Das SAP HANA SQL Data Warehousing setzt auf eine Modellgetriebene Entwicklung und bietet durch diese Vorgehensweise ein hohes Maß an struktureller Flexibilität und prozessualer Agilität.
Inhaltsverzeichnis
1. Modellgetriebene Entwicklung in der Softwareindustrie
1.1 Ansätze
1.2 Ziele
1.3 Charakteristika
1.4 Vorteile
2. Modellgetriebenes SAP HANA SQL Data Warehousing
2.2 Data Warehouse Architektur
2.4 Vorteile
3. Fazit
In diesem Blog wollen wir den Begriff der Modellgetriebenen Entwicklung genauer erläutern. Dazu schauen wir in einem ersten Schritt auf die Ziele, Charakteristika und Vorteile dieses Softwareentwicklungsansatzes. In einem zweiten Schritt konkretisieren wir die Methodik für den Aufbau des SAP HANA SQL Data Warehouse und zeigen Ihnen unser spezifisches Vorgehen und die Vorteile, die sich daraus ergeben.
Modelltriebene Entwicklung in der Softwareindustrie
Der Rückgriff auf Modelle im Umgang mit komplexen Zusammenhängen und Systemen ist eine Vorgehensweise, die allen fachlichen Disziplinen in Wissenschaft und Praxis gemein ist. Auch in der IT und der Entwicklung von Informations- und Softwaresystemen wird die Möglichkeit der Abstrahierung durch Modelle seit Langem umfassend genutzt. Anfang des 21. Jahrhunderts etablierte sich die Idee einer Modellgetriebenen Entwicklung, die auf Basis von Modellen und der anschließend automatisierten Generierung von Quellcode zu einer Verbesserung der Softwareentwicklung führen soll.
Ansätze
Zum Thema Modellgetriebene Entwicklung gibt es unterschiedliche Ansätze. Der anerkannteste Ansatz ist Model Driven Architecture (MDA) der Object Management Group (OMG), der gleichzeitig eine („Standardisierungsinitiative darstellt und von verschiedenen namenhaften Unternehmen und Hochschulen unterstützt wird. Für ein grundlegendes Verständnis ist ein Bezug auf MDA bzw. den MDA Guide daher ausreichend und aufgrund des Verbreitungsgrades am nützlichsten.
Ziele
Das wesentliche Ziel von MDA ist es, Modelle zu nutzen, um besser mit der Komplexität und den wechselseitigen Abhängigkeiten komplexer Systeme umgehen zu können. Der Mehrwert spiegelt sich vor allem in fünf Aspekten:
- Modelle als Kommunikationsmittel: Durch Modelle lässt sich eine gemeinsame Kommunikationsbasis für Entwicklungsteams bzw. an der Entwicklung beteiligte Personen schaffen. Durch definierte semantische Modelleigenschaften und ein geeignetes Abstraktionslevel können Personen unterschiedlicher Fachbereiche schnell ein einheitliches Verständnis eines spezifischen Themengebiets erzielen. Modelle lassen sich zudem leicht austauschen und auf Basis von Versionsständen und Modellstufen weiterentwickeln.
- Automatisierte Transformationen: Die Generierung von Quellcode und die Implementierung von Software auf Basis von Modellen lässt sich ganz oder teilweise automatisieren. Die Automatisierung reduziert den Aufwand zur Umsetzung eines Modells sowie für Änderungen und Wartung und gewährleistet eine höhere Konsistenz der entwickelten Artefakte. Die Betonung „modellgetrieben“ verdeutlicht den Aspekt der Beschleunigung des Entwicklungsprozesses insbesondere durch Automatisierung.
- Modellsimulation und -ausführung: Auf Basis von Modellen können Simulationen vorgenommen werden, die Aufschlüsse über Funktionen bzw. die Folgen von Veränderungen an einem System geben. In Verbindung mit der zuvor angesprochenen automatisierten Transformation können auch abstrakte und untechnische Modelle unmittelbar ausgeführt werden. Die Modellgetriebene Entwicklung bietet so ein erhöhtes Validierungspotential und ermöglicht qualitativ hochwertige Entwicklungen in kurzer Zeit.
