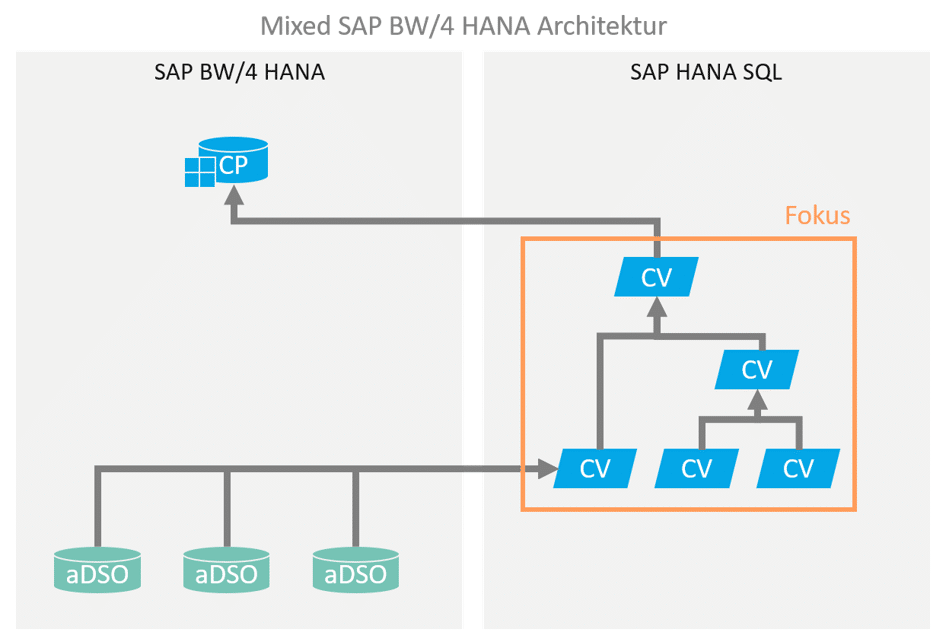
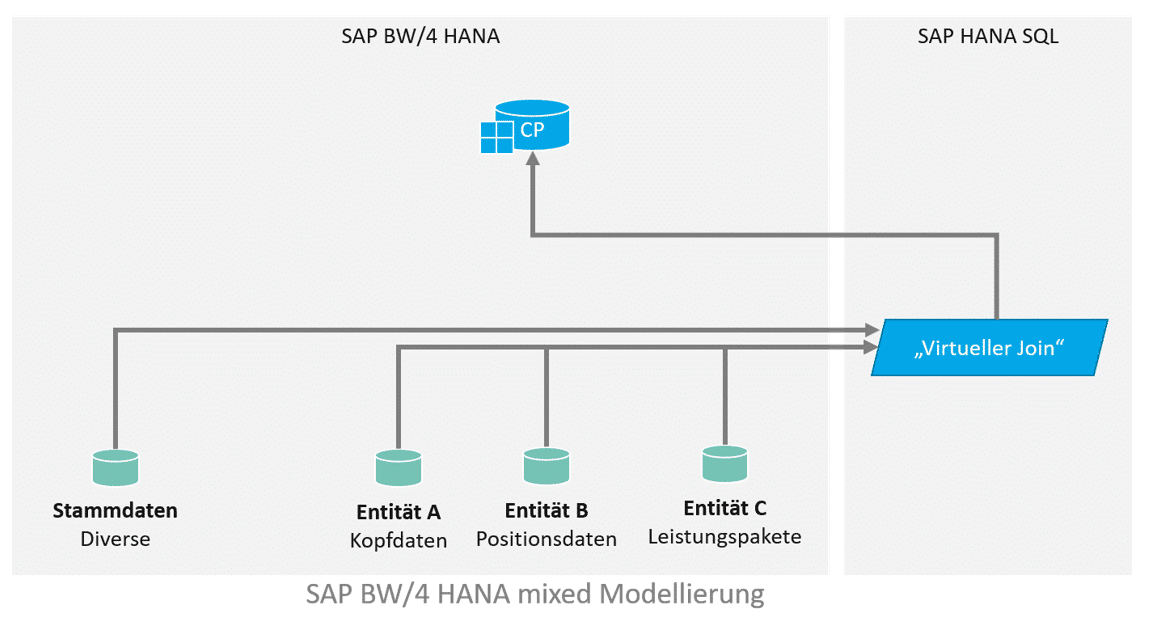
Bei der hybriden oder auch mixed Modellierung eines SAP BW basierten Data Warehouses werden Teile der Datenmodellierung über HANA SQL / native Mittel durchgeführt. Die Modellierung wird dabei in den meisten Fällen durch HANA Calculation Views durchgeführt.
