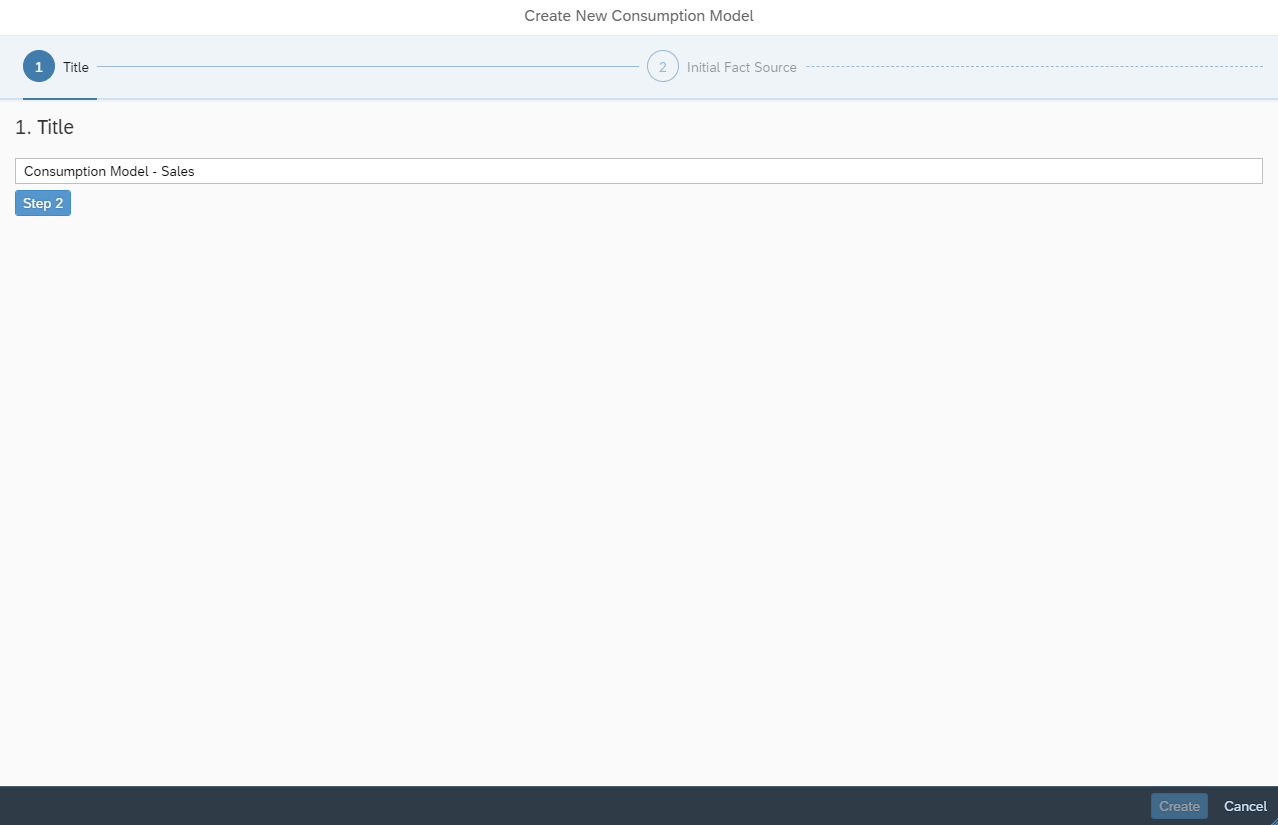
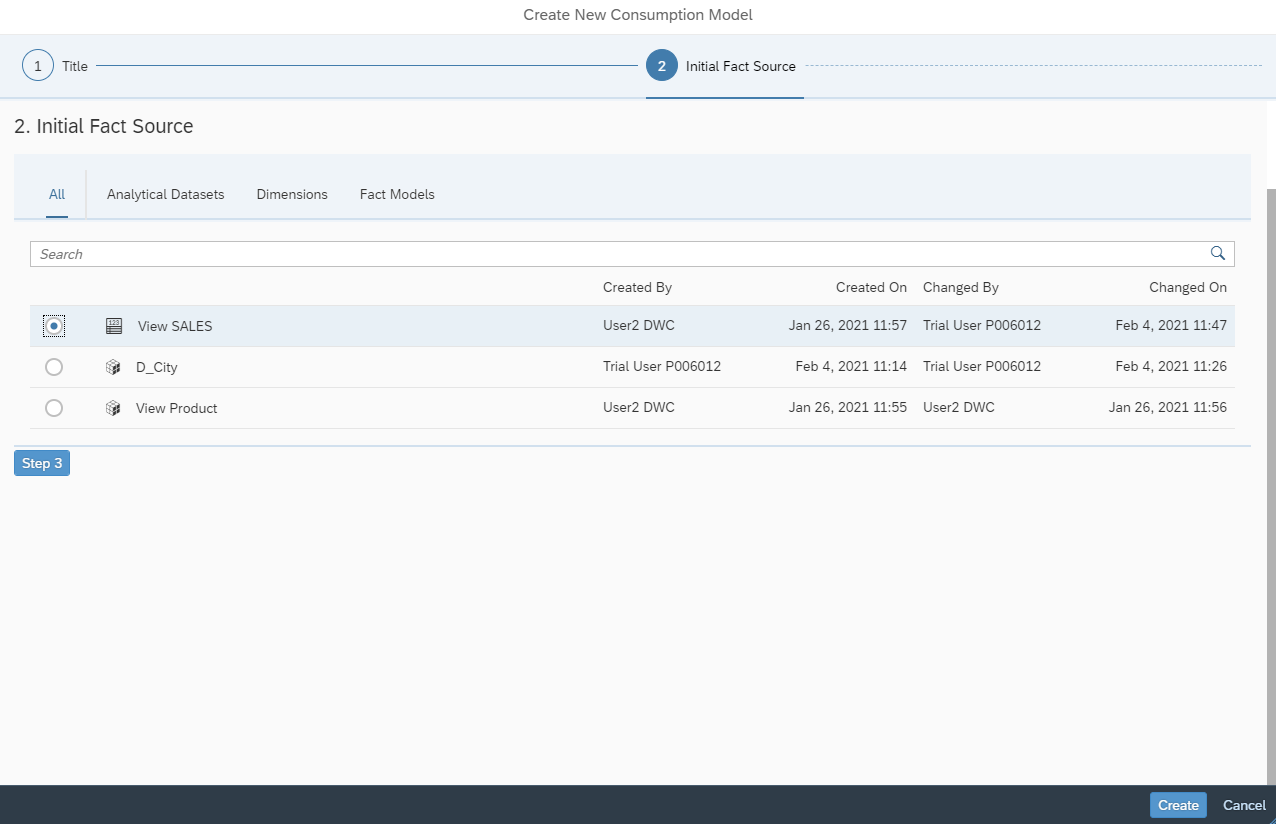
In folgenden Schritt muss das Consumption Model benannt werden.
