In unserer Praxisreihe agiles SAP HANA SQL Data Warehousing haben wir Ihnen im ersten Teil einen umfangreichen Einblick in die Möglichkeiten der agilen Entwicklung des SAP HANA SQL Data Warehouse gegeben.
Im zweiten Teil unserer Serie möchten wir uns intensiver mit dem Aspekt Continuous Integration beschäftigen. Neben einer kurzen theoretischen Einordnung des Begriffs soll dabei, ganz in Sinne der Reihe, der Praxisbezug im Vordergrund stehen. Wir möchten Ihnen vermitteln, was Continuous Integration beim Aufbau des SAP HANA SQL DWH genau bedeutet, wie es umgesetzt wird und welche Vorteile sich ergeben.
Teil 2: Continuous Integration (CI)Was ist Continuous Integration?Continuous Integration (Kontinuierliche Integration, CI) ist ein… Mehr
Teil 3: Continuous Delivery (CD)Was ist Continuous Delivery?Continous Delivery (kontinuierliche Lieferung, CD) baut auf… Mehr
Teil 4: Continuous Testing (CT)
Teil 5: Continuous Feedback
1 Theoretische Einführung Continuous Integration
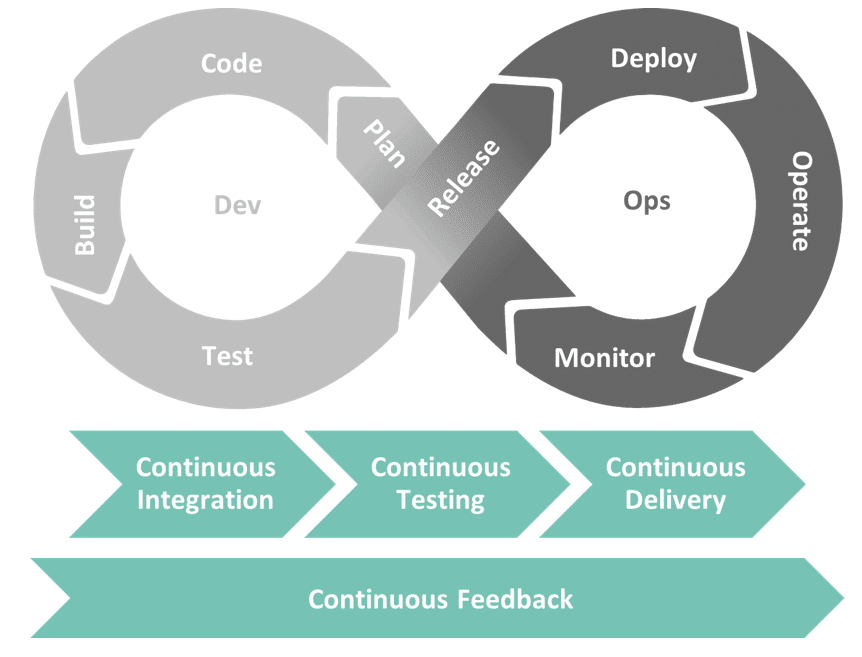
Continuous Integration (Kontinuierliche Integration, kurz CI) ist ein Prozess der Softwareentwicklung, der mit Aufkommen der Ansätze zur agilen Softwareentwicklung Ende der 1990er Jahren stetig an Bedeutung gewonnen hat. Heute wird er vor allem mit der DevOps-Philosophie verbunden, die auf eine Beschleunigung und Automatisierung der Aufbau- und Ablauforganisation zur Erstellung produktiver Software hinwirkt. In DevOpsWas ist DevOps?Der Begriff DevOps setzt sich aus den Wörtern… Mehr ist Continuous Integration ein zentraler Bestandteil der ganzheitlichen Betrachtung der Arbeitsschritte Development (Entwicklung) und Operations (Betrieb). Im Phasenmodell von DevOps sichert es als einer von vier Kontinuitätsprozessen das Ineinandergreifen der Phasen des Bereichs Development (Abb. 1.1). Dieser ist heute in der Regel durch die Arbeit mehrerer Entwickler oder Entwickler-Teams an einem Produkt geprägt. Continuous Integration soll in einer solchen Situation für die Integrität und Stabilität des gesamten Quellcodes sorgen, damit dieser in bestmöglicher Form in den nachgelagerten Bereich Operations überführt werden kann, in dem er durch Continuous Delivery in einen produktiven Zustand versetzt wird.
