Schon die alten Griechen träumten vom Glück ohne menschliches Zutun und übertrugen diese Aufgabe der Göttin Automatia (Georges). Zwei Jahrtausende später ist die Menschheit diesem Traum in vielen Bereichen ein ganzes Stück nähergekommen und arbeitet höchstselbst daran, den Anteil menschlicher Tätigkeiten in der Wertschöpfung immer weiter zu reduzieren.
Ein Gebiet, in dem sich der Gedanke der Automatisierung in den letzten Jahren immer stärker etabliert, ist das Data Warehousing. In diesem Blog wollen wir klären, was es mit der Data Warehouse Automatisierung (DWA) auf sich hat und warum es sich auch in dieser, vergleichsweise jungen, Disziplin lohnt, über Automatisierung nachzudenken.
Was beabsichtigt Data Warehouse Automation?
Data Warehouse Automatisierung beabsichtigt manuelle Tätigkeiten, die sich im Rahmen der Entwicklung und Implementierung eines Data Warehouse immer wieder ergeben und einen Großteil des Arbeitsvolumens ausmachen, durch automatisierte Softwareprozesse zu ersetzen. Das Data Warehousing soll auf diese Weise vereinfacht und beschleunigt sowie konzeptionell in ein Lifecycle Management überführt werden, das klar definierte und weitgehend automatisierte Schritte für die Entwicklung, den Erhalt und die Weiterentwicklung eines Data Warehouse vorsieht.
Wie erfolgt Data Warehouse Automation?
DWA erfordert eine Umsetzung auf verschiedenen organisatorischen Ebenen. Bei einer Betrachtung vom Allgemeinen zum Speziellen lassen sich folgende Aspekte festhalten:
1. Lifecycle-Konzept
Entsprechend dem Lifecycle-Gedanken bedarf es zum Zwecke der Automatisierung zunächst einer grundlegenden Strukturierung der Data-Warehousing-Prozesse. Das Data Warehousing ist auch heute noch oftmals ein vielschichtiger Bereich, in dem verschiedene Tools von unterschiedlichen Stakeholdern genutzt werden. Daher ist es hinsichtlich der Automatisierung einzelner Aufgaben wichtig, die Entwicklungsarbeiten am Data Warehouse in ein einheitliches Korsett zu fassen und das Ineinandergreifen der einzelnen Tätigkeiten klar zu definieren. In diesem Zusammenhang bieten sich allgemeine Ansätze der agilen Softwareentwicklung als Basis.

Insbesondere die DevOps-Philosophie hat sich in den vergangenen Jahren als ganzheitlicher Entwicklungsansatz mit starkem Fokus auf kontinuierlichen Output und einem hohen Automatisierungsgrad in vielen Softwareprojekten bewährt. Durch ein klares Phasenmodell und spezifische Kontinuitätsprozesse (Grafik 01) liefert DevOpsWas ist DevOps?Der Begriff DevOps setzt sich aus den Wörtern… Mehr ebenfalls ein gutes Grundkonzept zur Durchführung von DWA. Sollten Sie sich noch nicht mit dem Thema DevOps befasst haben, finden Sie hier eine Einführung.