Danach erfolgt die Auswahl der Datasource, hier das Analytical Dataset der Sales Daten.
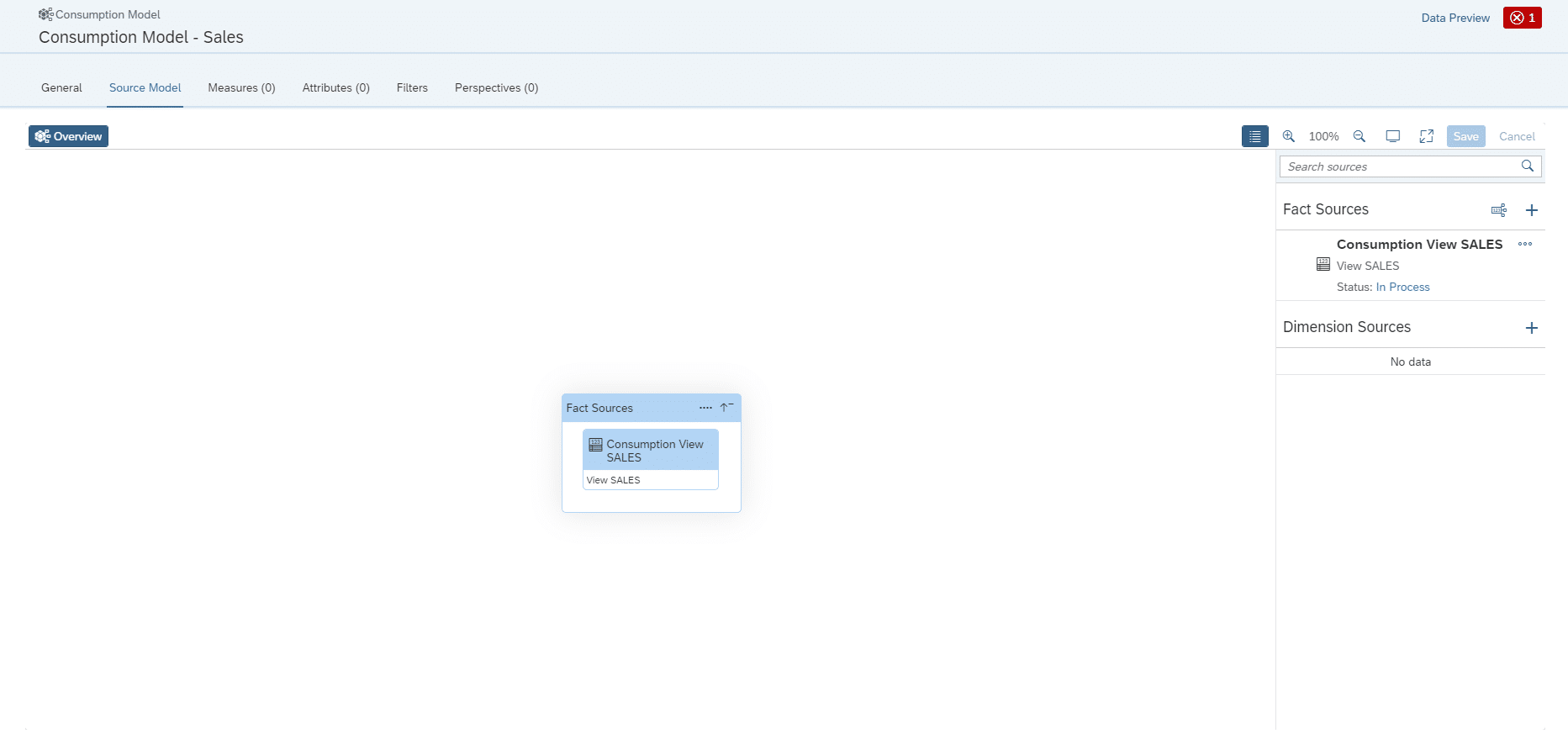
