Das data lakehouse ist ein ansatz, der das potenzial hat, das datenmanagement für Business Intelligence und Analytics erheblich zu vereinfachen.
Neben dem klassischen Data Warehouse haben Data Lakes als zentrale Speicherorte stark an Bedeutung gewonnen. Die Integration beider Ansätze ist daher eine bedeutende Fragestellung für die Weiterentwicklung einer BI- und Datenstrategie. Hinter dem Kofferwort aus Data Warehouse und Data Lake steckt ein Data-Management-Ansatz, der verspricht, die Funktionen beider Systeme in einem technischen Konzept zu vereinen:
- Die Speicherung von strukturierten, semi-strukturierten und unstrukturierten Rohdaten in der offenen, skalierbaren Architektur des Data Lake.
- Die Funktionalitäten der Datenstrukturierung und -verarbeitung des Data Warehouse.
In diesem Blogartikel erläutern wir den Ansatz und werfen einen genaueren Blick auf den Aufbau und die Vorteile eines Data Lakehouse. Zum Aufbau eines Lakehouse ist Databricks zurzeit der namhafteste Anbieter, mit dem SAP, wohl auch aus diesem Grund, eine strategische Partnerschaft eingegangen ist.
SAP bietet mit der SAP-HANA-Plattform und den Anwendungen SAP Datasphere und SAP BW aktuelle Data-Warehouse-Lösungen. Hierbei liegt der Fokus der Investitionen auf der Datasphere, SAP’s strategischer Cloud-Data-Warehouse-Lösung, die auf die modernen Anforderungen von Fachbereichen an datengetriebenen Self-Service ausgerichtet ist.