Abb. 1.1: DevOps-Phasen und Kontinuitätsprozesse | isr.de
1.1 Elemente
Für Continuous Integration sind im Wesentlichen drei funktionale Elemente von Bedeutung:
1.1.1 Branching
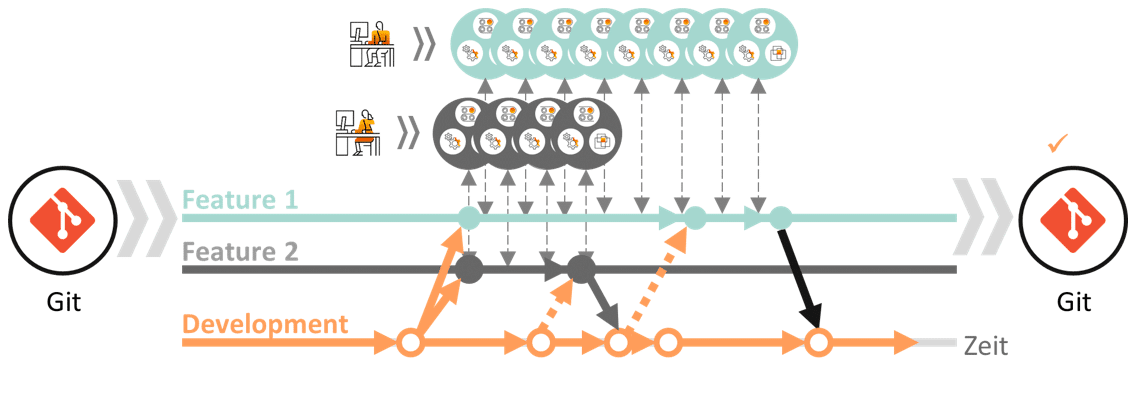
Das parallele Arbeiten am Quellcode muss in einer Weise organisiert werden, die sowohl komfortabel für den einzelnen Entwickler ist als auch das Zusammenfügen der verschiedenen Code-Bestandteile möglichst einfach gestaltet. Ein Konzept, dass sich hierzu etabliert hat, ist das Branching (Verzweigen), dass mithilfe von Versionskontrollsystemen (näher in 1.2 Tools), die zum Management des Quellcodes genutzt werden, umgesetzt wird. Beim Branching wird entsprechend des Bildes eines Baums, der Hauptstamm des gemeinsamen Quellcode in verschieden Feature-Branches verzweigt und es entstehen untergeordnete Quellcode-Repositories. Auf diesen Arbeiten die einzelnen Entwickler, in dem sie sich eine Kopie des übergeordneten Branch ziehen (Pull) und auf diesem isoliert Arbeiten können. Am Ende muss die bearbeitete Version in den gemeinsamen Entwicklungsstand eingepflegt werden (Merge). Für die genaue Ausgestaltung des Branching kann es individuelle Ansätze geben. Abb. 1.2 zeigt eine simple Form mit zwei Feature-Branches, die in den Development-Branch des gesamten Projektes integriert werden. Continuous Integration reicht konzeptionell nur bis zur Zusammenführung in einem gemeinschaftlichen Entwicklungsbereich. Der Fokus liegt dabei auf der Integration von neuen Veränderungen in eine bestehende Entwicklung. Branches für Qualitiätssicherung oder Produktivsysteme unterliegen dem Continuous Delivery (CD), wobei CD die Konzepte von Continuous Integration im Hintergrund mitberücksichtigt.
Abb. 1.2: Branching und Continuous Integration
1.1.2 Tests
Ein entscheidender Punkt bei der erfolgreichen Durchführung von CI ist umfangreiches Testen. Aus der Struktur des Branching ergibt sich bereits, dass Codebestandteile bei der Überführung in einen übergeordneten, gemeinschaftlichen Stand überprüft werden müssen. So können die vorgenommenen Veränderungen in sog. Unit-Tests für sich genommen auf dem lokalen Branch geprüft werden. Dazu wird eine temporäre Systemlandschaft mit allen benötigten Abhängigkeiten aufgebaut, um ein Zielsystem zu simulieren, in dem CI-Tests durchgeführt werden. Der Logische Prozess folgt dabei dem Leitsatz Create-Deploy-Test-Destroy. Darüber hinaus können durch das Versionskontrollsystem alle Code-Unterschiede zwischen zwei Versionen übersichtlich dargestellt werden. In diesem Blog wollen wir auf dieses Thema allerdings nicht vertieft eingehen. CI offenbart hier eine große Schnittmenge mit dem Prozess Continuous Testing (Kontinuierliches Testen), auf das wir in einem spezifischen Blog der Reihe genauer eingehen werden.
1.1.3 Automatisierung
DevOps hat den Anspruch möglichst viele repetitive Aufgaben auf dem Weg zur Auslieferung produktiver Software zu automatisieren. Für Continuous Integration bedeutet dies, dass der Fluss des Quellcodes zwischen den Branches im Entwicklungsbereich sowie die benötigten Tests weitgehend automatisch ablaufen. Möglich wird dies durch ein Zusammenspiel des Versionskontrollsystems und speziellen Build Servern (s. 1.2 Tools), die auf Veränderungen der Quellcode-Versionen reagieren, den Quellcode in Software umsetzen und dabei zuvor definierte Tests durchführen. Durch dieses Vorgehen kann automatisiert und vor allem bevor eine Veränderung des gemeinschaftlichen Entwicklungsstandes stattfindet, sichergestellt werden, dass die Neuentwicklung sich fehlerlos in die bestehende Software integrieren lässt. Insgesamt lassen sich so bestimmte Qualitätskriterien definieren, die zur Integration einer Änderung erfüllt sein müssen und automatisch geprüft werden.
1.2 Tools
DevOps und Continuous Integration sind stark Tool-gestützte Ansätze. Für CI sind zwei Werkzeuge besonders hervorzuheben:
Versionskontrollsysteme
Build Server
1.2.1 Versionskontrollsysteme
Von zentraler Bedeutung für CI ist ein Versionskontrollsystem (Version Control Systems), kurz VCS. Durch eine sehr effiziente Form des Branching sind gegenwärtig vor allem verteilte Systeme, allen voran solche der Git-Technologie, beliebt. Die Git-Technologie wurde vom Linux-Vater Linus Torvald entwickelt und macht die oben beschriebenen Funktionen von Continuous Integration umfassend möglich. Git gibt es als Open-Source und in kommerziellen Versionen, zum Beispiel Github, Gitlab oder Bitbucket. Andere verteilte VCS, wie Mercurial, sind in der Praxis weit weniger verbreitet. Git gilt heute als Standard für die Versionskontrolle und den Revisionsschutz in der Softwareentwicklung. Sämtliche Änderungen an Objekten sind nachverfolgbar, auf Events innerhalb des VCS kann reagiert werden und die Nutzer werden bei der Zusammenführung von zeitlich unterschiedlichen Versionsständen unterstützt.
