In einigen Planungsszenarien wird die Planung auf „nicht gebuchten“ Entitäten/Merkmalen gefordert. Diese Anforderung kann weiter verkompliziert werden, wenn die Notwendigkeit besteht nur bestimmte Kombinationen der Entitäten zuzulassen (im SAP-Kontext wird dafür häufig der Begriff „Merkmalskombinationen“ verwendet). SAP Analytics Cloud (SAC) bietet diverse Möglichkeiten diese Anforderung umzusetzen.
In der Regel werden bei Planungsszenarien historische IST-Daten herangezogen, die nicht nur als Richtwerte/Vorschlagswerte für die zukünftige Planung dienen, sondern gleichzeitig auch den Aufriss bzw. die zulässige Kombination von Entitäten (z.B. unterschiedliche Kunden für unterschiedliche Verkaufsorganisationen) vorgeben. In manchen Planungs-Szenarien sind IST-Daten allerdings nicht verfügbar, die Planungsmasken sollen aber trotzdem nur bestimmte Kombinationen von Entitäten für die Eingabe zulassen.
SAP Analytics Cloud bietet an dieser Stelle mit Hierarchien, Dimensions-Attributen („Benutzerdefinierten Eigenschaften“) und Validierungsregeln bereits „Out-Of-The-Box“ Funktionalitäten, um diese Anforderung abzudecken, die in diesem Beitrag beleuchtet werden sollen. Zusätzlich wird eine simple Eigenentwicklung mit Hilfe von „Data Actions“ erläutert, die zusätzlich Vorteile zu den Standardfunktionalitäten der SAP mit sich bringt.
Anforderungsdefinition