1. Das Data-Lakehouse-Konzept: Definition und Grundlagen
Das klassische Data Warehouse
Das klassische Data Warehouse verfügt mit einer leistungsstarken Datenbank über integrierte Speicher- und Rechenressourcen und sorgt so für eine konstant hohe Performance bei der Datentransformation und -abfrage. Darüber hinaus bietet es eine hohe Datenqualität und reichhaltige semantische Beschreibung geschäftsrelevanter Daten. Es erfordert jedoch auch eine aufwändige Datenaufbereitung und ist weniger flexibel bei der Aufnahme semi- und unstrukturierter Daten wie Social-Media- oder Sensordaten (siehe Abb. 1). Die ständige Verfügbarkeit der leistungsstarken Rechenressourcen kann zudem zu hohen Kosten führen, die in Phasen mit wenigen Schreib und Lesevorgängen vermeidbar wären.
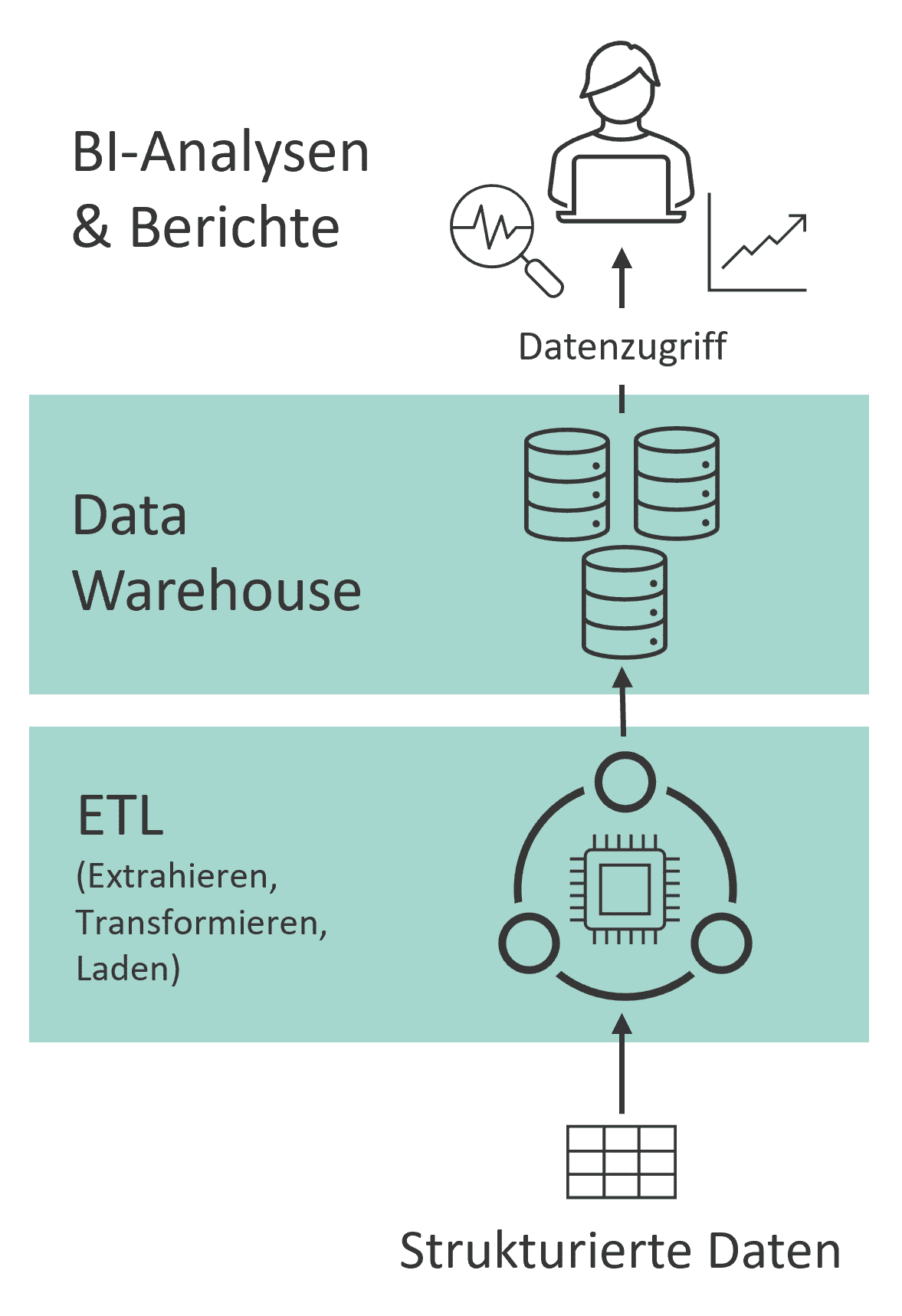
Data Lake
Ein Data Lake ist auf die zentralisierte Speicherung großer Mengen an Daten ausgelegt, ohne jedoch Rechenleistung zur Verfügung zu stellen. Für Schreib- oder Lesevorgänge werden Dienste benötigt, die die entsprechenden Computing-Ressourcen bereitstellen. Data Lakes bieten die Grundlage für Anwendungsfälle wie maschinelles Lernen und prädiktive Analysen, die für datengetriebene Geschäftsentscheidungen zunehmend an Bedeutung gewinnen. Data Lake und Data Warehouse werden daher in den letzten Jahren in Kombination verwendet (siehe Abb. 2).