- Informationsgewinnung: Im Rahmen der Modellgetriebenen Entwicklung ergeben sich weitere Möglichkeiten der Informationsgewinnung und Analyse. So können Prozessketten und -verantwortlichkeiten ermittelt und ein Großteil der Dokumentation durch integriertes Versions- und Änderungsmanagement erledigt werden. Zudem lassen sich rund um die Ausführung von Modellen Metriken aufbauen, die die Qualitätsbeurteilung verbessern und Entscheidungen über spezifische Veränderungen und Weiterentwicklungen erleichtern. Ferner besteht aufgrund der Bedeutung von Metadaten im Kontext der Modellierung ein erhöhtes Potential zur Strukturierung von unstrukturierten Informationen.
- Standardisierung: Gemeinsam erarbeitete Modellstrukturen und -regeln ermöglichen es Entwicklungsprozesse innerhalb einer Organisation zu standardisieren.
Charakteristika
Die Grundlage von MDA ist die Erfassung von Modellen als Daten, die man abfragen, analysieren, validieren, simulieren und in andere nützliche Formate (wie z.B. ausführbaren Quellcode) transformieren kann. Hierbei sind folgende Merkmale von Bedeutung:
- Modellierung: Die wesentliche Aufgabe innerhalb der Modellgetriebenen Entwicklung liegt darin, die Daten, die „hinter“ einem Diagramm oder einer Grafik liegen, in eine klar definierte Struktur zu bringen. Diese Datenkonzeption oder -semantik gibt Aufschluss darüber, was die Daten im spezifischen fachlichen Kontext (Domäne) bedeuten und macht ihre Weiterverwendung möglich. Ein Modell kann dabei jegliche kontextspezifischen Aspekte wie, Geschäftsprozesse, Informationsträger oder Ressourcen abbilden. Zur Darstellung sind heute verschiedene Modelliersprachen etabliert, insbesondere Business Process Model and Notation (BPMN)Was bedeutet BPMN?BPMN ist die Abkürzung für Business Process Model… Mehr, Unified Modeling Language (UML)UML (Unified Modeling Language) ist eine vereinheitlichte, grafische Modellierungssprache, die… Mehr, Entity-Relationship-Modeling (ER) oder Extensible Markup Language (XML).
- Abstrahierung: Abstraktion ist ein wesentliches Merkmal eines jeden Modells. Ein Modell gilt umso weniger abstrakt, je konkreter es auf ein spezifisches System oder eine technische Lösung zugeschnitten ist. Allgemein haben sich hier drei Level der Abstraktion etabliert.
- Ein Business Model / Konzeptionelles Modell beinhaltet die Eigenschaften und Beziehungen der realen Objekte der zu modellierenden Domäne und keine technischen Informationen. In MDA wird dieses Modell Computation Independent Model (CIM) genannt.
- Das Logische Modell beschreibt aufbauend auf dem Business Model, wie die objektbezogenen Systemkomponenten interagieren, um die Ziele des Systems bzw. der Organisation zu erreichen. In MDA heißt diese Modell Platform Independent Model (PIM).
- Das Implementierungsmodell enthält die Informationen, wie die konkreten Systembestandteile zusammenwirken, um ihre Gesamtfunktion zu erfüllen. Es ist daher in der Regel an eine spezielle Technologie (in MDA Plattform) gebunden. In MDA wird es als Platform Specific Model (PSM) bezeichnet.
- Modelltransformation: Ein zentraler Mehrwert den MDA in Aussicht stellt, ist die Automatisierung des Weges vom abstrakten, Stakeholder-fokussierten Modellen (CIM) zu ausführbaren Informationssystemen. Dieses Ziel kann nicht immer vollständig erreicht werden. Nichtsdestotrotz ist es aufgrund der Reduzierung von Aufwand und Entwicklungsrisiken der Hauptvorteil von MDA und daher unbedingt anzustreben. In der Regel ergibt sich der Dreischritt vom Konzeptionellen oder Business Model (CIM) über das logische, plattformunabhängige Modell (PIM) bis hin zum plattformspezifischen Modell (PSM). Im Rahmen der Automatisierung sind die Transformationsmuster (Pattern) zwischen den einzelnen Stufen zu definieren, beispielsweise in XML.
- Systemlebenszyklus: MDA hat einen großen Einfluss auf die Ausgestaltung des Systemlebenszyklus (System Development Life Cycle – SDLC), der eine wichtige Voraussetzung für einen ganzheitlichen Managementansatz zur Erstellung und Instandhaltung eines Informationssystems ist.