Wie in der Anleitung bereits beschrieben, besteht die Anforderung darin, nur bestimmte Kombinationen von Entitäten für die Planung zuzulassen. Ungültige Entitätskombinationen dürfen nicht geplant und sollen im besten Fall gar nicht dargestellt werden. Für das Planungsszenario sind keine historischen Daten vorhanden.
Als Beispiel soll im Folgenden die Kombination von 3 fiktiven Entitäten dienen:
- Verkaufsorganisation (SALES_ORG)
- Kundengruppe (CUSTOMER_GROUP)
- Kunde (CUSTOMER)
Nur folgende Kombinationen sollen für diese 3 Entitäten erlaubt werden:
| Verkaufsorganisation | Kundengruppe | Kunde |
|---|---|---|
| 1000 | A | 1001 |
| 1000 | A | 1002 |
| 1000 | B | 1003 |
| 2000 | A | 2001 |
| 2000 | C | 2002 |
| 2000 | C | 2003 |
Umsetzung SAC
Ausgangsszenario
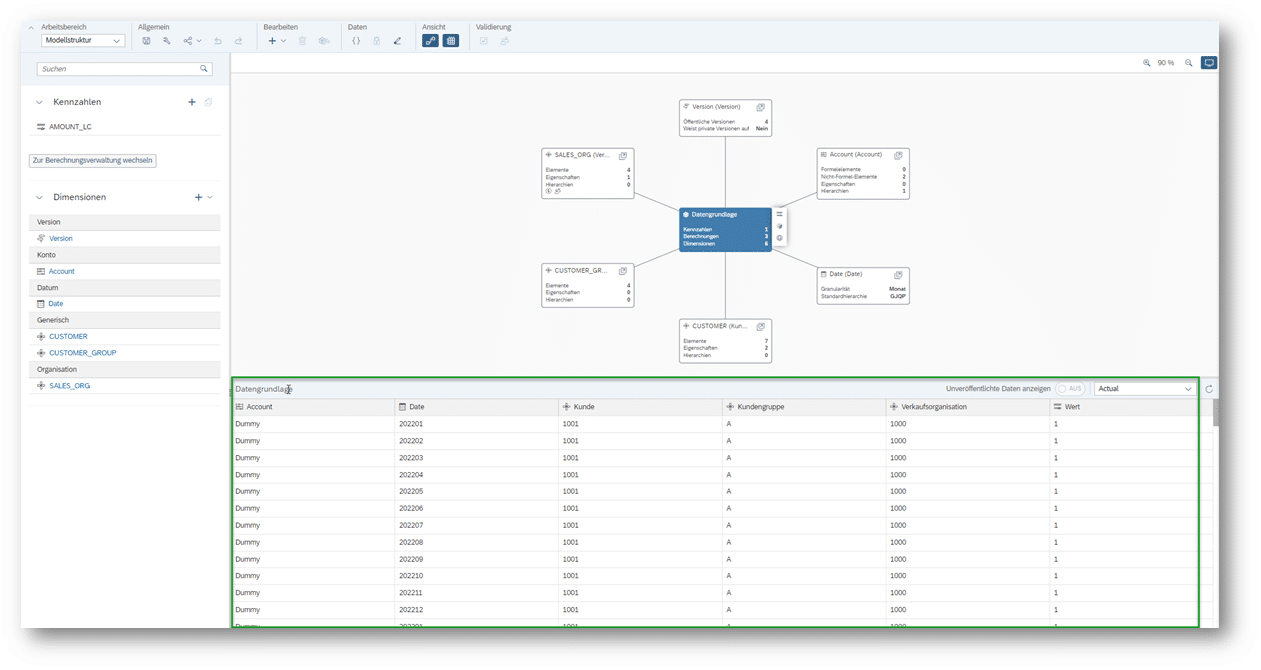
Für die Umsetzung der Anforderung wird im ersten Schritt ein SAC-Planungsmodell wie folgt definiert:
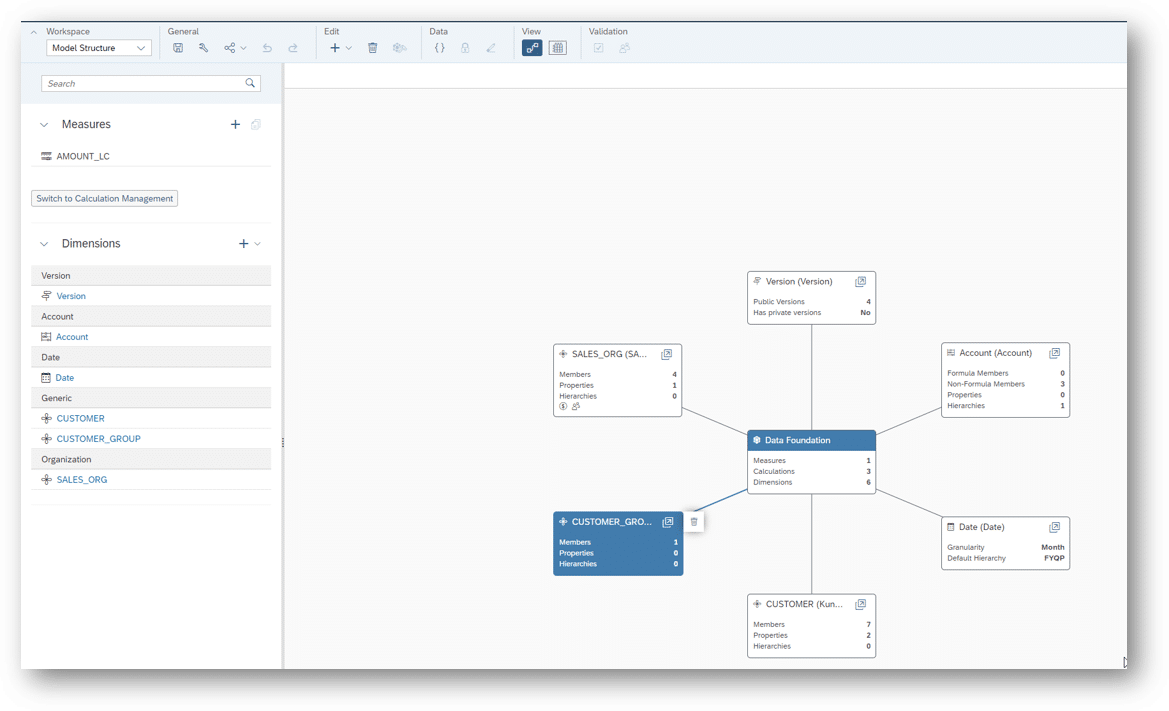
Dabei handelt es sich in um ein kontenbasiertes (Account-Dimension) Planungsmodell. Ein Kennzahlenbasiertes Planungsmodell wäre für das in diesem Beitrag beschriebene Vorgehen aber genauso denkbar.
Die Dimensionen (generischer Typ), die für die Kombinationen verwendet werden, haben folgende Ausprägungen:
| Dimension | Member ID |
|---|---|
| Verkaufsorganisation | 1000 |
| 2000 | |
| Kundengruppe | A |
| B | |
| C | |
| Kunde | 1001 |
| 1002 | |
| 1003 | |
| 2001 | |
| 2002 | |
| 2003 |
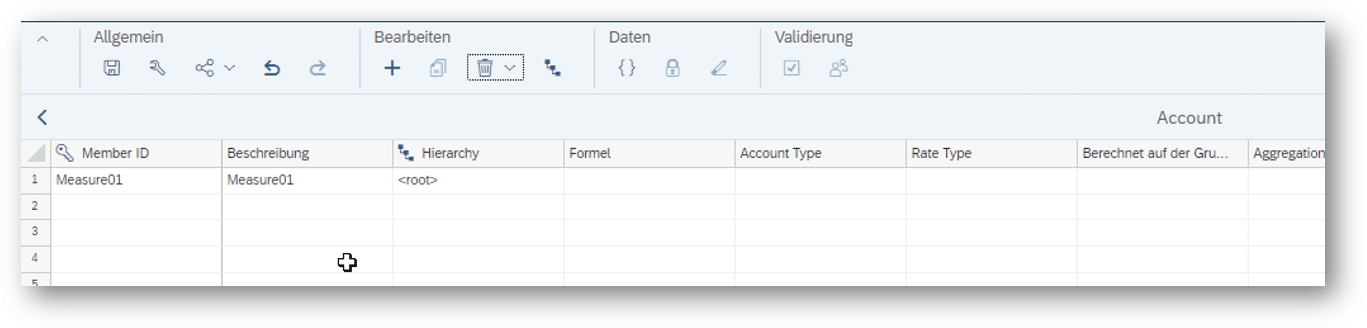
Die Account Dimension hat nur eine Beispielausprägung, die geplant werden soll:
Basierend auf dem oben definierten Modell wird eine Story mit einer Planungs-Tabelle und den 3 Dimensionen Verkaufsorganisation, Kundengruppe, Kunde im Aufriss definiert. Alle 3 Dimensionen bekommen die Einstellung „Nicht gebuchte Daten“:
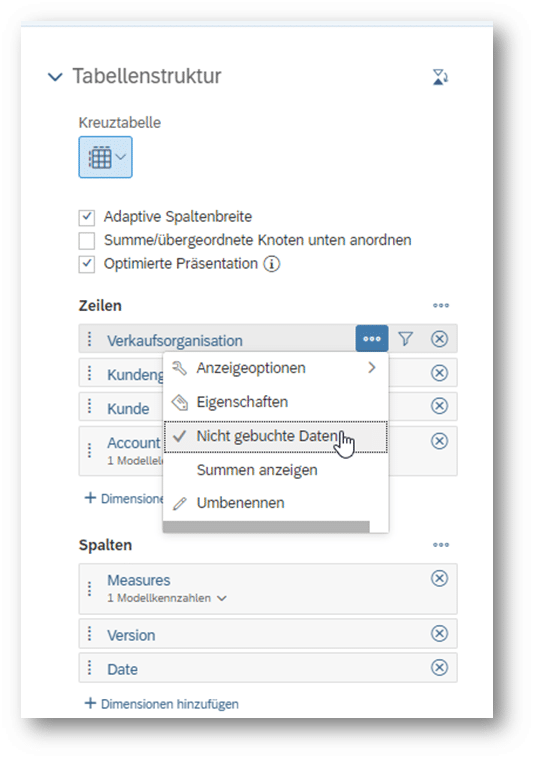
Wie zu erwarten, bildet die SAC ein Kreuzprodukt über alle Kombinationen der 3 Dimensionen. Das entspricht nicht der Anforderung, dass nur bestimmte Kombinationen für die Planung zur Verfügung stehen sollen:
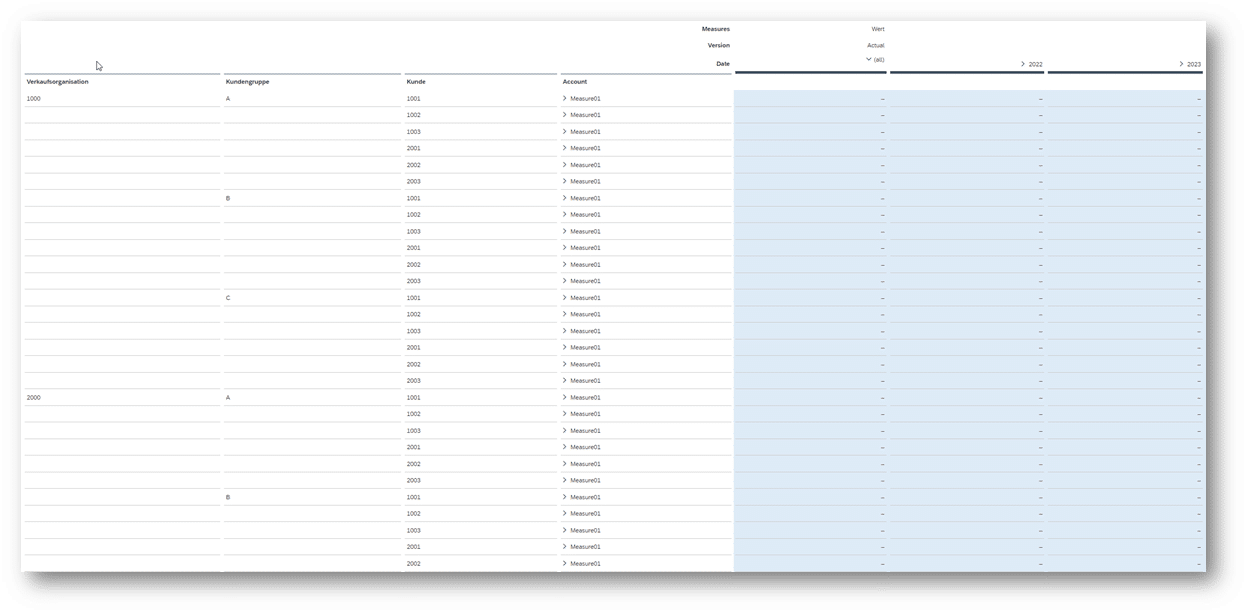
Problemlösung
Eine Möglichkeit die Anforderung umzusetzen, wäre die Verwendung von Hierarchien. Damit würden allerdings nur die Stories korrekte Kombinationen erlauben, die diese Hierarchie verwenden. Eine Story mit flacher Darstellung könnte weiterhin ungültige Kombinationen erlauben.
Validierungsregeln auf Basis „Benutzerdefinierter Eigenschaften“
Neben Hierarchien bietet die SAC mit „Benutzerdefinierten Eigenschaften“ eine weitere Möglichkeit an, Beziehungen zwischen Entitäten (Dimensionen) zu modellieren. „Benutzerdefinierte Eigenschaften“ haben den Vorteil, dass Sie nicht nur z.B. als Filter in Stories dienen können, sondern auch Basis für die Definition von Validierungsregeln sein können. Validierungsregeln verhindern bereits auf Modell-Ebene die Speicherung ungültiger Kombinationen.
An der Dimension Kunde (CUSTOMER) werden daher zwei „Benutzerdefinierte Eigenschaften“ („Verkaufsorganisation“ und „Kundengruppe“) definiert (Punkt 1 im Screenshot) und die Beziehungen entsprechend in die Stammdaten-Tabelle eingetragen (Punkt 2 im Screenshot).