Daher ist es sehr wichtig die Funktionsweisen von HANA Calculation Views zu verstehen, um sie korrekt in ein SAP BW getriebenes Data Warehouse zu integrieren.
Calculation Views erweisen sich in der Modellierung als sehr flexibel und oftmals auch sehr viel performanter als klassische BW-Transformationen mit ABAP Routinen. Gerade weil jedoch die Verarbeitung mittels grafisch modellierter CalcViews so einfach ist, können auch leicht nicht-optimale und unperformante Verarbeitungen entstehen. Der Join zwischen ungefilterten Basistabellen mit jeweils vielen Millionen Einträgen sorgt dann HANA-seitig für lange Laufzeiten, extrem hohen Speicherplatzverbrauch an RAM, und führt damit leicht zu der Fehlannahme, dass eine solche hybride Architektur mit virtueller Verarbeitung für den Anwendungsfall nicht geeignet sei.
Inhaltsverzeichnis
1. Aufschlag
1.3 Technik Aspekte
2. Retour
2.1 Beispiel
2.2 Optimierung
Durch optimale Modellierung und ein Design, welches Datenmenge und Verarbeitungszeit von vorneherein berücksichtigt, lässt sich jedoch häufig eine Lösung finden, die unter Nutzung der Vorteile von Virtualisierung eine akzeptable Lösung ohne redundante Persistenzen bietet.
Weisheiten der Software-Entwicklung
“The Best Optimizer Is Between Your Ears” – Michael Abrash
“Software is getting slower more rapidly than hardware
becomes faster.” – Wirthsches_Gesetz
Aufschlag
Konzeptionelle Aspekte
Bevor ein Calculation View zur Umsetzung von Business Logik einfach gebaut wird, ist es hilfreich folgende konzeptionelle Überlegungen anzustellen, um daraus ein Design für den Calculation View abzuleiten:
- Wie sieht das konzeptionelle Datenmodell aus? (→Relationales ER-Modell)
- Welche beteiligten Datenquellen (Tabellen, Views) werden benötigt, und wie stehen diese in Beziehung zueinander?
- Welche Ergebnisgranularität muss erzeugt werden? Beispielsweise Bestellungen auf Kopfebene (1 Ergebnissatz je Bestellung, mit ggf. bereits aggregierten Kennzahlen), oder einzelne Bestellpositionen (also auf Detailebene, mit nicht-aggregierten Kennzahlen)?
CalcView Design Aspekte
Viele Wege führen in einem relationalen Modell zum gleichen Ziel – doch sind nicht alle Wege gleich effizient.
HANA ist eine effiziente high-performance, spaltenbasierte in-memory Datenbank. Wunder kann die Execution Engine jedoch nicht bewirken. Ist erstmal der Ausführungsplan für eine CalcView-Abfrage ineffizient, entstehen auch auf einer HANA leicht minutenlange Wartezeiten, und noch viel schlimmer: Laufzeit-Speicherverbräuche von vielen GB RAM.
HANA & RAM
Ca. 50% des gesamten verfügbaren (lizenzierten) Speichers steht für die Persistierung von Daten zur Verfügung (“Hot”-Bereich, in-memory). Dies umfasst neben den reinen Nutzdaten auch sämtliche Meta- und Verwaltungsinformationen von BW und HANA.