Vorteile
Die Modellgetriebene Entwicklung birgt viele Vorteile, die in den vorherigen Absätzen bereits angeklungen sind. Zusammenfassend lassen sich folgende Punkte festhalten:
- Durch die Verwendung des Business Model sind die Stakeholder besser in die Entwicklung von Informationssystemen integriert und können sich mehr einbringen. Auf diese Weise wird die Komplexität der Aufgabe verringert und die Fachlichkeit der Domäne kommt besser zur Geltung. Das finale System entspricht zu einem höheren Grad den Geschäftsinteressen der Organisation.
- Durch das Automatisierungspotential können Aufwände eingespart und Lösungen schneller erarbeitet werden. Es kann früher ein operativer Nutzen erzielt werden.
- Die plattformunabhängige Modellierung kann für verschiedene Technologien genutzt werden.
- Durch die Transformation besteht eine hohe Konsistenz zwischen den einzelnen Modellen. Änderungen lassen sich auf diese Weise umfassend dokumentieren.
- Folgeabschätzungen können durch Simulationen einfach vorgenommen werden.
- Die Vorgehensweise unterstützt Ansätze der agilen Softwareentwicklung, da Systeme mit starkem Einfluss der Fachlichkeit in kurzen Sprints inkrementell und iterativ entwickelt werden können.
- Durch die Generierung von Quellcode muss weniger Zeit mit der Codierung oder dem Debugging verbracht werden.
Modelltriebenes SAP HANA SQL Data Warehousing
Obwohl sich das Data Warehousing in den vergangenen 25 Jahren zu einer festen Größe im Bereich der Decision Support Systeme (DSS) entwickelt hat, sind Data-Warehouse Projekte auch heute noch häufig komplex, zeitintensiv und kostspielig. Es ist daher nicht verwunderlich, dass die Ideen der Modellgetriebenen Entwicklung auch im Data-Warehouse-Umfeld Anklang gefunden haben und spezifische Formen eines Modellgetriebenen Data Warehousing in Literatur und Praxis bestehen. Auch das SAP HANA SQL Data Warehousing setzt auf einen modellgetriebenen Ansatz, in dem sich viele Elemente von MDA widerspiegeln.
Anforderungsmanagement
Für Entwicklungsarbeiten sind die Anforderungen an das zu Entwickelnde maßgeblich. Dies gilt umso mehr für einen Modellgetriebenen Ansatz, da die spezifischen Anforderungen im besten Fall bereits in ein Modell einfließen. Für ein Data Warehouse ist die Anforderungsdefinition, ähnlich wie bei anderen Informationssystemen, keine leichte Aufgabe. Als DSS soll es Informationen für unternehmerische Entscheidungen zur Verfügung stellen und Business Intelligence ermöglichen. Dadurch ergeben sich im Wesentlichen drei Einflussfaktoren, die es zu berücksichtigen gilt. Zum einen sind die Anforderungen der fachlichen Entscheider bzw. letztlichen Nutzer der Business Intelligence in Form von Reports, Dashboards und sonstigen visuellen Aufbereitungen von Daten zur Entscheidungsfindung relevant. Die Bedürfnisse der verschiedenen Fachbereiche müssen darüber hinaus in die strategische Unternehmensausrichtung eingefasst sein, da im Rahmen des klassischen Enterprise Data Warehouse in der Regel versucht wird, die Daten in einen unternehmensweit gültigen Kontext zu bringen. Als dritter Einflussfaktor bleiben die vorhandenen Datenquellen, denen die Informationen entnommen werden müssen. Beim SAP HANA SQL Data Warehousing stehen vor allem die ersten beiden Aspekte stark im Fokus, da aufgrund der umfassenden Systemoffenheit des SQL-Ansatzes Details zur Systemlandschaft im ersten Schritt nicht so relevant sind. In unserer Beratungspraxis fokussieren wir uns in Workshops mit den Nutzern vielmehr auf die fachlichen Erkenntnisse und Metriken, die am Ende gewonnen werden sollen und erarbeiten auf diese Weise ein erstes konzeptionelles Datenmodell. Dieses Business Model ist als Kommunikationsmittel beim Austausch mit der Fachlichkeit von großem Wert und bildet das zentrale Anforderungsprofil, das für alle weiteren Schritte genutzt wird.