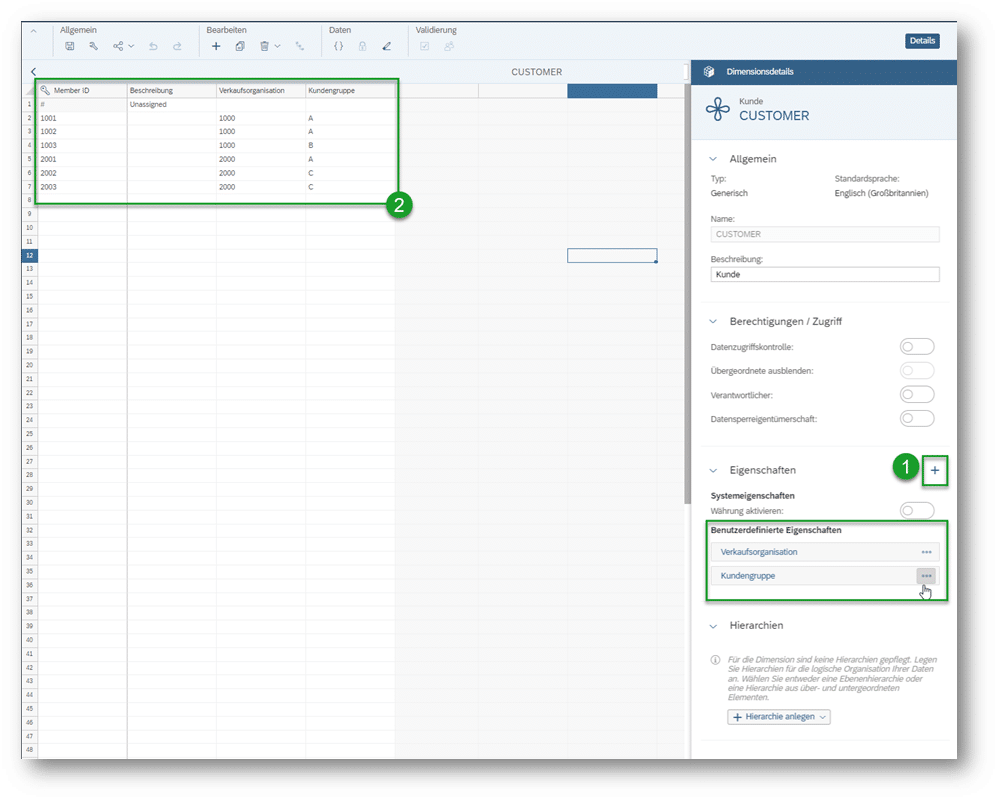
An dieser Stelle sei vollständigkeitshalber angemerkt, dass der Aufriss mit Hilfe der definierten Stammdaten jetzt auch so gestaltet werden könnte, dass nur die Dimension „Kunde“ in den Aufriss aufgenommen und die Eigenschaften „Verkaufsorganisation“ und „Kundengruppe“ lediglich als zusätzliche Informationen angezeigt werden könnten. Damit würde man auch die gewünschte Kombinatorik zumindest anzeigen können:

Die Eingabedaten würden physisch nur auf der Dimension „Kunde“ geschrieben werden. Mit Hilfe von Validierungsregeln und/oder selbstdefinierten „Data Action“ könnten die beiden Eigenschaften „Verkaufsorganisation“ und „Kundengruppe“ abgeleitet und ebenfalls persistiert werden. Da die Dimensions-Eigenschaften aber keinen „vollwertigen“ Dimensionen entsprechen und sich dadurch diverse Einschränkungen ergeben (u.a. keine Ad-Hoc Filterung, keine