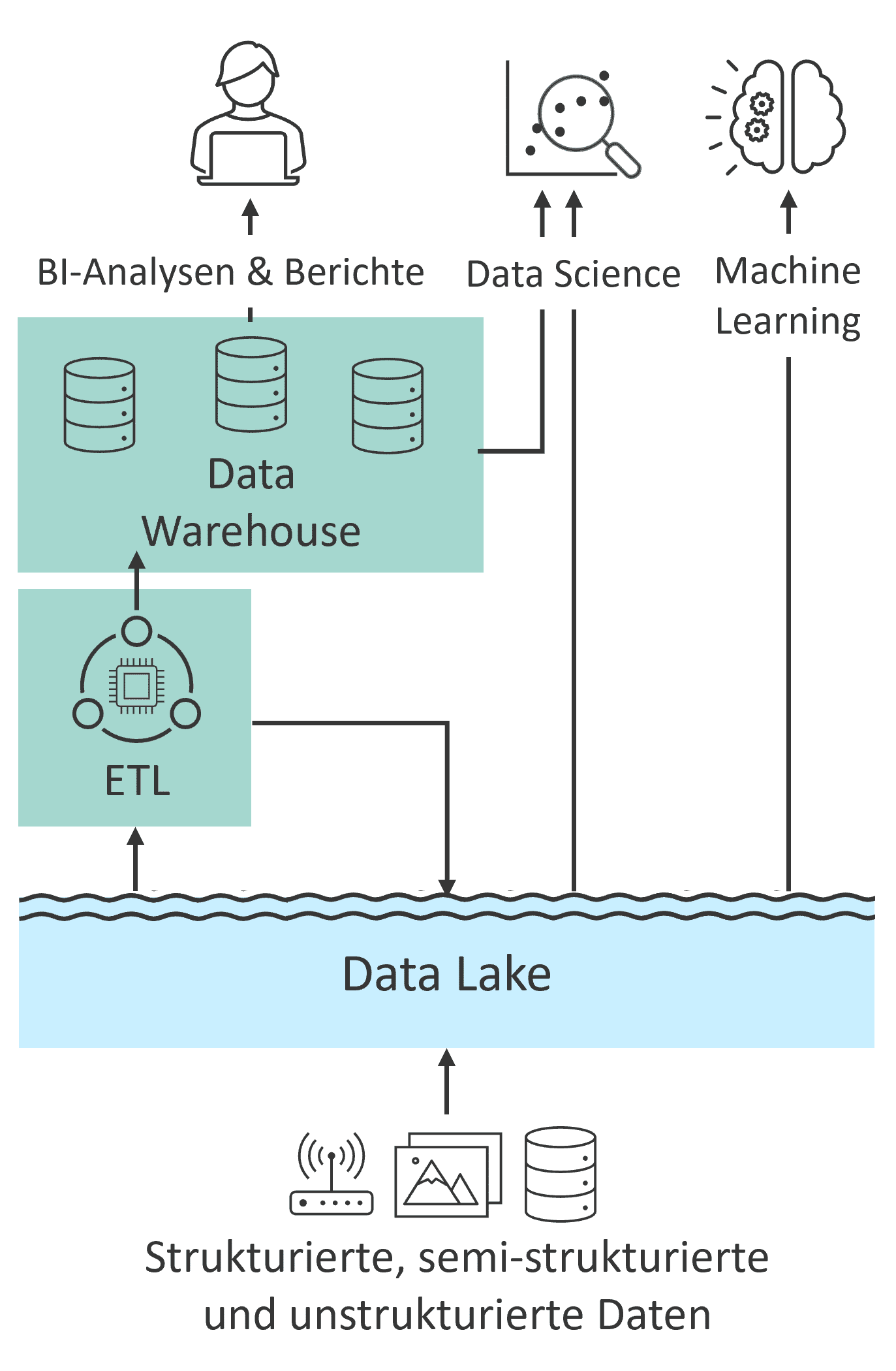
Das Data Lakehouse Konzept
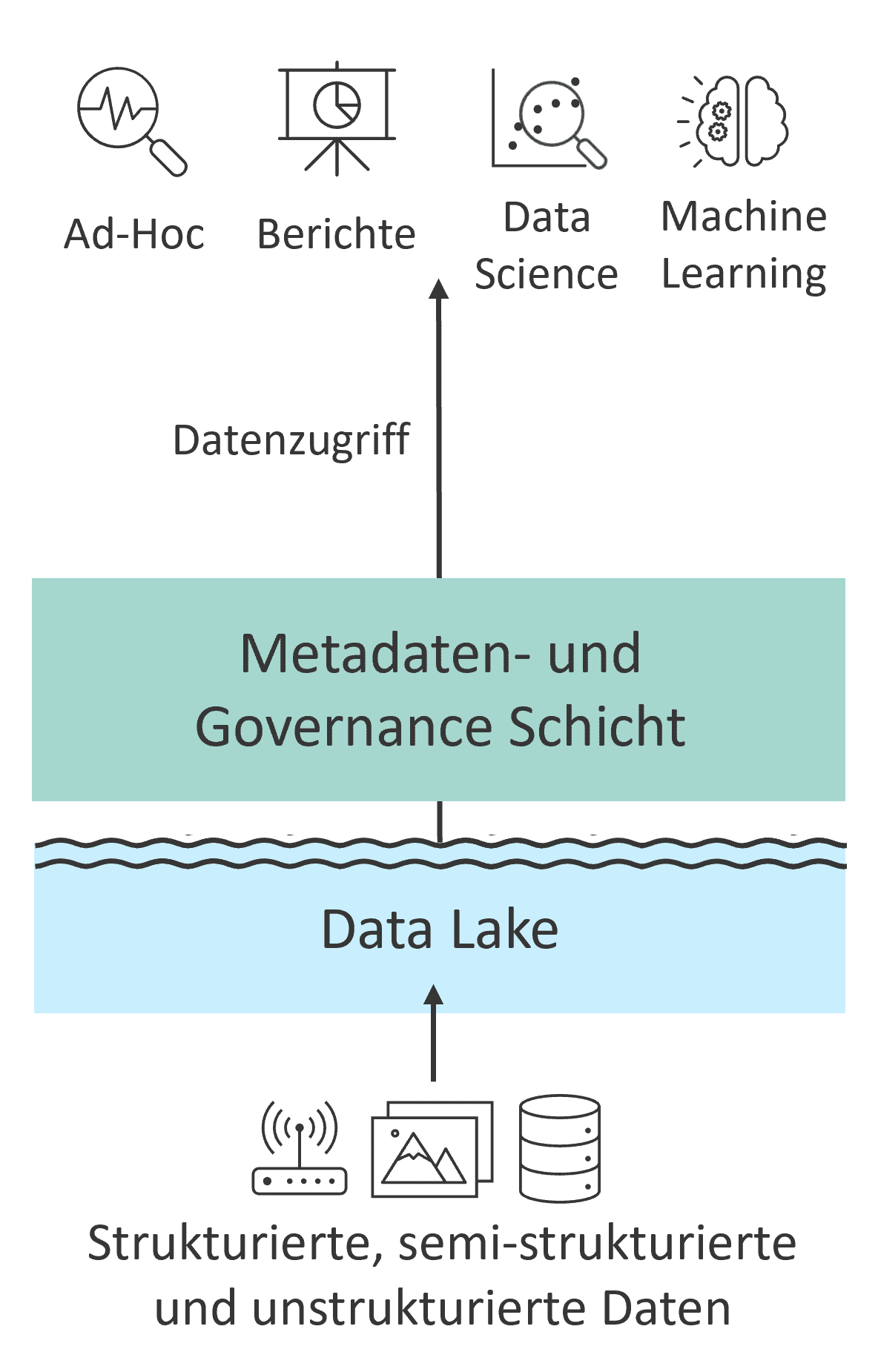
Das Data-Lakehouse-Konzept überführt diese zweistufige Verbindung in einen gemeinsamen Ansatz und vereint so die besten Aspekte beider Welten (siehe Abb. 3). Es bietet die Flexibilität eines Data Lakes bei der Datenaufnahme und -speicherung sowie die strukturierte Organisation und Qualität eines Data Warehouse. Zentral ist die Trennung von Datenspeicherung und Rechenleistung (Storage- und Computing-Ressourcen), wodurch Rechenressourcen nur bei Bedarf genutzt werden. Diese Trennung ermöglicht es, große Datenmengen kostengünstig zu speichern und gleichzeitig leistungsstarke Analysen durchzuführen. Durch diese Eigenschaften zielt das Data Lakehouse darauf ab, datengetriebene Entscheidungsprozesse zu vereinfachen, die Flexibilität zu erhöhen und die Kosten zu senken. Dieses Konzept hat daher in den letzten Jahren auch in der Praxis erheblich an Popularität gewonnen.
Whitepaper
Das Data Lakehouse in Databricks und SAP Datasphere – Ein Anwendungsbeispiel
2. Funktionsweise des Data Lakehouse
2.1 Datenkonsistenz und -qualität mit Open-Table-Formaten
Das Data Lakehouse basiert auf einer virtuellen Schicht, die auf Dateien in einem Data Lake zugreift (siehe Abb. 4). Diese Dateien werden in standardisierten, plattformunabhängigen Formaten gespeichert, die für die spaltenbasierte Speicherung großer Datenmengen optimiert sind. Diese offenen und standardisierten Formate ermöglichen eine flexible Datenverwaltung, da sie nicht an eine spezifische Technologie gebunden sind.