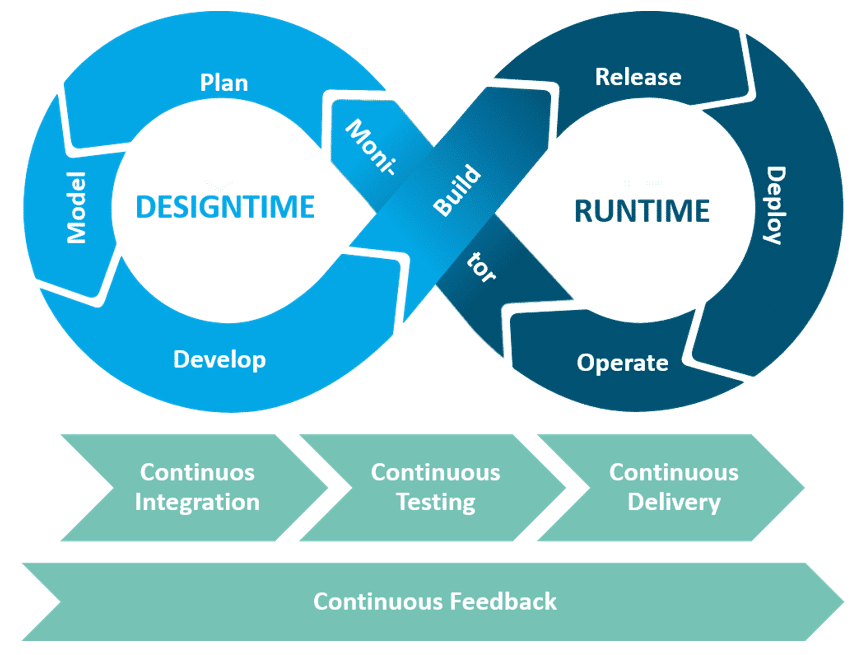
Grafik 01: DevOps-Prozessmodell für Data Warehousing
2. Modellgetriebene Entwicklung
Im Rahmen der Entwicklung eines Data Warehouse spielen Datenbankmodelle eine wichtige Rolle. DWA geht daher in der Regel mit Ansätzen der Modellgetriebenen Entwicklung einher, die verschiedene Modelle miteinander verknüpfen und einen methodisch sauberen Weg von abstrakten, geschäftlichen Überlegungen hin zur konkreten, technischen Umsetzung im Data Warehouse ermöglichen. Durch dieses Vorgehen ergibt sich bereits ein hohes Automatisierungspotential innerhalb der Modellgetriebener Ansätze, dass insofern im Rahmen von DWA nur gehoben und in ausdefinierter Form in das DWA-Lifecycle-Konzept integriert werden muss (grundlegendes zur Modellgetriebenen Entwicklung finden sie hier). Eine Modellierungsform, die in diesem Zusammenhang in den vergangenen Jahren enorm an Bedeutung gewonnen hat und in vielen modellgetriebenen DWA-Ansätzen eine zentrale Position einnimmt, ist Data Vault. Der von Dan Linsted Anfang der 2000er Jahren veröffentlichte Ansatz zur Datenmodellierung im Data Warehouse besteht mittlerweile in der Version Data Vault 2.0 und wird von der Fachwelt für seine Eigenschaften in Bezug auf Agilität, Historisierung und Automatisierung geschätzt. Agilität bezeichnet dabei die Möglichkeit, das Data-Vault-Modell sehr einfach laufend anpassen zu können, was heute dem Bedürfnis vieler Unternehmen entspricht. Historisierung bedeutet im Gegenzug, dass trotz laufender Anpassungen keine Daten verloren gehen und sich weiter eine Analysemöglichkeit ergibt. Das Potential für Automatisierungen ergibt sich aus den schlichten Regeln, denen Data Vault folgt (es gibt nur drei Modellierungselemente siehe Grafik 02). Hierdurch lassen sich Modelle ganz oder teilweise generieren sowie entsprechende Ladeprozesse (ETL) automatisch erzeugen.
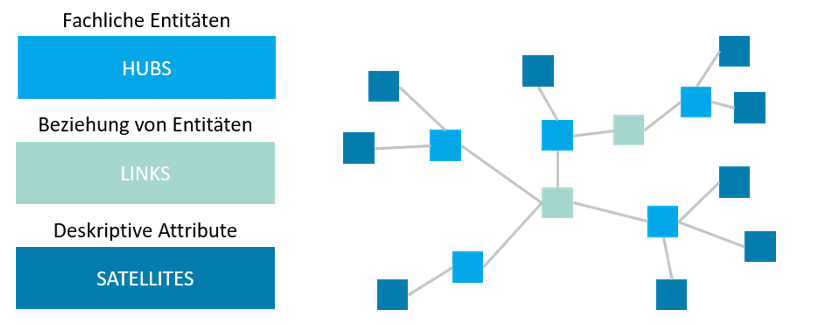
Grafik 02: Modellierungselemente Data Vault
3. Automatisierte Tätigkeiten
Nach diesen eher grundsätzlichen, aber dennoch bedeutenden Aspekten der Data Warehouse Automatisierung, stellt sich die Frage nach den konkreten Tätigkeiten, die sich automatisieren lassen. Folgende Arbeitsschritte und -prozesse lassen sich nennen:- Quellenanbindung: Die Anbindung der Quellsysteme ist ein Vorgang, der sich durch das sogenannte Reverse Engineering zu einem Großteil automatisieren lässt. Beim Reverse Engineering werden die die Metadaten der Quellsysteme, also die Daten die Auskunft über die Art und Weise der Datenorganisation im jeweiligen Quellsystem geben, ausgelesen und stehen für die Weiterverarbeitung im Data Warehouse zur Verfügung. Die Quellenanbindung nimmt auf diese Weise eine zentrale Position im Hinblick auf die Aufbereitung der unterschiedlichen Datenmodelle im Data Warehouse ein, da die Metadaten der Quellsysteme als Grundstock dienen, die lediglich nach spezifischen Regeln umgewandelt bzw. erweitert und ergänzt werden.