1.2.2 Build Server
Ein Buildserver ist eine Software, die in der Lage ist, Quellcode zu kompilieren, in vorgesehene Softwareumgebungen auszuliefern und dabei definierte Testskripts auszuführen. Dadurch wird es möglich standardmäßige Routinen und wiederkehrende Aufgaben zu automatisieren. Im Falle von Continuous Integration gehören hierzu das Ausführen zusammengeführter Softwarestände und die Durchführung definierter Tests. Die Automatisierung wird herbeigeführt, in dem der Build Server auf Veränderungen in einem VCS reagiert und den Quellcode verarbeitet und ausführt (Build). Auf diese Weise kann auf definierten Branches unmittelbar ein Build erfolgen und die Ausführbarkeit entwickelter Software in einer spezifischen Umgebung getestet werden. Das Testen wird durch die Möglichkeit der parallelen Ausführung von zuvor definierten Testskripten noch erweitert und kann individuell für verschiedene Branches gesteuert werden. Das populärste CI-Tool ist die Open-Source-Software Jenkins. Es gibt aber auch weitere Lösungen wie Bamboo oder Apache Maven.
1.3 Vorteile
Die Vorteile von Continuous Integration entsprechen in hohem Maße denen, die agilen Ansätzen der Softwareentwicklung oder der DevOps-Philosophie insgesamt zugeschrieben werden. Spezifisch ergeben sich folgende Punkte:
Ein Hauptvorteil und vorrangiges Ziel von CI ist die Beschleunigung des Entwicklungsprozesses. Durch die häufige Integration des parallel erarbeiteten Quellcodes in Verbindung mit der unmittelbaren Ausführung und spezifischen Test wird schneller ein operativer Entwicklungsstand erreicht.
Die Qualität der Entwicklung steigt, da Fehler frühzeitig erkannt werden und in diesem Stadium schnell und einfach korrigiert werden können, da die Entwickler gedanklich noch bei der gegenwärtigen Problemstellung sind.
Die Auslieferfähigkeit einer Entwicklung wird sichergestellt und somit das Risiko einer fehlerhaften Auslieferung minimiert.
Das Risiko schwerwiegender Fehlerketten wird minimiert.
Nach dem Aufbau der CI-Infrastruktur richtet sich der Fokus der Entwickler auf die zentral wertschöpfende Tätigkeit der Erstellung von Quellcode und Software. Der Mehrwert der Entwicklung für den Anwender steigt in der Folge kontinuierlich (Continuous Value).
Das Arbeiten von geographisch verteilten Entwicklerteams wird erleichtert.
Die verwendeten Tools generieren viele Metriken, die die Projektsteuerung erleichtern und detaillierte Aussagen über die Qualität, den Nutzen und die Effizienz der entwickelten Software zulassen.
2 Continuous Integration im SAP HANA SQL Data Warehouse
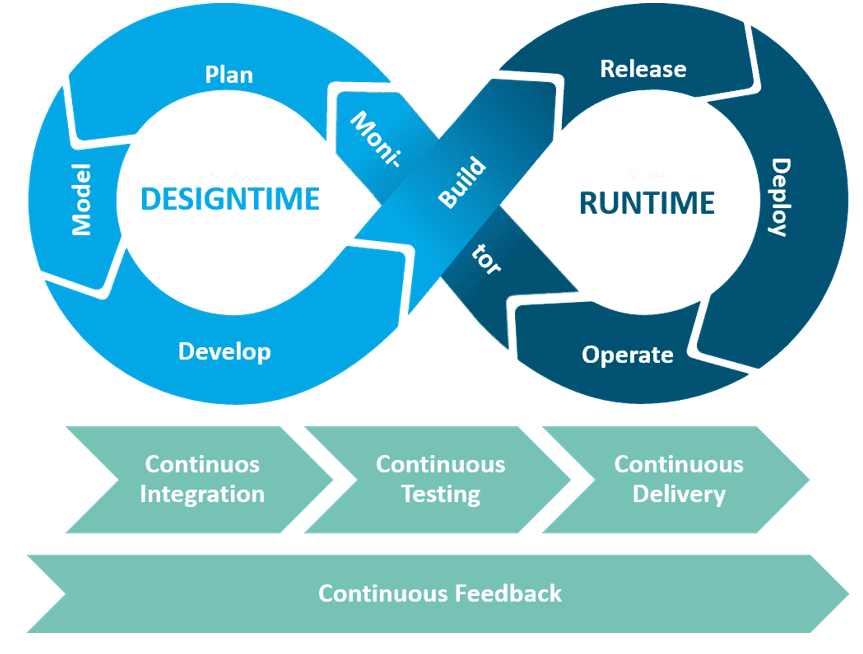
Das SAP HANA SQL Data Warehousing ist eine von drei Möglichkeiten, die SAP zum Aufbau und Betrieb eines Data Warehouse bietet. Bei dieser Variante wird auch vom nativen HANA-Ansatz gesprochen, da die SAP-HANA-Plattform als leistungsstarke SQL-Datenbank mit integriertem Anwendungsserver unmittelbar zum Data Warehousing genutzt wird (weitere Informationen finden Sie hier). Aufgrund der Ausgestaltung als Plattform, die einen großen Fokus auf die Entwicklung von Anwendungen legt, macht SAP HANA DevOps als methodischen Ansatz zur Softwareentwicklung umfassend möglich. Da dies auch für die Entwicklung von Datenbankobjekten gilt, drängt sich DevOps ebenfalls zur Entwicklung eines SQL Data Warehouse auf, für das sich das nachfolgende DevOps-Prozessmodell (Abb. 1.1) als methodische Form ergibt (sieh auch Blog 1 der Reihe: Agile Development).