Herausforderungen der Standardformate:
Standardisierte Dateiformate haben jedoch Nachteile wie ineffiziente Schreibvorgänge und Probleme mit gleichzeitigen Transaktionen, die zu Dateninkonsistenzen führen können. Um diese Herausforderungen zu bewältigen, werden die Dateien durch eine virtuelle Metadaten-Schicht, das sogenannte Open-Table-Format, angereichert. Diese Metadaten-Schicht bildet das technische Fundament des Lakehouse-Ansatzes und bietet Funktionen, die traditionell nur in klassischen Datenbanken verfügbar sind, und löst damit mehrere Herausforderungen.
Vorteile des Open-Table-Formats:
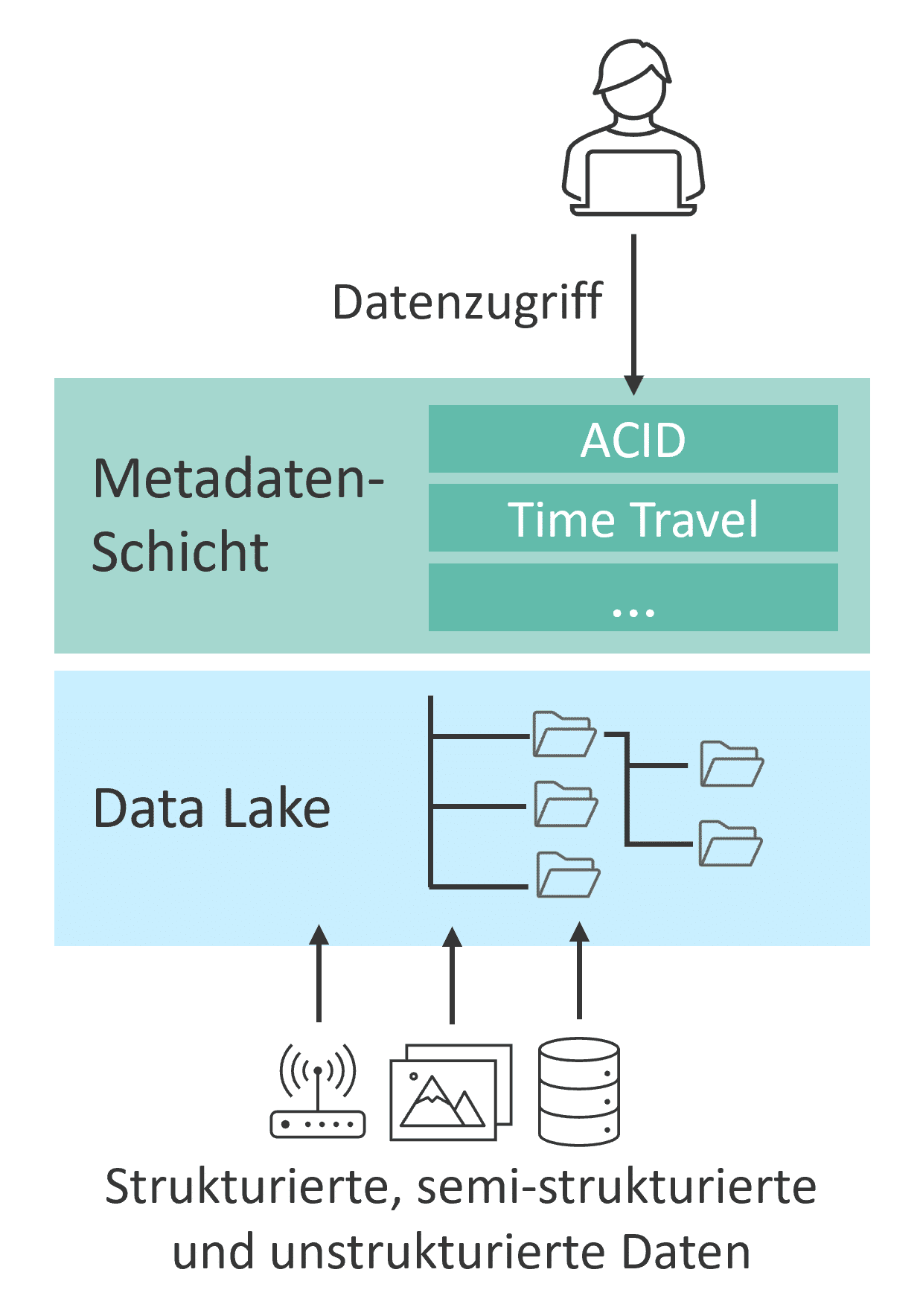
- ACID-kompatible Transaktionen (Atomicity, Consistency, Isolation, Durability): Open-Table-Formate stellen sicher, dass bei Lese- und Schreibvorgängen Transaktionen atomar und isoliert voneinander stattfinden und die Daten zu jeder Zeit konsistent und dauerhaft verfügbar sind. Dies ermöglicht simultanes Arbeiten mehrerer Personen an denselben Tabellen bzw. Dateien. Insofern gewährleisten Open-Table-Formate die Zuverlässigkeit und Integrität der Daten.
- Versionierung und Historisierung („Time Travel“): Änderungen an Tabellen können bis zu einem bestimmten Zeitpunkt zurückverfolgt und frühere Versionen wiederhergestellt werden. Dies verbessert die Nachverfolgbarkeit von Änderungen und erlaubt den Vergleich verschiedener Versionen. Da lediglich Metadaten der Änderungen festgehalten werden, müssen frühere Versionen nicht physisch gespeichert werden.
- Schema-Enforcement und -Evolution: Standardmäßig wird sichergestellt, dass das Schema neuer Daten dem bestehenden Tabellenschema entspricht, um die Konsistenz der Daten zu gewährleisten (“Schema-on-write”). Zudem ermöglicht Schemaevolution flexible Anpassungen des Tabellenschemas (z.B. Hinzufügen neuer Spalten), ohne die Tabelle vollständig neu zu erstellen.