- Objektgenerierung: Die Objektgenerierung bezieht sich auf die einzelnen Elemente in den verschiedenen Datenmodellen des Data Warehouse. Die verschiedenen Datenmodelle ergeben sich aufgrund der Schichtenarchitektur eines Data Warehouse, die zumeist aus zwei oder drei Ebenen besteht. Im Zentrum steht in der Regel das Data-Vault-Datenmodell. Es gibt die wesentlichen Regeln auf Basis der realen Geschäftsbedingungen vor. Die Definition der konkreten Regeln kann daher nicht automatisiert erfolgen. Ist diese Arbeit jedoch geleistet, können in Verbindung mit den Metadaten der Quellsysteme ein Großteil aller Objekte automatisch generiert werden.
- ETL-Generierung: Beim klassischen Data Warehousing werden die Daten aus OLTP-Systemen in das OLAP-System des Data Warehouse durch Extract, Transform und Load (ETL) übertragen. Modernere Lösungen arbeiten auch mit virtuellen Verbindungen, in den die Daten zwar im Data Warehouse vorliegen, physisch jedoch im Quellsystem verbleiben. In beiden Fällen müssen die Datenflüsse konzipiert werden. Durch DWA, mit den vorherigen Schritten der Quellanbindung und der Objektgenerierung kann dieser Arbeit als Abfallprodukt ebenfalls stark automatisiert erfolgen.
- Continuous Integration, Testing und Delivery: Continuous Integration, Continuous Testing und Continuous Delivery sind Begriffe der agilen Softwareentwicklung und heute speziell mit der DevOps-Philosophie verbunden. Im Verbund beabsichtigen diese Kontinuitätsprozesse kleinere Entwicklungen oder Entwicklungsstufen kontinuierlich zu integrieren und in Produktivumgebungen auszuliefern, um so möglichst schnell einen nutzbaren Mehrwert zu erzielen bzw. Fehlentwicklungen schnellstmöglich aufzudecken. Ein wichtiger Faktor ist dabei möglichst hoher Automatisierungsgrad, insbesondere in Bezug auf verschiedene Tests. Mit DWA kann diese Maßgabe auch im Data Warehouse umgesetzt werden, da die Modelle vollintegriert sind und sich so eine Auslieferungskette über die verschiedenen Schichten des DWH aufbauen lässt. Diese kann mit spezifischen Deploymentwerkzeugen automatisiert durchlaufen und zuvor definierte Test in können in diesem Rahmen durchgeführt werden.
- Dokumentation: Durch die umfassende Integration der verschiedenen Tätigkeiten sorgt DWA für eine automatische Dokumentation aller Vorgänge und Abhängigkeiten. Hierzu gehören insbesondere eine klare Data Lineage, also die Rückverfolgbarkeit von Daten durch die verschiedenen Schichten des Data Warehouse bzw. über verschiedene OLTP-Systeme sowie Informationen, wer wann Änderungen vorgenommen hat.
Welche Vorteile ergeben sich durch Data Warehouse Automation?