Darstellung von Texten zu den IDs, keine Sortiermöglichkeit) wird dieser Lösungsansatz hier nicht weiter betrachtet. Der im Folgendem beschriebene Lösungsansatz nutzt wie bereits im Ausgangsszenario dargestellt alle 3 Dimensionen für den Aufriss.
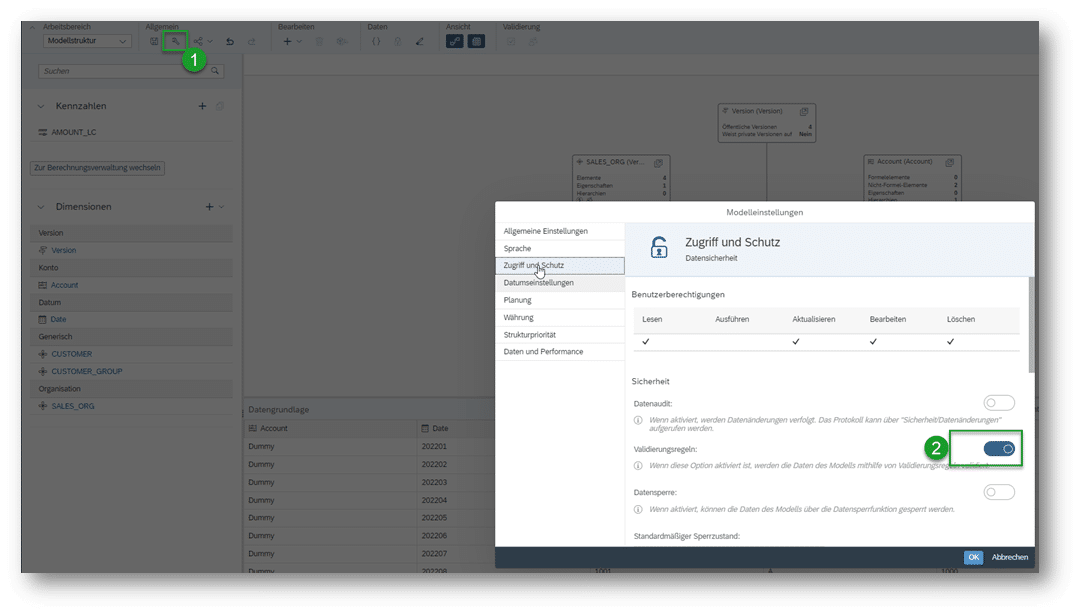
Basierend auf den oben definierten Stammdaten werden im ersten Schritt die Validierungsregeln erstellt. Diese müssen zuerst in den Modell-Eigenschaften aktiviert werden:
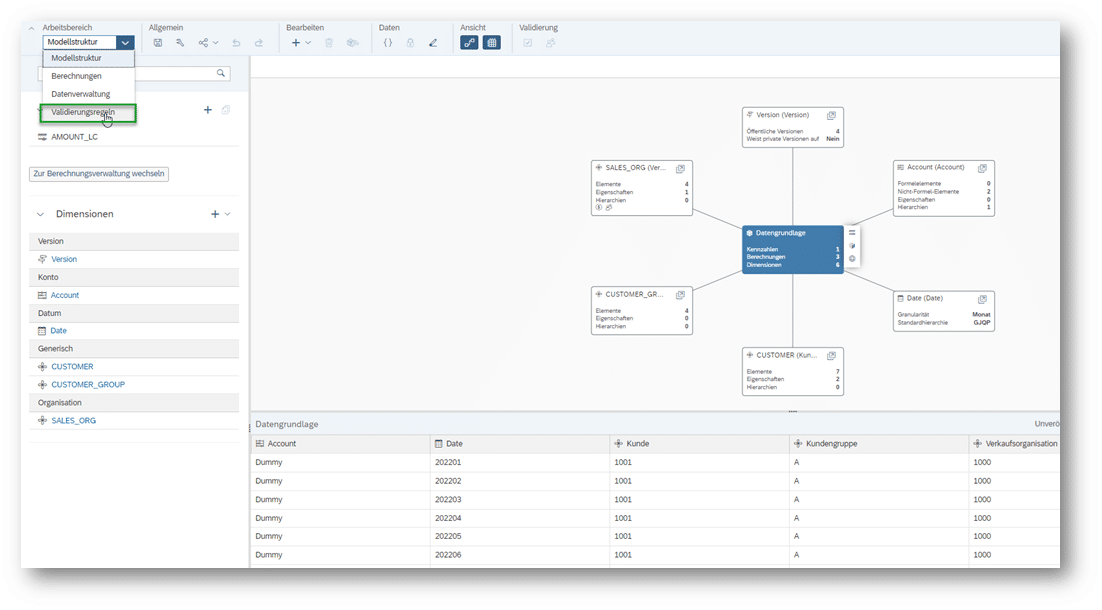
Nach der Aktivierung sind die Validierungsregeln hier zu finden:
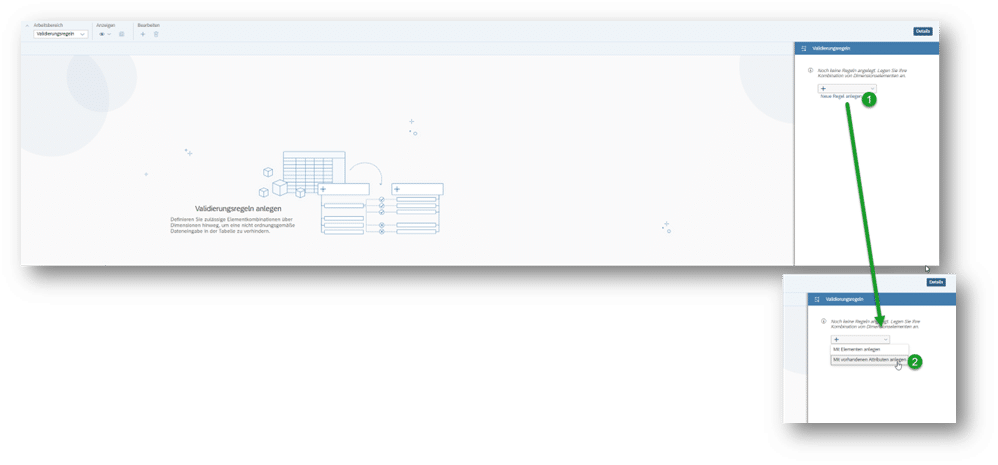
Nun können die Validierungsregeln mit der Option „Mit vorhandenen Attributen anlegen“ definiert werden:
Das Mapping sollte am Ende wie folgt aussehen:
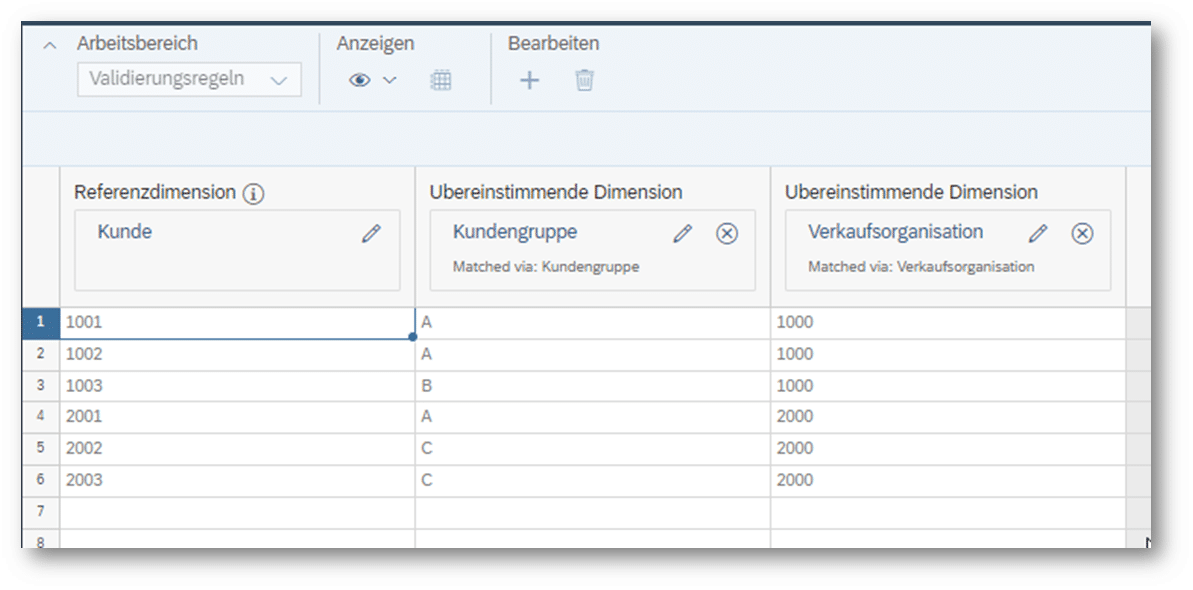
Willkommenes Feature: Die Validierungsregeln werden automatisch bei Anpassung der Stammdaten („Benutzerdefinierten Eigenschaften“) auf den sie basieren, aktualisiert 👍