- Partitionsevolution: Partitionen werden als eigene Dateien gespeichert, was Abfragen und Änderungen in bestimmten Partitionen vereinfacht. Neue Zeilen und Spalten können zu den Metadaten hinzugefügt werden, ohne dass die Partitionen neu geschrieben werden müssen, was die Performance optimiert.
- Governance und Metadaten-Management: Ein Transaktionslog, das an den Speicherort der Tabelle geschrieben wird, ermöglicht optimierte Abfragen und Transaktionen durch die Bereitstellung von Metadaten wie Schema und Partitionen.
- Vereinte Batch- und Streaming-Verarbeitung: Open-Table-Formate ermöglichen die Verarbeitung von Echtzeit-Datenströmen und historischen Daten in Mikro-Batches. Dies reduziert den Aufwand für die Verwaltung heterogener Datenpipelines und erleichtert die Bereitstellung von Informationen für die fundierte Entscheidungsfindung in Echtzeit.
- Anbindung von Data Science und Machine Learning: Dank des offenen und standardisierten Zugangs können Machine-Learning-Werkzeuge schnell auf vorhandene Daten zugreifen. Außerdem sind die Daten bereits in einer Form gespeichert, die für gängige Machine-Learning-Bibliotheken lesbar ist.
Leistungsoptimierung und Open-Source-Lösungen
Um eine gute Performance zu gewährleisten, werden viele Metadaten im Cache des Cloudspeichers gehalten, was die Latenz bei Abfragen und Transaktionen reduziert. Bekannte Open-Table-Formate wie Delta Lake, Iceberg und Hudi sind Open-Source und können in Data Lakes und Compute-Diensten von Hyperscalern wie Microsoft Azure, AWS oder Google Cloud Platform verwendet werden. Trotz unterschiedlicher Implementierungen bieten diese Formate ähnliche Leistungsmerkmale.