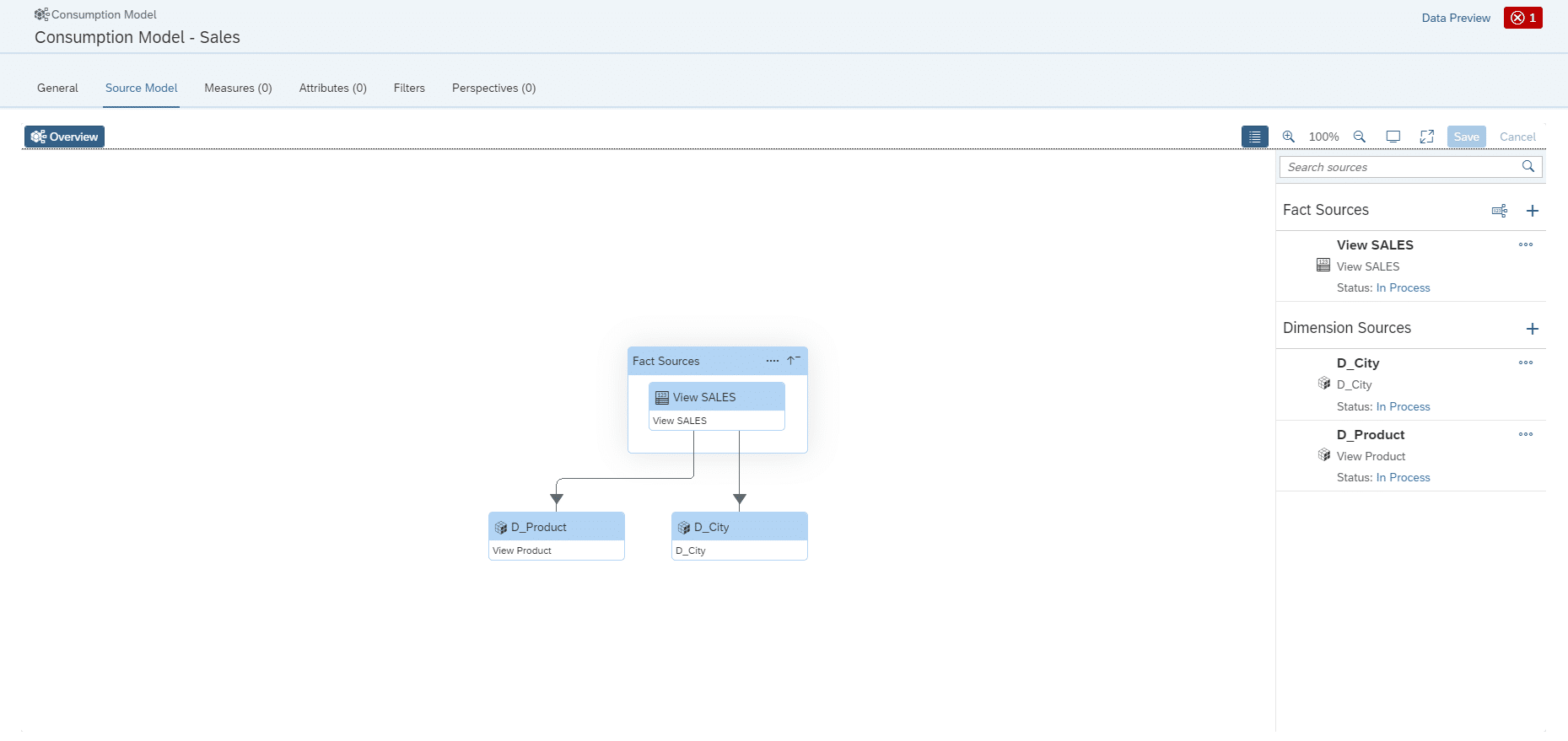
Folgend wird das Analytical Dataset als Fact Source im Consumption Model angelegt.