Data Warehouse Architektur
Ein Data Warehouse ist durch eine Architektur aufeinander aufbauender Schichten geprägt. Für einen Modellgetriebenen Ansatz ist die Ausprägung dieser Schichten von großer Bedeutung, da sich die definierte Struktur in den zusammenhängenden Modellen wiederfindet. Grundsätzlich ergibt sich für das SAP HANA SQL DWH folgendes Bild (Abbildung 01): Daten aus verschiedenen Quellsystemen werden über ETL-Strecken oder virtuell in das Data Warehouse integriert. Im SAP HANA SQL DWH, das nach dem Data-Vault-Ansatz modelliert wird, werden die Daten für BI- und Analytics-Frontends in multidimensionaler bzw. spezifischen Präsentationsformen aufbereitet. Die SAP-HANA-Plattform bietet dabei den Vorteil, dass aufgrund der Leistungsstärke der SAP-HANA-Datenbank komplexe Berechnungen bereits umfassend und schnell auf der Datenbankebene erfolgen können.
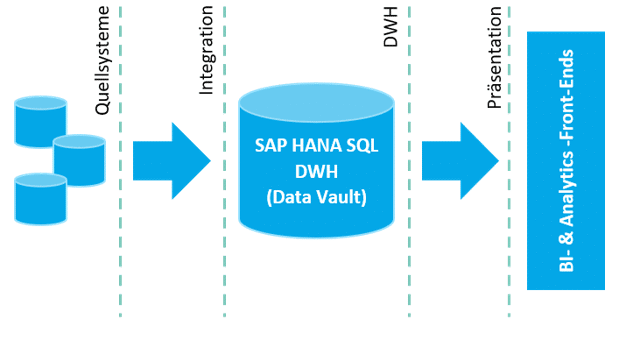
Abbildung 01: Grundlegende DWH-Architektur
Entwicklungsansatz
Wie oben bereits beschrieben, bildet das Business Model auf konzeptioneller Ebene den Startpunkt für die modellgetriebene Entwicklung des SAP HANA SQL DWH und entspricht dem Computation Independent Model (CIM) der MDA-Systematik. Die Erstellung erfolgt im SAP PowerDesigner, der als Hauptwerkzeug für die Modellierung genutzt wird und das Modell in einem sehr einfach gehaltenen ER-Diagramm darstellt (Informationen zum allen Tools des SAP HANA SQL DWH finden Sie hier). Das Business Model wird im nächsten Schritt in das Physische Datenmodell des Data Warehouse (Core Data Vault) gewandelt. Die technische Erstellung fußt dabei überwiegend auf den Strukturen der vorhandenen Datenquellen, da sich aus diesen mithilfe des SAP PowerDesigners automatisch ein Modell erzeugen lässt. Aus diesem physischen Reverse Model der Datenquellen werden über den Zwischenschritt des Staging Model (Datenintegration) wesentliche Teile des Core Data Vault generiert und mit den fachlichen Informationen des Business Model angereichert und ausgestaltet. Die logische Ebene und damit das Platform Independent Model (PIM) wird übergangen, da SAP-HANA-Datenbank-Artefakte erstellt werden sollen. Bei Bedarf bietet der SAP PowerDesigner jedoch auch die Funktionen zur Generierung eines logischen Datenmodells. Der Aufbau des physischen Datenmodells des Data Warehouse erfolgt in Form eines Data Vault, da sich hierdurch die größten Vorteile im Hinblick auf eine flexible Weiterentwicklung sowie ein agiles Data Warehousing im Sinne der DevOps-Philosphie ergeben.

Das physische Data-Vault-Modell dient schließlich als Grundlage für das benötigte analytische Modell (Virtual analytical Model). Auch hier spielen die fachlichen Überlegungen des Business Model eine wichtige Rolle und die Modellobjekte werden miteinander verknüpft. Generell wird die Möglichkeit von Modellwandlungen und der automatischen Generierung von Modellen und Quellcode so oft wie möglich genutzt und zumindest alle Modelle miteinander verknüpft. Auf diese Weise entsteht ein zusammenhängende Modellstruktur des SAP HANA SQL DWH (Abbildung 02). Der Quellcode lässt sich aus dieser Struktur automatisch erzeugen und kann über die verteilte Quellcodeverwaltung Git in die SAP-HANA-Plattform eingebracht und ausgeführt werden.