Diese technischen Grundlagen und Funktionen machen Open-Table-Formate zu einem entscheidenden Bestandteil des Data-Lakehouse-Konzepts, das die Vorteile von Data Lakes und Data Warehouses vereint und so ein effizientes und konsistentes Datenmanagement ermöglicht.
2.2 Daten auf dem Treppchen: Die Medaillenstruktur
Das Data Lakehouse erfordert einen strukturierten Aufbau, um sowohl die nötige Governance zu gewährleisten als auch flexibel auf die Herausforderungen von sich stetig verändernden Datenlandschaften reagieren zu können. Dazu wird im Data Lakehouse eine hierarchische Datenstruktur eingeführt, die zum einen den Anforderungen von Data Scientists zur Datenanalyse und zum anderen den Bedürfnissen von Data-Warehouse-Experten für Reporting- und BI-Anwendungen gerecht wird. Diese Hierarchie wird als Medaillenstruktur (siehe Abb. 5) bezeichnet und wurde ursprünglich von Databricks vorgeschlagen. Sie teilt das Lakehouse in drei Schichten, die verschiedene Datenzustände repräsentieren: roh, aufbereitet und aggregiert. Die Daten durchlaufen diese Schichten von der untersten bis zur obersten, wobei jede Schicht eigene Modellierungskonventionen und Beladungsregeln hat.
Diese Art der Verarbeitung ist keine neue Idee, sondern setzt die Logik von Datentransformationen und ETL-Strecken klassischer Warehouse-Ansätze im Lakehouse um und wird vielen Data-Warehouse-Experten gut bekannt sein.
Die Schichten der Medaillenstruktur:
- Bronze-Layer:
- Funktion: Speicherort für Rohdaten aus verschiedenen Quellen wie ERP- und CRM-Systemen, IoT-Geräten und anderen Datenquellen.
- Charakteristik: Die Daten werden in ihrer ursprünglichen Form und ohne Transformation gespeichert. Die kostengünstige Speicherung im Data Lake ermöglicht die Erfüllung hoher Dokumentationsanforderungen.
- Staging-Layer (optional):
- Funktion: Zwischenstufe zwischen Bronze- und Silver-Layer.
- Charakteristik: Vereinheitlichung und Konvertierung der Rohdaten in das Open-Table-Format, Erhebung zusätzlicher Metadaten und Korrektur offensichtlicher Fehler. Dies erleichtert die Transformation in den Silver-Layer.
- Silver-Layer:
- Funktion: Zentrale Persistenzschicht für transformierte Daten.
- Charakteristik: Daten werden nach harten und ggf. nach Business-Regeln transformiert und in einer harmonisierten Rohschicht (write optimized) gespeichert. Die modulare Struktur der Data-Vault-Modellierung gewährleistet Flexibilität und Skalierbarkeit.
- Gold-Layer:
- Funktion: Abfrageoptimierte Aufbereitung der Daten für Analysen und Berichte.
- Charakteristik: Daten werden denormalisiert und in Dimensionen und Fakten dargestellt, ähnlich wie in klassischen Data Warehouses, um die Erstellung von Analysen und Berichten zu ermöglichen.