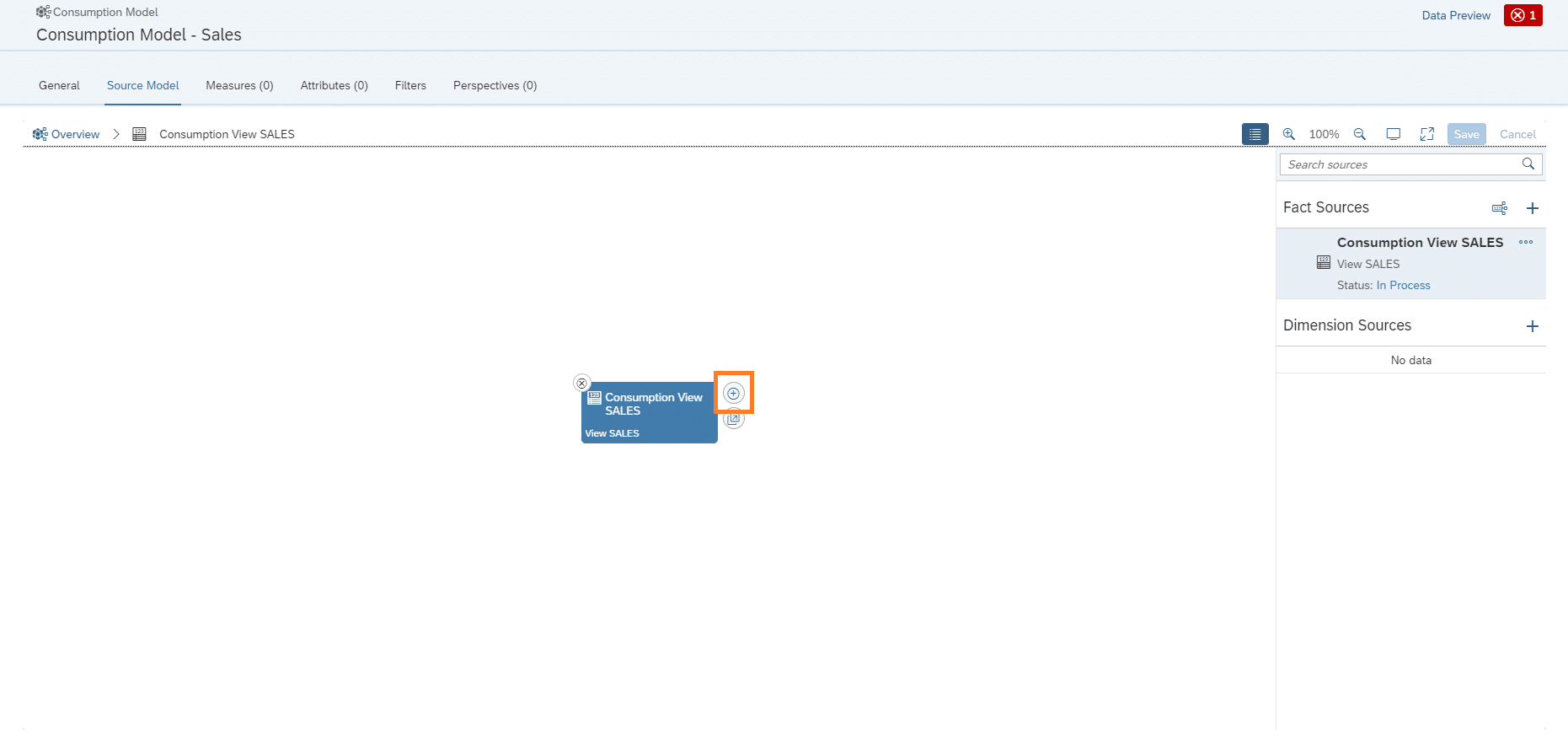
Um die Assoziierte Dimension der Produktdaten hinzuzufügen, muss hier über das “+” die Dimension ausgewählt werden.
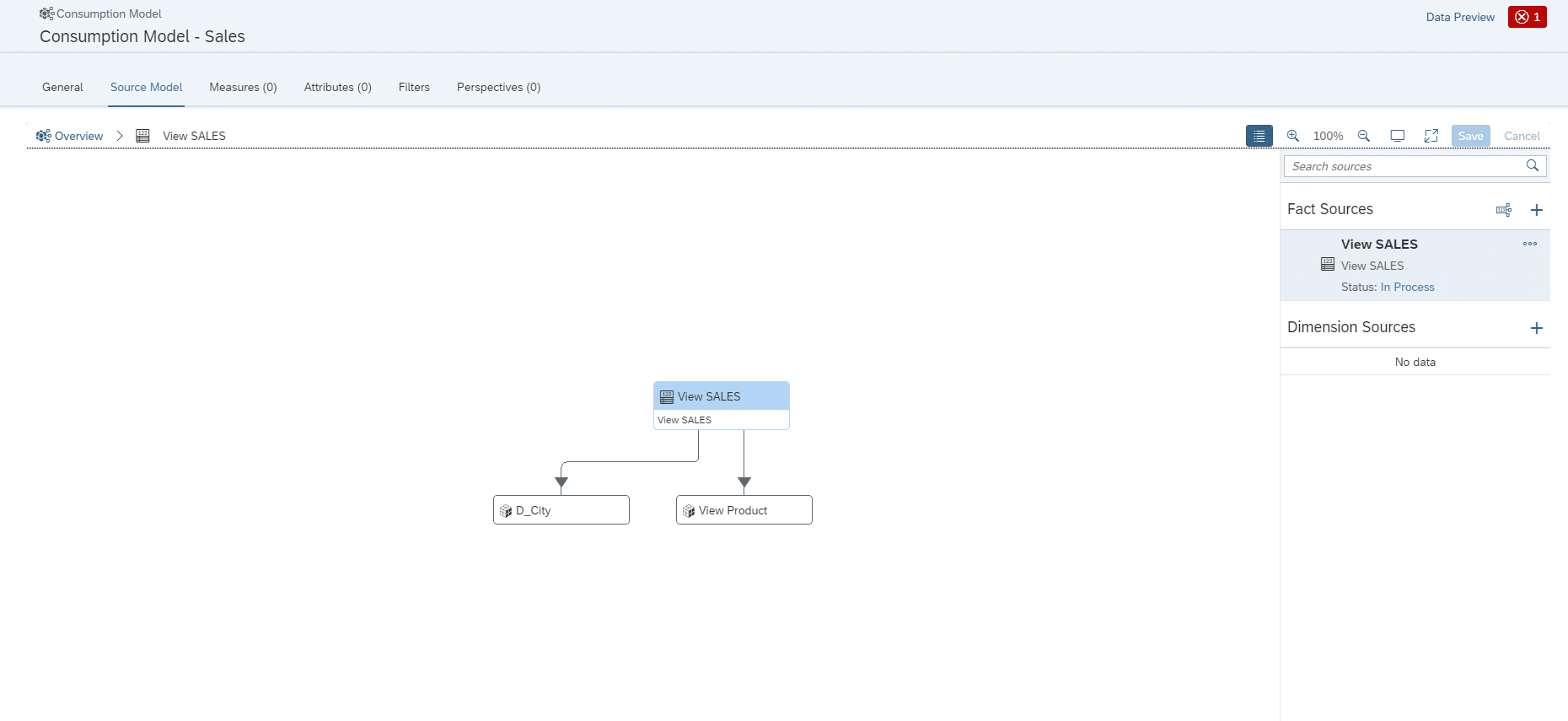
Im folgenden Schritt müssen die Dimensionen einzeln hinzugefügt werden.