Der Hauptvorteil, der sich durch DWA ergibt und wesentlicher Beweggrund zur Nutzung entsprechender Ansätze sein sollte, ist die Beschleunigung der Data-Warehousing-Prozesse. Der Traum des Glücks ohne menschliches Zutun erfüllt sich durch DWA nur bedingt. Geschäftsprozesse müssen weiterhin von Menschen modelliert und die Daten nach spezifischen Regeln miteinander in Beziehung gesetzt werden. Zudem verbleibt dem Menschen in allen Bereichen die Rolle einer Kontrollinstanz, die mit ihrem umfassenden Wissen das gesamte Verfahren steuert und überwacht. DWA wirkt daher daraufhin die menschliche Arbeit abseits der analytischen Modellierungsarbeiten auf die Kontrollfunktion zu beschränken und diese möglichst zu vereinfachen. So werden repetitive Aufgaben, die schematischen Regeln folgen, von Software übernommen. Darüber hinaus werden schematische Tests einmal definiert und von Software laufend ausgeführt. Auf diese Weise ergibt sich vor allem eine große Zeitersparnis, durch die die Nutzer des Data Warehouse schneller in den Genuss datengestützter Auswertungen kommen, um das Hauptgeschäft mit Entscheidungen voranzutreiben. Das Data Warehousing wird hierdurch aus menschlicher Sicht zudem angenehmer, da sich die Arbeit auf kreative Tätigkeiten fokussiert.
Zeit steht in einer starken Relation zu Qualität. Anforderungen können in der Regel sauberer erfüllt werden, wenn kein allzu großer Zeitdruck herrscht. Durch DWA können beide Aspekte verbessert werden, da die zeitaufwendigen und fehleranfälligen repetitiven Aufgaben eliminiert werden. Zudem versucht DWA gerade die Kontrollfunktion des Data-Warehouse-Entwicklers zu verbessern. Hierdurch kann dieser besser überwachen, ob die Entwicklung den Anforderungen entspricht. Hinsichtlich der Qualitätssicherung ergibt sich darüber hinaus die Situation eines erhöhten Initialaufwandes. So müssen die Regeln und Tests, nach denen die DWA-Software arbeitet zu Beginn definiert werden. Durch die schnelle und saubere Ausführung durch die Software rentiert sich dieser Aufwand jedoch sowohl zeitlich als auch qualitativ. Durch die umfassende Dokumentation können dennoch auftretende Fehler zudem besser und schneller nachverfolgt und behoben werden.
Aus beiden Gesichtspunkten lässt sich damit grundsätzlich auch eine Verringerung der Kosten des Data Warehousing ableiten, da die Produktivität steigt. Aufgrund der nötigen Investitionen in Software und Knowhow zur Umsetzung entsprechender DWA-Ansätze lässt sich eine solche Rechnung jedoch nicht pauschal aufstellen. Die Argumente liegen vor allem in den zuerst genannten Punkten. Kostenersparnisse ergeben sich insgesamt wohl am ehesten durch die erhöhte Qualität. DWA vermeidet frühzeitig das Entstehen von Fehlentwicklung und macht trotz schneller Abläufe umfassende und einfache Steuerungsmechanismen möglich. Dieser Gesichtspunkt ist jedoch monetär schwer messbar und offenbart das grundsätzliche Problem von Präventionsstrategien, die bereits erfolgreich sind, wenn die Prozesse so ablaufen, wie geplant.
Welche Lösungen gibt es?
Auf dem Markt für DWA-Lösungen gibt es mittlerweile eine Reihe von Angeboten, der von Komplettlösungen bis zu eher methodisch orientierten Ansätzen mit individuellem Tooling reicht. Eine Betrachtung aller Lösungen können wir an dieser Stelle nicht vornehmen. In einem nächsten Blog zum Thema möchten wir Ihnen allerdings die DWA-Prozesse des SAP HANA SQL Data Warehousing genauer erläutern. Eine Liste von Anbietern aus dem Jahr 2019 finden Sie zudem an dieser Stelle.

Fazit
In diesem Blog haben wir Ihnen die Grundzüge der Data Warehouse Automatisierung erläutert und die Vorzüge dieses Entwicklungskonzepts betrachtet. In Zeiten, in denen dynamische wirtschaftliche Rahmenbedingungen schnelle Anpassungen von Auswertungsgrundlagen erfordern, um fundierte, datenbasierte Entscheidungen treffen zu können, lohnt es sich über DWA-Strategien nachzudenken. Für das SAP-Umfeld wollen wir Ihnen dazu im nächsten Blog die Vorzüge des SAP HANA SQL Data Warehousing vorstellen. Sollten Sie Fragen in Richtung DWA oder dem SAP HANA SQL Data Warehousing haben, kommen Sie gerne auf uns zu.
Autor: Eckhard Schulze, Martin Peitz

Christopher Kampmann
Head of Business Unit
Data & Analytics
christopher.kampmann@isr.de
+49 (0) 151 422 05 448