Abb. 2.1: DevOps-Phasen und -Kontinuitätsprozesse des SAP HANA SQL Data Warehousing
2.1 Continuous Integration
Continuous Integration beeinflusst die im Prozessmodell dargestellte Designtime stark, insbesondere die Phasen Model, Develop und Build. In Bezug auf die beschriebenen CI-Elemente lassen sich mit Blick auf die Praxis folgende Aspekte festhalten:
2.1.1 Quellcode
Im Vergleich zur bisher bekannten Datenbankentwicklung ist ein entscheidender Punkt der SAP-HANA-Plattform, dass Datenbankobjekte wie Tabellen oder Views zunächst als Designtime-Objekte angelegt werden und durch einen „Build“ in Runtime-Objekte auf der Datenbank überführt werden. Hierdurch werden lediglich die Zielobjekte definiert und die Objekte nicht selbstständig erzeugt. Dafür sorgt der Anwendungsserver XSA (SAP HANA Extended Application Services Advanced Model), auf dem zunächst entwickelt wird, im Zusammenspiel mit dem Datenbankservice HDI (HANA Deployment Infrastructue), durch den die Objekte in spezifischen Containern zusammengefasst und als zusammenhängendes Schema auf der Datenbank deployed werden. Durch diese Abstrahierung wird die aus der Softwareentwicklung bekannte Quellcodeverwaltung mit Versionskontrollsystemen sowie die Freiheit zur Verwendung unterschiedlicher Entwicklungswerkzeuge und Build Server ermöglicht. Darüber hinaus sorgt die Abstrahierung dafür, dass in der Designtime des SAP HANA SQL Data Warehousing kein Schwerpunkt auf der direkten Erstellung von SQL-Code liegt. Vielmehr werden die Zielbeschreibungen durch die Verwendung von grafischen Datenbankmodellen, Datenflusslogiken in Flowgraphs und Berechnungen in Calculation Views vorgenommen. Die Programme SAP PowerDesigner und SAP Web IDE erzeugen den Code dabei effizient im Hintergrund. Praktisch ergibt sich folgende Kette von Arbeitsschritten:
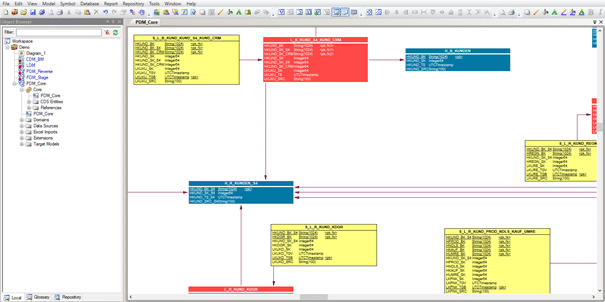
Modellierung: Im SAP PowerDesigner werden die verschiedenen Datenmodelle des SAP HANA SQL Data Warehouse modelliert (hier finden Sie einen Einstieg in die Modellgetrieben Entwicklung des SAP HANA SQL DWH). Abb. 2.1 zeigt die Modellierung der Core-DWH-Schicht im Data-Vault-Stil. Die entsprechenden Zielstrukturen werden auf Basis des Modelles erzeugt und in das Versionskontrollsystem Git exportiert.
Abb. 2.2: Datenmodelle im SAP PowerDesigner
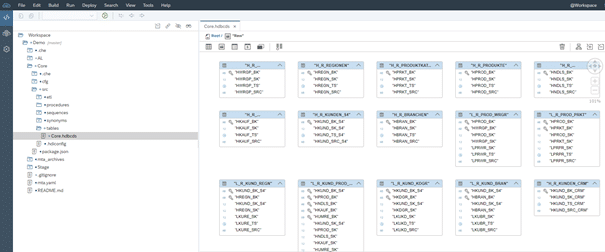
Überführung in SAP Web IDE: Die Datenmodelle werden anschließend aus dem Versionskontrollsystem Git in die Entwicklungsumgebung der SAP-HANA-Plattform SAP Web IDE importiert. Abb. 2.3 zeigt die Designtime-Tabellen der Core-DWH-Schicht.
Abb. 2.3: Import der Datenmodelle in SAP Web IDE
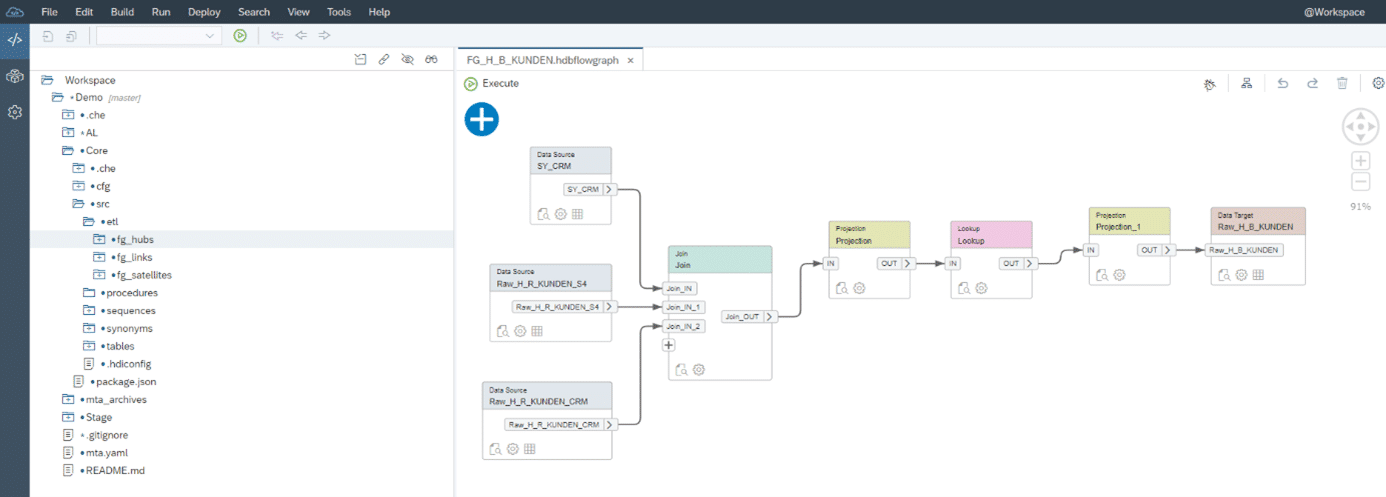
Entwicklung der Designtime-Objekte: Es werden Datenflusslogiken und Berechnungen implementiert. Abb. 2.4 zeigt die Modellierung eines Datenflusses aus der Stage-Schicht des DWH in die Core-Schicht (ETL).