Wird die oben definierte Story noch mal aufgerufen, sind jetzt die ungültigen Kombinationen für die Eingabe gesperrt (nur die blau markierten Felder sind eingabebereit):
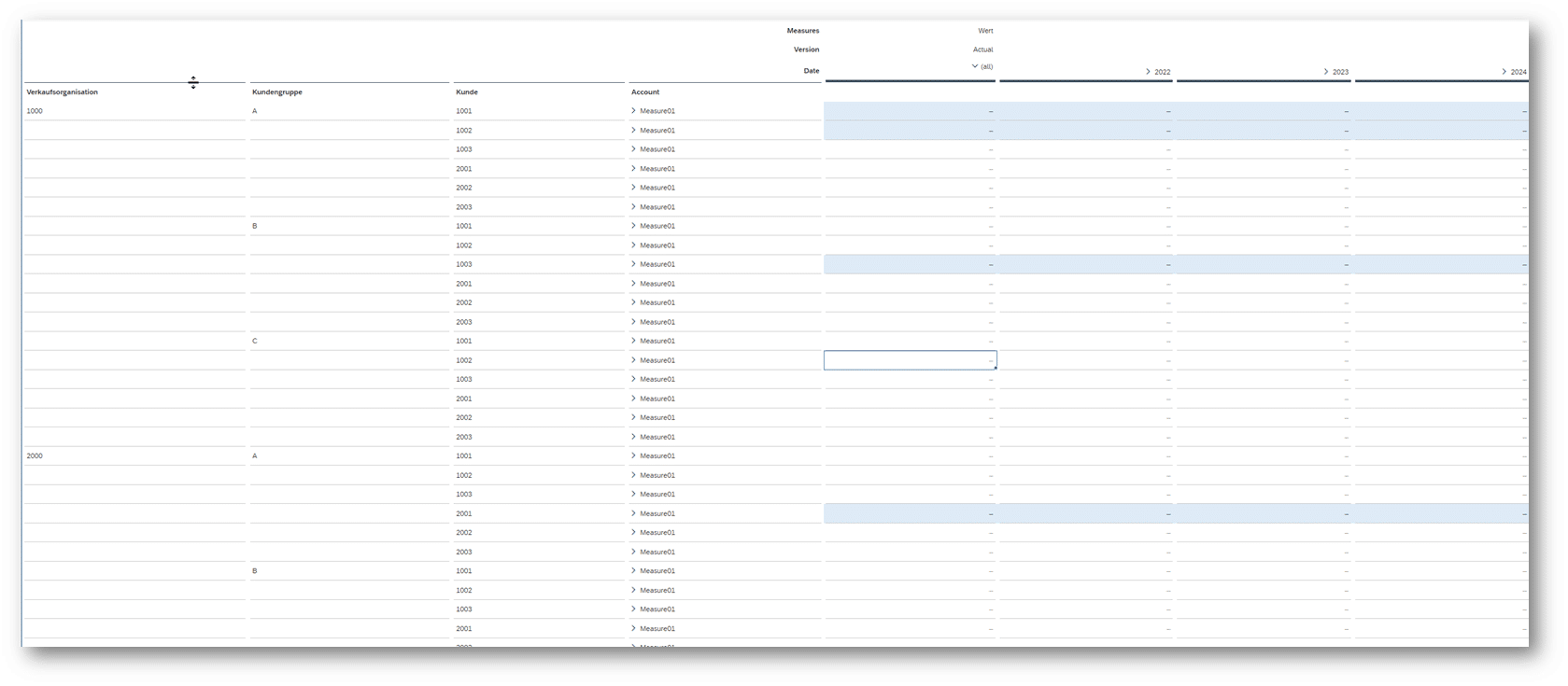
Optimierung der Planungsmaske mit Hilfe eines „Planungsgrids“
Jetzt muss noch der Aufriss entsprechend um die ungültigen Kombinationen „bereinigt“ werden.
Dazu könnte auch wieder eine hierarchische Darstellung verwendet werden. Damit würde man die Beziehungen aber an zwei Stellen pflegen müssen, als „Benutzerdefinierte Eigenschaften“ der Dimension Kunde und noch einmal als Hierarchie.
Eine andere Möglichkeit ist es, ein „Planungsgrid“ auf Basis der hinterlegten Attribute mit Hilfe einer selbstdefinierten „Data Action“ aufzuspannen, so dass später in der Planungsmaske wieder auf gebuchten „Dummy“ Daten geplant werden kann.