Gleichermaßen muss dies für die Dimension der Stores durchgeführt werden. Nach der Namensgebung ist das Model fast fertig gestellt.
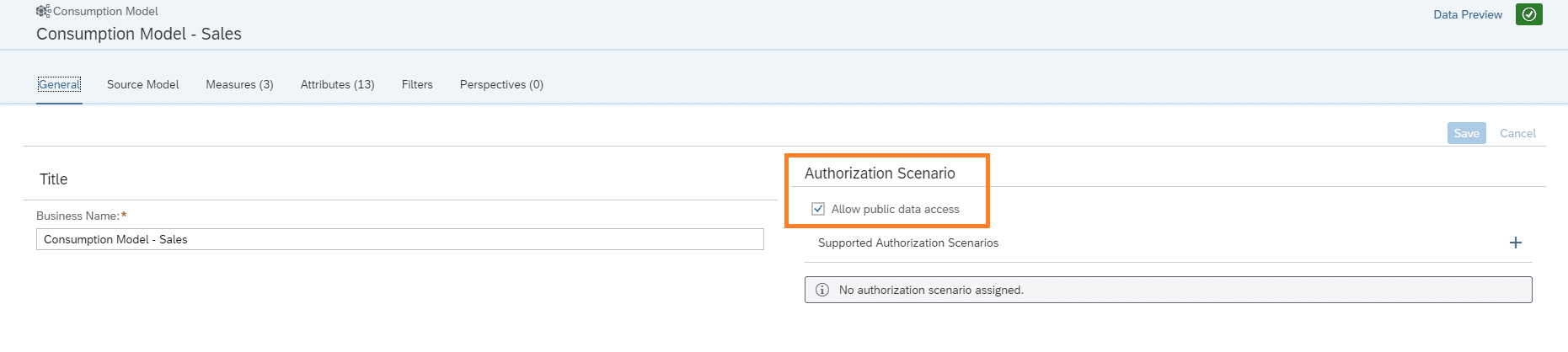
Wie auch zuvor müssen Measures und Attribute vergeben werden. Um das Consumption Model später problemlos verwenden zu können muss hier noch der Data Access autorisiert werden.