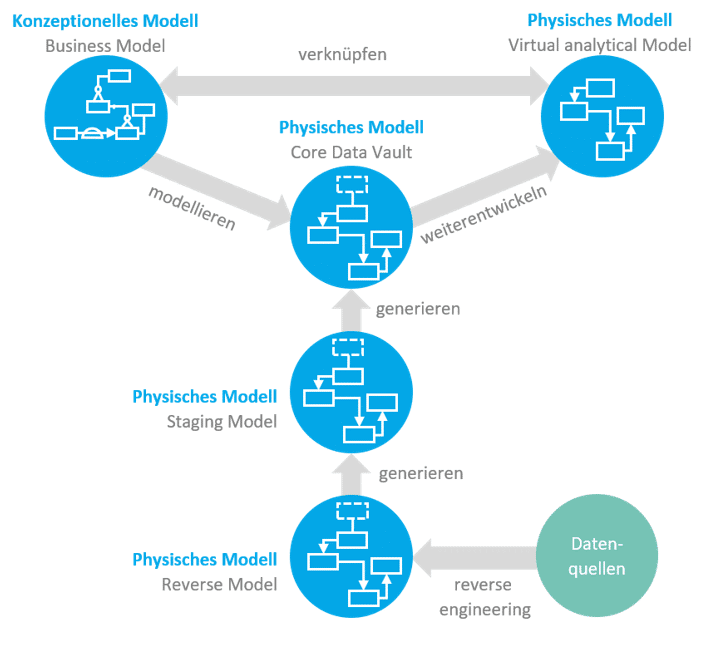
Abbildung 02: Modellgetriebenes SAP HANA SQL Data Warehousing
Vorteile
Die Ausführungen zeigen, dass sich viele Vorteile des MDA-Standards auch im modellgetriebenen SAP HANA SQL Data Warehousing erreichen lassen. Folgende Punkte sind hervorzuheben:
- Kommunikation mit den Fachbereichen: Auf Basis des Business Model können die Anforderungen der fachlichen Entscheider an das Data Warehouse bestmöglich einfließen und durch die anschließenden Transformationen wird sichergestellt, dass sich die Fachlichkeit im Verlauf der immer technischer werdenden Arbeitsschritte nicht verliert.
- Automatisierung: Die automatische Generierung von Modellen und Quellcode ist an vielen Stellen der Entwicklung des SAP HANA SQL DWH möglich und verringert den Arbeitsaufwand sowie das Risiko von Fehlern.
- Qualität: Durch den schematischen Gesamtablauf und einhergehende Regelungen wie Modellierungs- und Namenskonventionen sowie den Rückgriff auf Transformationen und die automatische Generierung von Modellen und Quellcode steigt die Qualität, da das Risiko von Fehlern reduziert wird. Lineage-, Impact- und Usage Analysen bieten zudem die Möglichkeit Entwicklungsschritte zu simulieren und Szenarien durchzuspielen.
- Transparenz: Aufgrund der umfassenden Zusammenhänge ergibt sich eine hohe Transparenz im SAP HANA SQL DWH. Die Entwicklungen lassen sich im Hintergrund leicht dokumentieren und sind jederzeit nachvollziehbar.
- Standardisierung: Das modellgetriebene SAP HANA SQL Data Warehousing bietet ein hohes Standardisierungspotential.
Fazit
In diesem Blog haben wir Ihnen den Begriff der Modellgetriebenen Entwicklung nähergebracht und das Grundkonzept der Model Driven Architecture (MDA) vorgestellt. Von diesem grundsätzlich softwarebezogenen Standard lassen sich viele nützliche Inhalte für das SAP HANA SQL Data Warehousing nutzen. Das SAP HANA SQL Data Warehousing kann auf diese Weise mit einem hohen Bezug zur Fachlichkeit sehr agil erfolgen und erzeugt in kurzer Zeit nutzbare Business Intelligence für betriebliche Entscheider. Dies liegt auch daran, dass sich der Modellgetriebene Ansatz sehr gut mit den weiteren Eigenschaften des SAP HANA SQL Data Warehousing verknüpfen lässt, die wir in diesem Blog für Sie zusammengetragen haben. Sollten Sie darüber hinaus noch Fragen zum Thema SAP HANA SQL Data Warehousing oder zur Modellgetriebene Entwicklung haben, sprechen Sie uns gerne an.
Autoren: Tim Andzinski, Martin Peitz

Marius Wimmers
Service Manager
SAP Information Management
marius.wimmers@isr.de
+49 (0) 151/42205-434