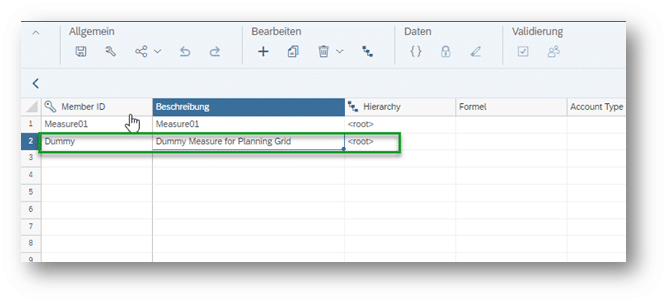
Dazu wird zunächst ein Dummy-Account in der Dimension Account angelegt:
Anschließend wird folgende „Data Action“ vom Typ „Script“ implementiert:
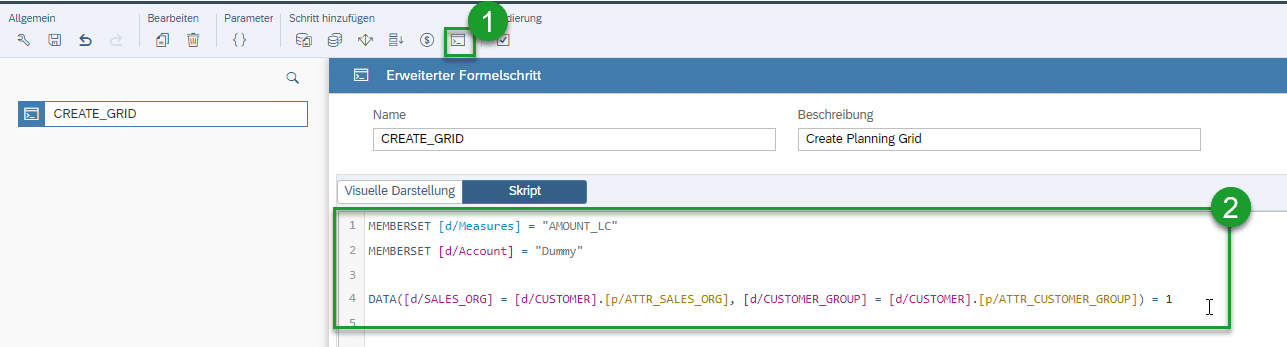
MEMBERSET [d/Measures] = „AMOUNT_LC“
MEMBERSET [d/Account] = „Dummy“
DATA([d/SALES_ORG] = [d/CUSTOMER].[p/ATTR_SALES_ORG], [d/CUSTOMER_GROUP] = [d/CUSTOMER].[p/ATTR_CUSTOMER_GROUP]) = 1
Diese „Data Action“ erstellt wie oben beschrieben anhand der hinterlegten Entitäts-Kombinationen der Dimension Kunde die entsprechenden Zeilen in der Fakten-Tabelle mit dem „Dummy“-Wert 1 (es kann auch jeder andere beliebige Wert verwendet werden).
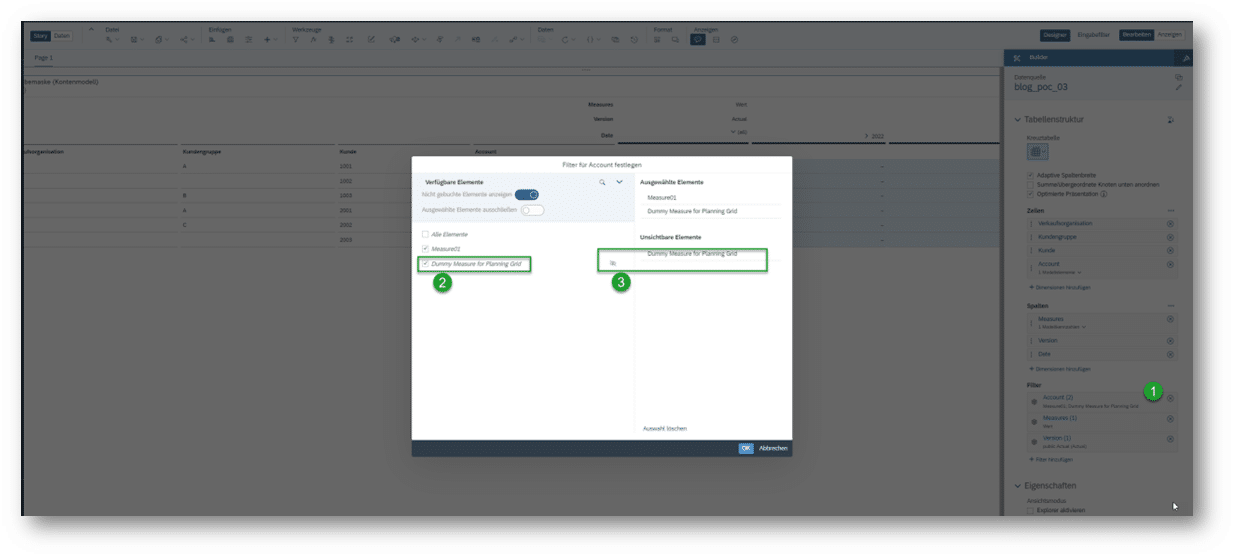
Die „Dummy“ Ausprägung wird nun für die Account-Dimension in der Tabelle der Story hinzugefügt und kann auch gleich ausgeblendet werden, denn sie soll lediglich das „Planungsgrid“ aufspannen.