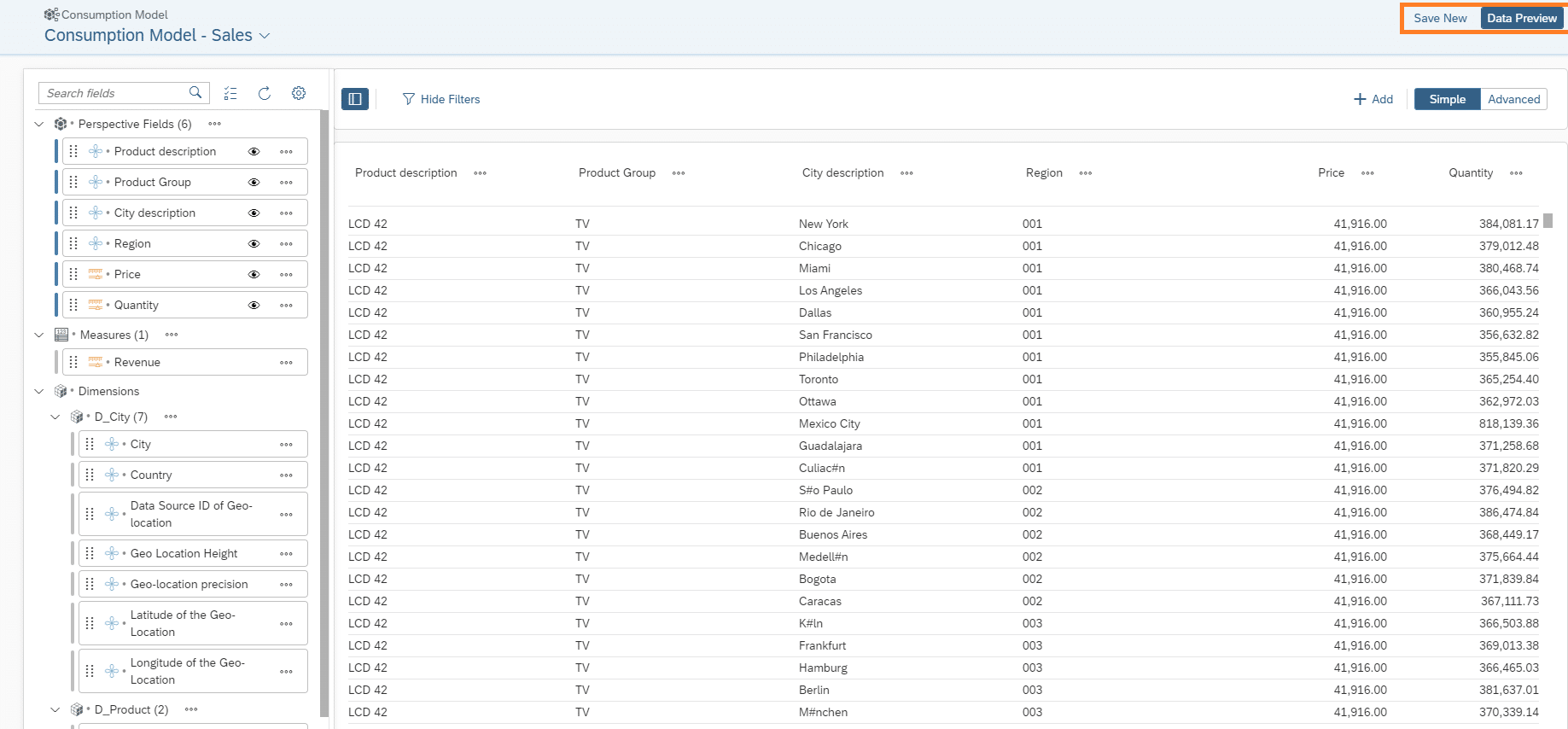
Neu ist bei dem Consumption Model die Perspective, in dieser werden die Measures und Attribute ausgewählt, die später in einer Story verwendet werden sollen.
Auswahl der Felder:
Nach erfolgreichen Deployment kann auch ein “Data Preview” angezeigt werden.
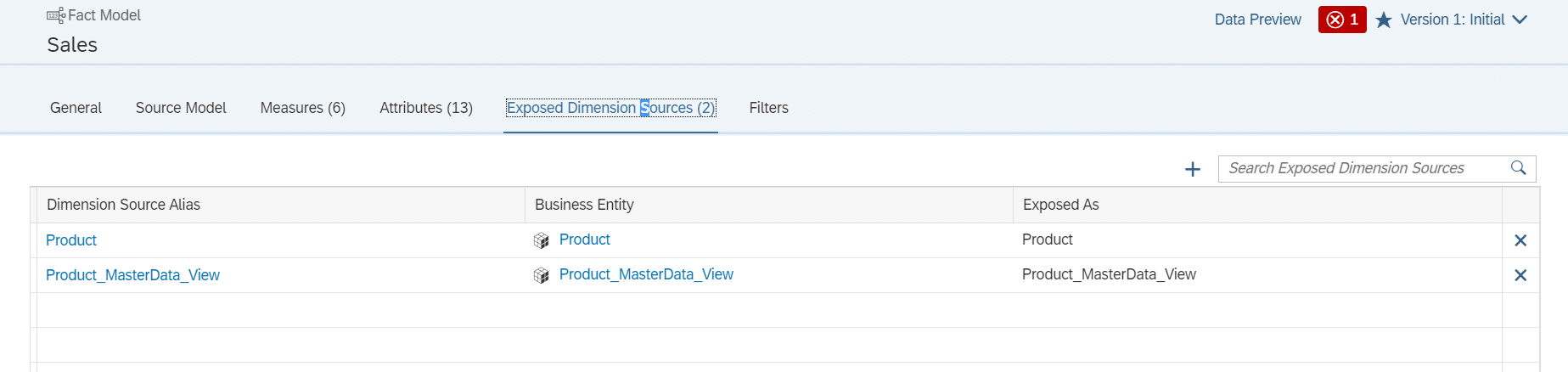
Soll statt einem Analytical Data Set ein Fact Model im Consumption Model genutzt werden, müssen bei dem Fact Model die Assoziierten Dimensionen als Exposed Dimension Sources angelegt werden.