Abb. 2.4: Erstellung von Flowgraphs zur Definition der Datenflüsse
2.1.2 Branching
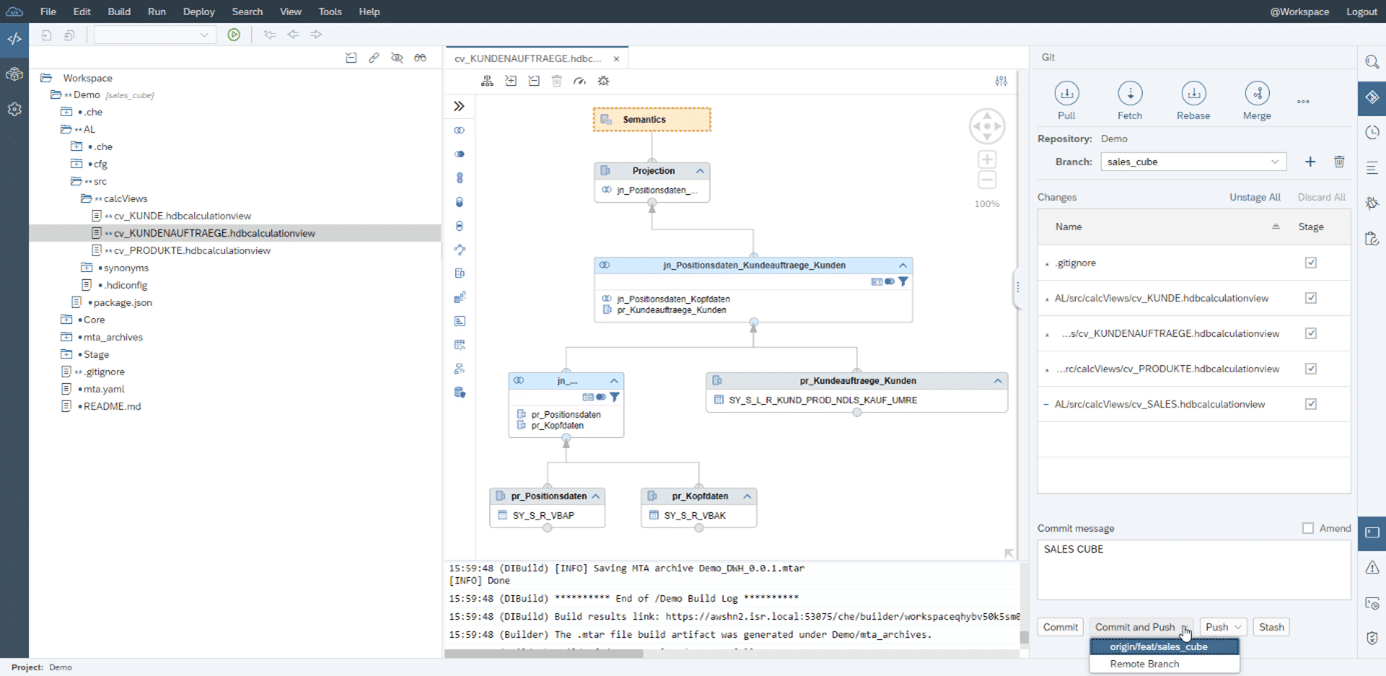
Nach der lokalen Bearbeitung der DWH-Objekte, werden diese über das Konzept des Branching zusammengeführt. Abb. 2.5 zeigt das Beispiel neu erstellter Analytischer Objekte in Form von Calculation Views. Die Veränderungen werden mit dem Befehl „Commit and Push“ zunächst auf den für diese Features vorgesehenen Branch „feat/sales_cube“ mit dem Kommentar „SALES_CUBE“ im Git abgespeichert.
Abb. 2.5: Git Commit and Push auf Feature-Branch
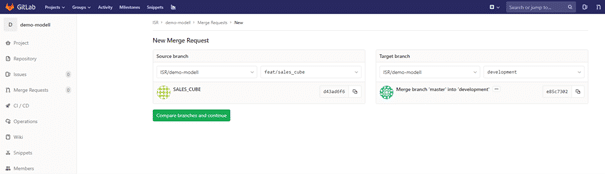
Im Anschluss kann im Git-Repository ein Merge-Request vom jeweiligen Entwickler des Feature-Branch „feat/sales_cube“ auf den gemeinsamen Branch „development“ erfolgen. Abb. 2.6 zeigt das entsprechende Vorgehen für die zuvor vollzogenen Änderung „SALES_CUBE“. Im nächsten Schritt können die etwaigen Unterschiede auf beiden Branches verglichen werden. Der Besitzer des Development-Branch gibt den Merge schließlich frei bzw. lehnt ihn ab (Vier-Augen Prinzip).