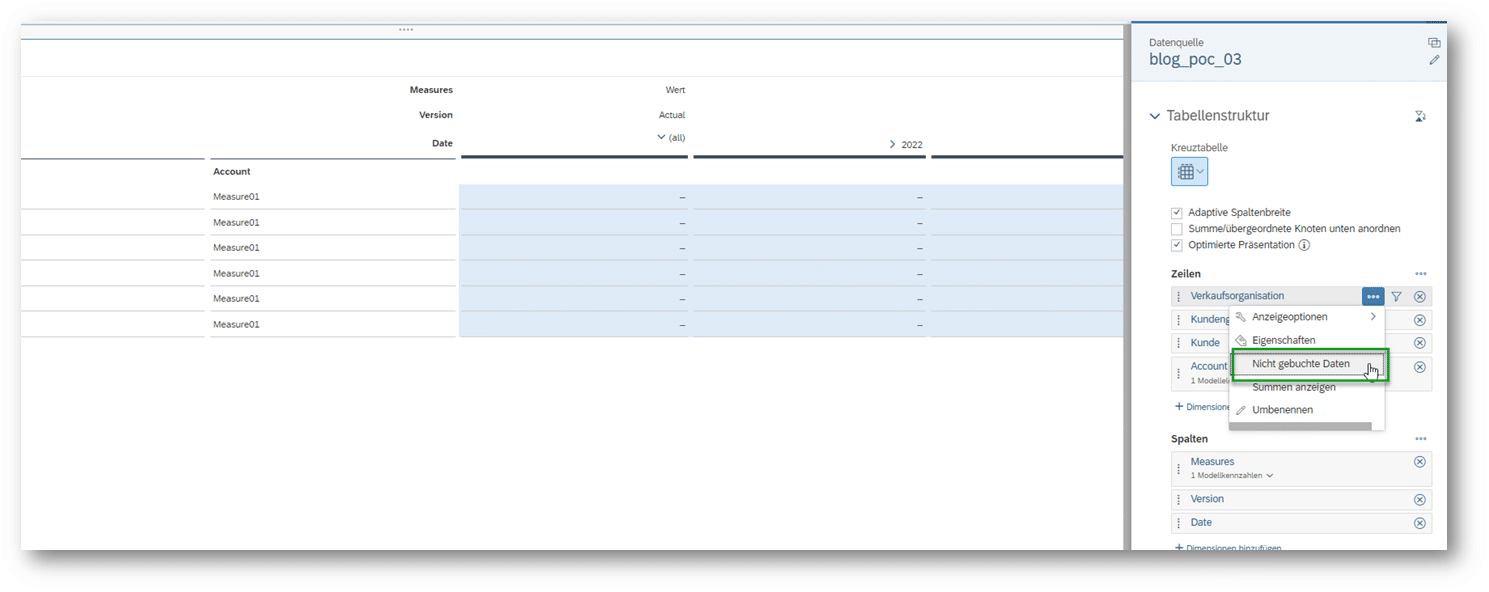
Als letzten Schritt muss die Eigenschaft „Nicht gebuchte Daten“ für die 3 Dimensionen wieder deaktiviert werden.
Nun zeigt die Tabelle in der Story wie gefordert nur die erlaubten Kombinationen an:
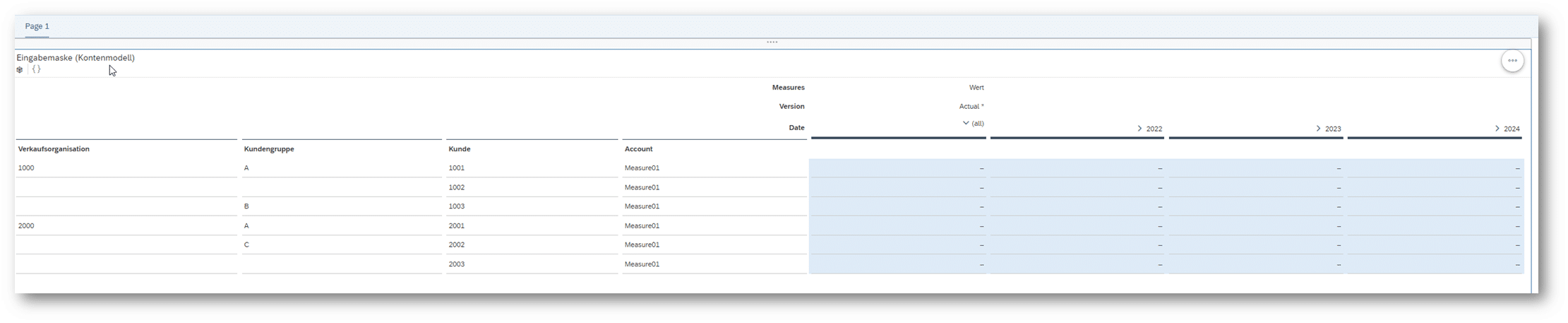
Dass die Planung jetzt auf gebuchten „Dummy“ Werten basiert, hat auch weitere Vorteile z.B. bei der Filterung, dieser Aspekt wird in diesem Blog allerdings nicht weiter vertieft.
Fazit
Wie anhand des oben dargestellten Umsetzungs-Beispiels gezeigt werden konnte, bietet die SAC bezüglich der Anforderung auf „nicht gebuchten“ Entitäts-Kombinationen zu planen diverse Möglichkeiten an. Vor allem die Funktion „Benutzerdefinierte Attribute“ an einer Dimension zu definieren, stellt sich in diesem Kontext als sehr hilfreich heraus. So konnte im Beispiel durch Validierungsregeln nicht nur auf Modell-Ebene sichergestellt werden, dass nur die in den Attributen vorhanden Kombinationen geplant werden können. Die gleichen Attributs-Informationen konnten auch verwendet werden, um mit Hilfe einer selbstdefinierten Data Action ein „Planungsgrid“ zu spannen, so dass die Eingabemaske nur die gültigen Entitäts-Kombinationen für die Anzeige zur Verfügung stellt.
Autor: Michael Wilk
Ihr Ansprechpartner

Thomas Riedel
Managing Consultant
SAP Information Management
Thomas.Riedel@isr.de
+49 (0) 151 422 05 422