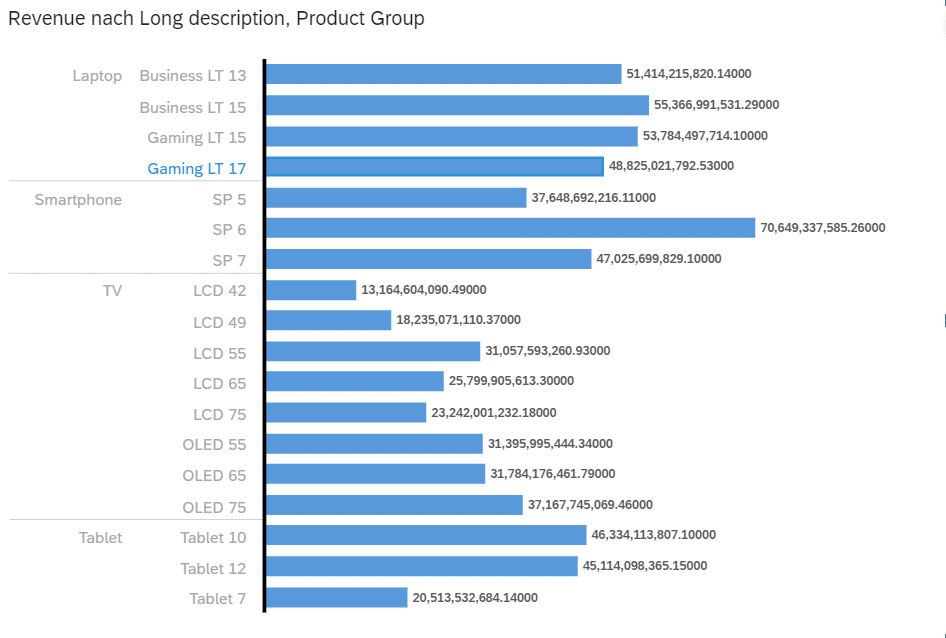
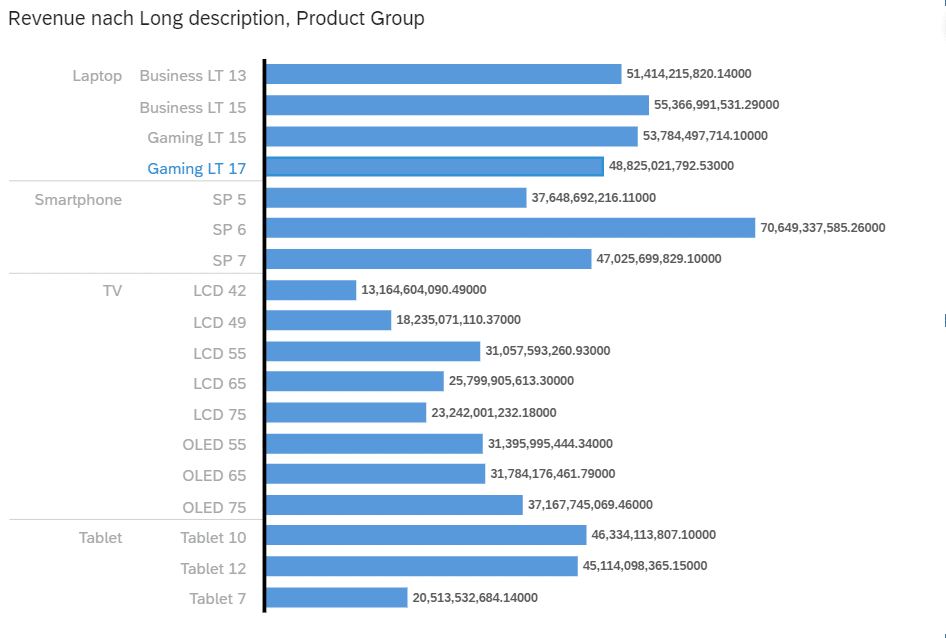
Visualisierung im Storybuilder nach Umsatz pro Produkt und Produktgruppe
Grundsätzlich besteht für alle Objekte zudem die Möglichkeit, den Zugriff mittels Data Access Control zu beschränken.
Unser erster Eindruck
In einer immer komplexeren Geschäftswelt, sowie sich dynamisch verändernden Anforderungen von Unternehmen, aber auch beeinflusst von stetig zunehmenden Datenmengen, ist es von zentraler Bedeutung, über eine geordnete und leistungsfähige IT-Landschaft zu verfügen. Dies gilt besonders im Business Intelligence Kontext, da hier auf Grundlage der vorliegenden Daten, auch wichtige Entscheidungen herbeigeführt werden sollen.