Abb. 2.6: Merge Request mit dem Ziel Development-Branch
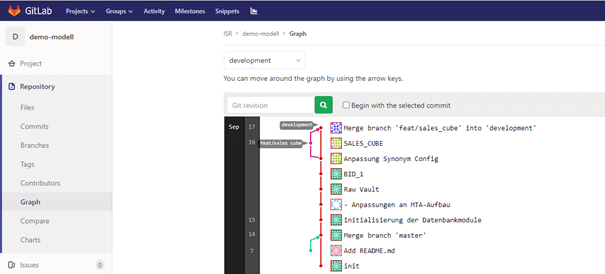
Nach einem erfolgreichen Merge sind die Stände der verschiedenen Branches integriert und stimmen überein. Abb. 2.7 zeigt die Verläufe der Branches in grafischer Form, die eine übersichtliche Möglichkeit der Nachverfolgung aller Veränderungen bietet. Nach einem Merge wird der Feature-Branch nicht mehr benötigt und kann entfernt werden. Alle neuen zukünftigen Feature-Branches enthalten dann die neue Entwicklung.
Abb. 2.7: Veränderungen der Branches im Zeitverlauf
2.1.3 Tests
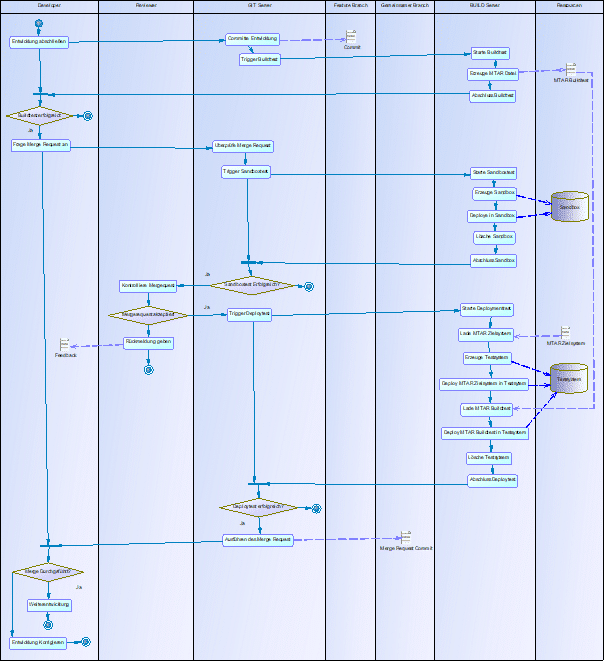
Im Rahmen von Continuous Integration geht es vor allem darum, durch häufiges Ausführen des Quellcode die Integration der Codebestandteile sicherzustellen. Nachfolgend wollen wir mit einem Prozessmodell einen Überblick über die Vorgehensweise und die verschiedenen Tests im Bereich CI geben (eine zusammenhängende Abbildung finden Sie am Ende Anhang A).
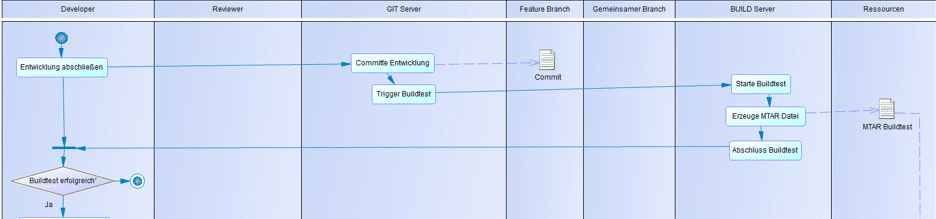
Buildtests: Die einfachste Testform im Bereich CI sind Buildtests. Hierbei validiert der Build durch den Build Server (Jenkins) nach einem Commit auf einem Feature-Branch im Git den Quellcode, indem eine Transporteinheit „gebaut“ wird. Diese Transporteinheit ist eine mtar-Datei, die im weiteren Verlauf genutzt wird (Abb. 2.8).
Abb. 2.8: Buildtest
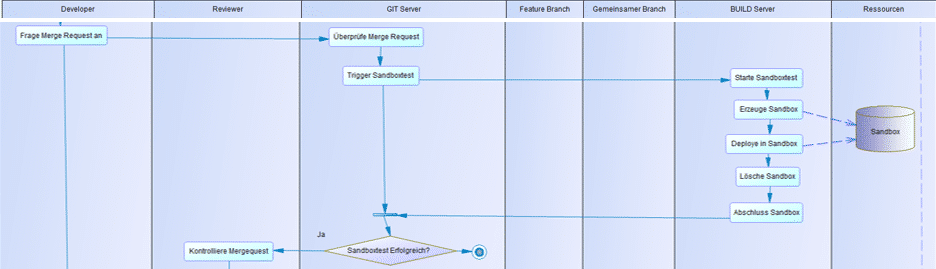
Sandboxtests: Im Anschluss an einen erfolgreichen Buildtest wird der Mergevorgang eingeleitet. Dazu deployed der Build Server den Quellcode des zu integrierenden Feature-Branches in einer Sandbox auf der SAP-HANA-Datenbank (Abb. 2.9). Die Sandbox entsteht dabei nur temporär (sog. Create-Deploy-Destroy-Ansatz)
Abb. 2.9: Sandboxtest
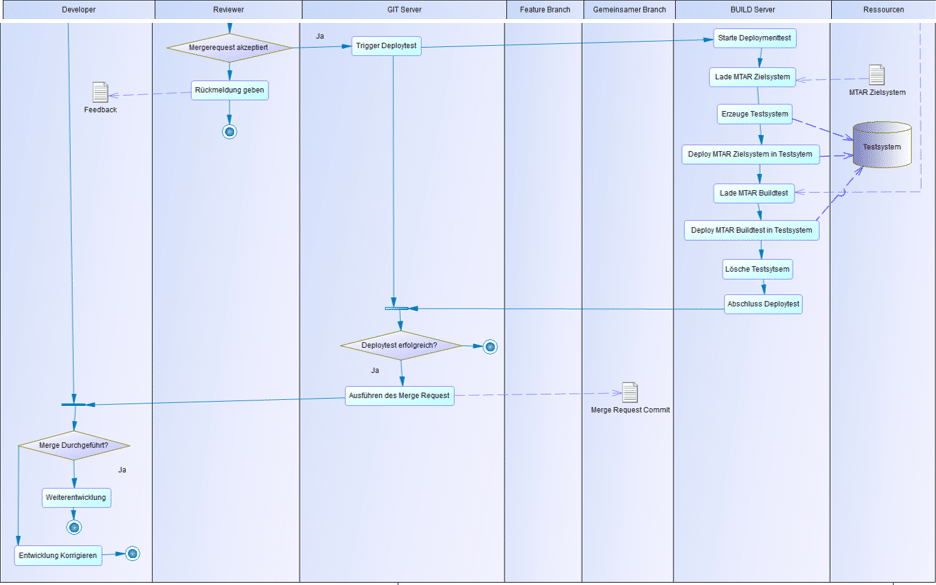
Deploytests: Zuletzt erfolgt ein Deploytest, bei dem die Integrationsfähigkeit des Feature-Branch mit dem aktuellen Stand des Zielbranch (Development) getestet wird. Dazu erzeugt der Build Server ein Testsystem und führt darin zunächst den aktuellen Stand des Zielbranch aus. Hierbei dürfen keine Fehler auftauchen, da dieses Deployment den aktuell ausgelieferten, produktiven Stand darstellen sollte. Anschließend wird auf das nun „neu“ erzeugte Abbild des Zielbranches der zu mergende Branch (Feature) deployed. Hierzu kann die zuvor durch den Buildtest erzeugte mtar-Datei wiederverwendet werden. Durch den Test werden alle datenbankspezifischen Objekte auf Anpassbarkeit geprüft, was konkret bedeutet:
Existierende Tabellen werden aktualisiert
Neuen Tabellen stehen nicht im Konflikt mit existierenden Tabellen
Existierende ETL-Strecken werden aktualisiert
Existierende ETL-Strecken funktionieren mit neu erzeugten Tabellen und angepassten Strukturen
Existierende Calculation Views werden aktualisiert
Existierende Calculation Views greifen auf neu erzeugten Tabellen und angepassten Strukturen zu
Abb. 2.10 zeigt die Arbeitsschritte des Deploytest im Überblick. Erst nach einem erfolgreichen Deploytest kann der Merge Request freigegeben werden und der neue Quellcode des Features fließt in den Development Branch ein (Merge Request Commit). Hierdurch wird sichergestellt, dass die Auslieferung des neuen Development-Standes zu keinen Problemen führt. Es empfiehlt sich entsprechende Tests ebenfalls für die weitere Auslieferung auf die Branches Release und Produktion zu nutzen, um die Stabilität und Lauffähigkeit des produktiven SAP HANA SQL DWH sicherzustellen. Diese Auflieferungskette ist allerdings Teil des Continuous Delivery, auf das wir in einem weiteren Blog der Reihe im Detail eingehen.
Abb. 2.10: Deploytest
2.1.4 Automatisierung
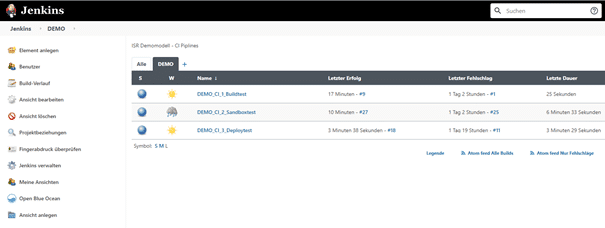
Wie der vorherige Abschnitt zum Verlauf der CI-Tests bereits zeigt, übernimmt der Build Server eine zentrale Rolle und führt die meisten Arbeitsschritte aus. Durch umfassende Konfigurationsmöglichkeiten in diesem Bereich ergibt sich ein großes Automatisierungspotenzial. Abb. 2.11 zeigt eine Übersicht der CI-Pipelines, die wir zuvor vorgestellt haben im Programm Jenkins.
Abb. 2.11: CI-Pipelines in Jenkins
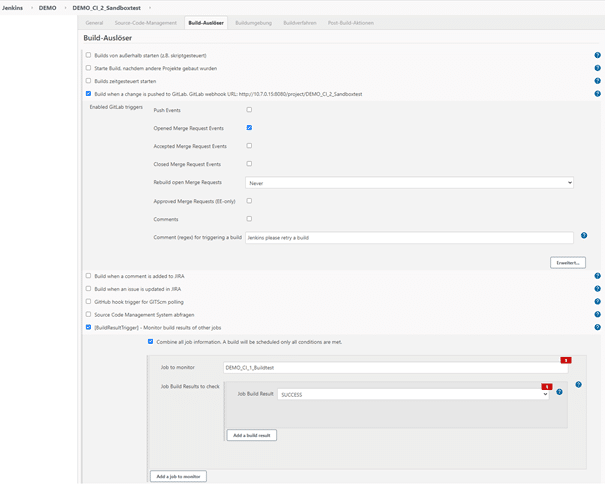
Die Software kann auf Events wie Commits und Merge Requests im Git reagieren und die beschriebenen Pipelines starten. Abb. 2.12 zeigt die Konfiguration des Build-Auslösers für den Sandboxtest. Jenkins reagiert hier auf das Öffnen eines Merge Request im definierten Git Repository und führt bei diesem Event den Sandboxtest durch. Die Ausführung steht jedoch unter der Bedingung, dass zuvor ein erfolgreich Buildtest durchgelaufen ist. Durch eine entsprechende Vorgehensweise mit den übrigen Tests wird ein automatisiertes und kontinuierliches Integrieren von Objekten des SAP HANA SQL DWH weitgehend möglich.