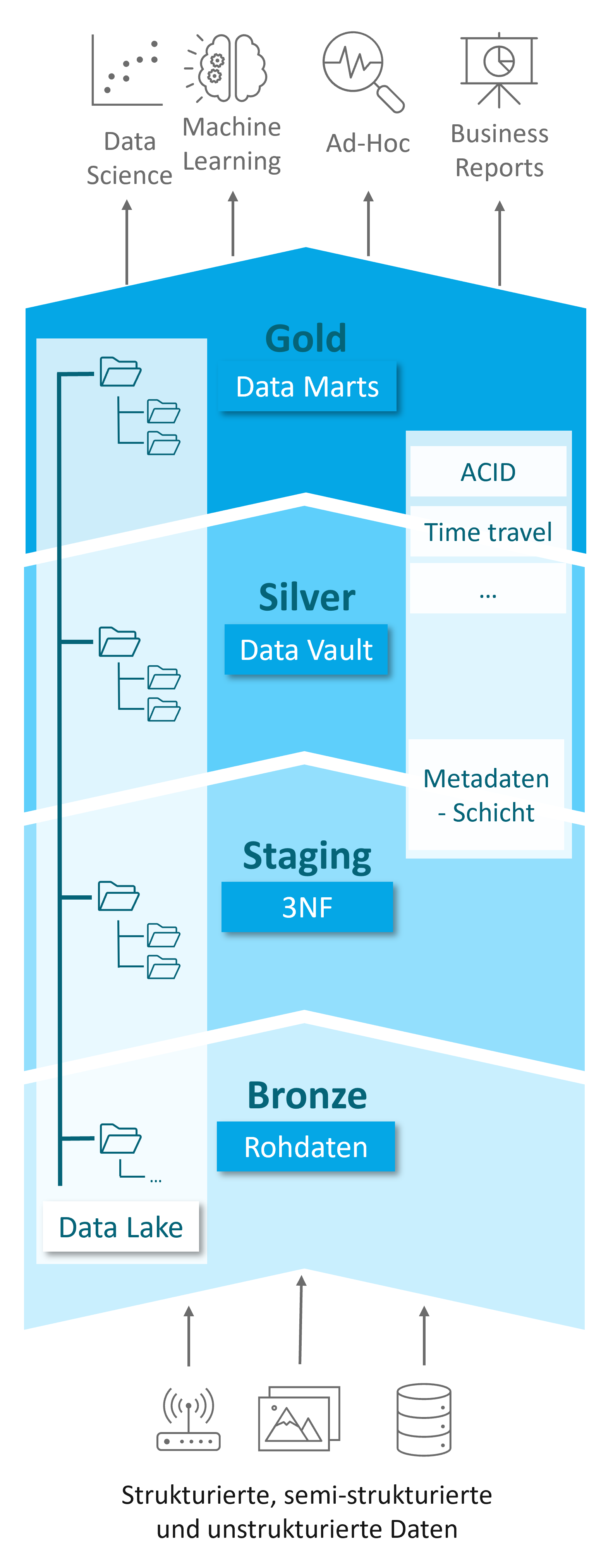
Vorteile der Medaillenstruktur
Die Medaillenarchitektur verleiht dem Data Lakehouse eine Struktur, die modernen Data Warehouses ähnelt und den unterschiedlichen Anforderungen von Data Engineers, Data Scientists, Data-Governance-Spezialisten und Business-Usern gerecht wird. Dank technischer Innovationen wie der Trennung von Rechen- und Speicherressourcen sowie der Verwendung von Open-Table-Formaten liegt die Herausforderung weniger im Aufbau von Beladungsstrecken und Geschäftslogiken, sondern darin, wie diese Innovationen in bestehende Datenstrategien integriert und im Unternehmen optimal genutzt werden können.
3. Fazit
Das Data Lakehouse vereint die Stärken von Data Lakes und Data Warehouses, indem es flexible, kosteneffiziente und leistungsstarke Datenverarbeitung ermöglicht. Die Trennung von Datenspeicherung und Rechenleistung kann zur effizienteren Nutzung von Cloud-Ressourcen und Kostensenkungen beitragen.
Open-Table-Formate gewährleisten Datenkonsistenz und -qualität durch ACID-kompatible Transaktionen, Versionierung, Schema-Enforcement und die Unterstützung für Batch- und Streaming-Verarbeitung. Die Medaillenstruktur (Bronze-, Silver- und Gold-Layer) sorgt für eine klare Datenorganisation, die den Anforderungen sowohl von Data Scientists als auch von Data-Warehouse-Experten gerecht wird. Gleichzeitig erfordert die Implementierung eines Data-Lakehouse-Ansatzes in Unternehmen eine sorgfältige Planung, um die Anforderungen an Konsistenz, Zugänglichkeit und Governance der Daten zu erfüllen und von den Chancen des Ansatzes zu profitieren.
Whitepaper
Das Data Lakehouse

Autor: Damian Garrell & Martin Peitz
Ihr Ansprechpartner

Christopher Kampmann
Head of Business Unit
Data & Analytics
christopher.kampmann@isr.de
+49 (0) 151 422 05 448