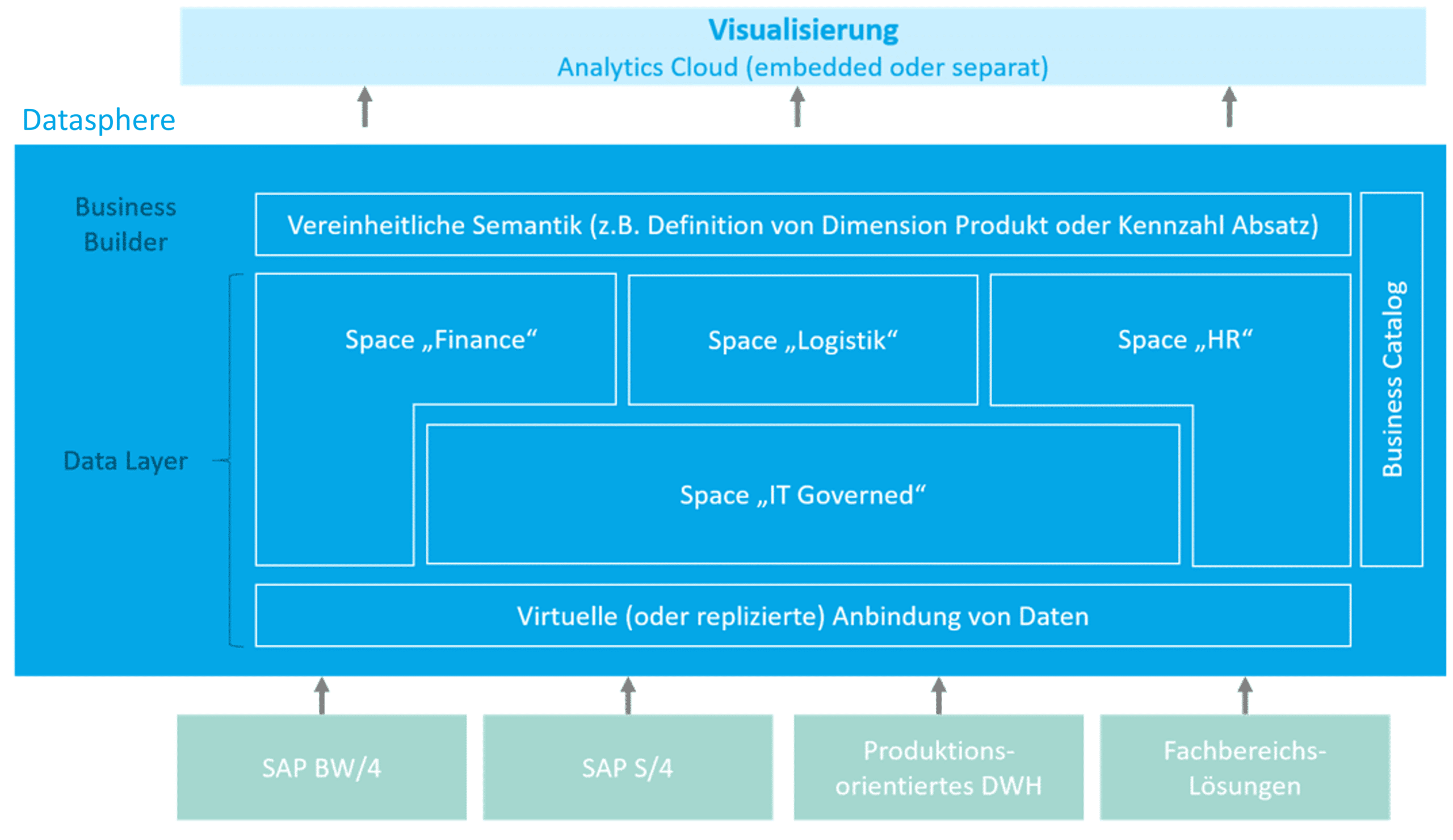
Der Business Builder verfolgt als ein wesentliches Ziel, eine Entkoppelung von Semantiken und Datenmodell. Bei späteren Änderungen am zugrundeliegenden Datenmodell, können diese schnell und unkompliziert in die Semantikschicht übernommen werden (zum Beispiel Verwendung eines anderen Quellfelds). Die Datenquellen können dabei sowohl aus SAP- als auch NonSAP-Systemen stammen. Die Datasphere kann eine einheitliche virtuelle Business Sicht über mehrere Quellsysteme hinweg herstellen und dient damit als Virtualization (Business-)Layer.
Abb. 5: Virtualisierung | isr.de
Neben einer einfachen Beschreibung der Semantik, gibt es noch Potenziale zur Funktionserweiterung des Business Builders. Als Beispiel sei hier die Abbildung komplexerer Zusammenhänge von Objekten des Data Layers bei der Definition von Business Entitäten genannt. Wenn mehrere Datenobjekte des Data Layers bspw. einfach verknüpft werden können (Joins), könnte so recht einfach eine Dimension aus mehreren Quelltabellen des Data Layers aufgebaut werden. Aktuell muss dies primär im Data Layer vorbereitet werden.
Wir werden die Entwicklung weiter begleiten und sind gespannt auf die kommenden Releases.
Wir agieren seit 1993 als IT-Berater für Data Analytics und Dokumentenlogistik und fokussieren uns auf das Datenmanagement und die Automatisierung von Prozessen. Ganzheitlich und im Rahmen eines umfassenden Enterprise Information Managements (EIM) begleiten wir von der strategischen IT-Beratung über konkrete Implementierungen und Lösungen bis hin zum IT-Betrieb. ISR ist Teil der CENIT EIM-Gruppe.