Abb. 2.12: Automatisierung der CI-Pipelines
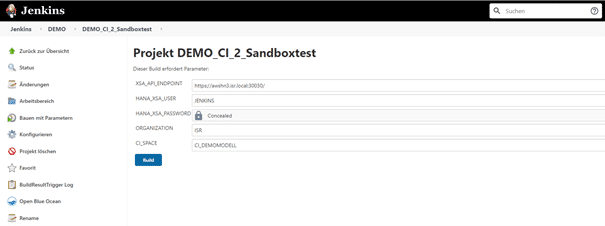
Abb. 2.13 zeigt die Umgebungsparameter des Sandboxtests. Der mit den nötigen Berechtigungen ausgestattete Benutzer „JENKINS“ legt mit dem Build eine Sandbox (CI_SPACE) auf der vorgesehenen HANA-Datenbank (XSA_API_ENDPOINT) an und deployed den Quellcode des Feature-Branch in die erzeugte Sandbox.
Abb. 2.13: Umgebungsparameter des Sandboxtests
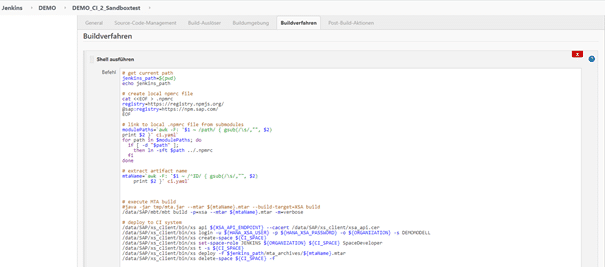
Abb. 2.14 zeigt schließlich den Ablauf des Buildverfahrens für den Sandboxtest auf Basis der Befehle an den Build Server. Das Skript beginnt mit den Kommandos zur Initialisierung der Node.js-Runtime für den SAP MTAR-Builder. Nach der Initialisierung der Abhängigkeiten werden die durchlaufspezifischen Aufrufparameter extrahiert und die Konfiguartionsdatei für den Aufruf des MTAR-Builder „ci.yaml“ vorbereitet. Die erzeugte mtar-Datei wird im nächsten Schritt für das Deployment benötigt (vergleiche hierzu den Prozessablauf). Zuletzt werden Befehle an den Anwendungsserver XSA ausgeführt, um die Sandbox zu erzeugen und darin das Deployment durchzuführen. Die Shellkonsole ist auch der Ort, an dem weitere Tests und Analysen an den Entwicklungsobjekten in Form von Skripten eingefügt werden können, um diese ebenfalls automatisch durchzuführen. Weitergehende Informationen hierzu finden Sie demnächst im Blog Continuous Testing.
Abb. 2.14: Konfiguration eines Buildverfahrens
2.2 Tools
Das SAP HANA SQL Data Warehousing weicht bezüglich der verwendbaren Tools nicht von der Softwareentwicklung ab, es stellt diese gar zentral in den Fokus. Als Versionskontrollsysteme kommen vor allem Produkte der Git-Technologie in Frage. Vorliegend wurde das Tool GitLab benutzt. Hier besteht bei der Auswahl jedoch eine große Flexibilität. Ebenso verhält es sich mit der Entscheidung für ein Build-Server-Tool. Die Open-Source-Lösung Jenkins ist weit verbreitet und wird auch für das SAP HANA SQL Data Warehousing verwendet.
2.3 Vorteile
Durch die Adaption der aus der Softwareentwicklung bekannten Continuous-Integration-Methoden lassen sich die beschriebenen Vorteile auch im Rahmen des SAP HANA SQL Data Warehousing verwirklichen. Für den Aufbau eines Data Warehouse, der bisher häufig durch lange und schwerfällige Entwicklungsprozesse gekennzeichnet war, bedeutet dies einen Paradigmenwechsel. Unternehmen verfügen hierdurch über eine höhere Agilität auf dem Weg zu den immer wichtiger werdenden analytischen Erkenntnissen aus stetig wachsenden Datenmengen. CI ist ein wichtiger Baustein, um agile DWH-Strukturen zu schaffen und kontinuierlichen Mehrwert durch eine verbesserte Informationsbasis und schnellere Entscheidungen zu ermöglichen. Auf die nicht minder wichtigen weiteren Kontinuitätsprozesse gehen wir in den weiteren Blogs der Reihe ein.
3 Fazit
Continuous Integration ist ein veritabler Ansatz zur Beschleunigung von Entwicklung und Integrationsprozessen. Die Beschleunigung schließt dabei das Erreichen hoher Qualitätsanforderungen in Bezug auf die praktische Operierbarkeit von Software mit ein. Das Risiko von Downtimes bei der finalen Auslieferung in die produktive Umgebung wird durch die laufende Integration im Keim erstickt. Ein wichtiger Faktor ist dabei die weitgehende Automatisierung von Arbeitsschritten, die insbesondere durch das Zusammenspiel von Versionskontrollsystemen und Build Servern sichergestellt wird. Diese etablierten Vorgehensweisen der Softwareentwicklung werden aufgrund ihrer deutlichen Vorteile auch für die Data-Warehouse-Entwicklung immer wichtiger, um eine agile und wertorientierte Entwicklung zu unterstützen. Das SAP HANA SQL Data Warehousing verfügt bereits über eine gereifte Adaption der bekannten Werkzeuge und kann mit seinem CI-Prozess die Vorteile in die Welt des Datenmanagements überführen.
Anhang A
Abb. 0.1: Gesamtprozess CI-Tests im SAP HANA SQL DWH
Wir agieren seit 1993 als IT-Berater für Data Analytics und Dokumentenlogistik und fokussieren uns auf das Datenmanagement und die Automatisierung von Prozessen. Ganzheitlich und im Rahmen eines umfassenden Enterprise Information Managements (EIM) begleiten wir von der strategischen IT-Beratung über konkrete Implementierungen und Lösungen bis hin zum IT-Betrieb. ISR ist Teil der CENIT EIM-Gruppe.