Die anderen 50% des Speichers sind für die in-memory Verarbeitung von Anfragen reserviert. Entstehen somit zu viele parallele Anfragen mit extrem hohen Laufzeit-Speicherverbräuchen, führt dies dazu, dass die HANA persistente Daten aus dem Hot-Bereich temporär in den Warm-Bereich (auf Disk) verdrängen muss. Die Gesamtsystemperformance kann damit durch eine solche Überlast dramatisch einbrechen, und sollte daher stetig gemonitored und im Vorfeld möglichst vermieden werden.
Ausgehend von den Anforderungen und dem konzeptionellen Datenmodell sind daher folgende Design Aspekte wesentlich:
- Möglichst im untersten Schritt des CalcViews bereits eine möglichst kleine Datenmenge zur Weiterverarbeitung selektieren. Dazu:
- von der Granularität her eine geeignete Originärtabelle wählen. Anstatt direkt auf Bestellpositionen zu gehen macht, es ggf Sinn, zuerst eine relevante Teilmenge der Bestellköpfe zu selektieren, und diese (viel kleinere) Menge dann mit den entsprechenden Bestellpositionen zu joinen.
- Filter und Selektionen möglichst weit runterpushen, d.h. so früh wie möglich anwenden, idealerweise schon im untersten Projection-Node des CalcViews verwenden.
Die HANA Execution Engine ist durchaus effizient darin, Filter so weit wie möglich auf die Datenbank “runterzudrücken” (push down), jedoch sollte man sich nicht auf “magische Fähigkeiten” verlassen, und stattdessen durch ein kluges Design dem System unter die Arme greifen. - Tabellen und Views, die in einem CalcView verwendet werden, sollten zuerst in einen Projection-Node konsumiert werden, und nicht direkt in einem Union oder Join verwendet werden. Die Vorteile, diese über eine Projection bereitzustellen, umfassen:
- Möglichkeit, die Datenmenge im Projection Node direkt zu filtern.
- Möglichkeit, direkt im Projection-Node die erforderlichen Felder auszuwählen.
- Möglichkeit, bei mehrfachen Joins mit derselben Datenquelle den Projection-Node wiederzuverwenden.
- Kleine, modulare, geschachtelte CalcViews verwenden.
Fachlich ist es dem Ergebnis zumeist egal, ob ein großer CalcView mit vielen Joins, oder mehrere aufeinander aufbauende (geschachtelte) CalcViews mit weniger Joins erstellt werden.
Für die Execution Engine kann es zu Laufzeit jedoch wesentliche einfacher und effizienter sein, wenn mit mehreren geschachtelten CalcViews gearbeitet wird.
Werden diese möglichst modular gestaltet, so ist der positive Nebeneffekt auch eine bessere Übersichtlichkeit, Wartbarkeit und Wiederverwendbarkeit in der Gesamtarchitektur. - Möglichst Verzicht auf Berechnungen, die eine Verarbeitung von Detaildaten erfordern, bspw. Counter auf granularer Ebene.
Natürlich ist es fachlich nicht immer möglich auf diese Berechnungen zu verzichten.
In dem Fall sollten Berechnungen zumindest so weit wie möglich an einer Stelle zusammengefasst werden, und nicht über diversen Verarbeitungsschritte in mehreren CalcViews “verstreut” werden.
So kann die Execution Engine nach Durchführung der Berechnungen auf Basis der Granulardaten ggf immer noch in den nächsten Schritten die Ergebnismenge aggregieren. .
Technik Aspekte
Neben gutem Design der Calculation Views gibt es auch einige rein technische Optimierungsmöglichkeiten:
- Verwendeter Join-Typ – zur Wahl stehen: Inner Join, Referential Join, Left Join, Right Join.
- Grundsätzlich bieten Inner Join bzw. Referential Join die beste Performance (und sorgen für die kleinste Ergebnismenge).
- Referential Join darf nur gesetzt werden, wenn die Referentielle Integrität wirklich sichergestellt ist.
- Left Join (bzw. Right Join) sollten nur verwendet werden, wenn es hierfür auch fachliche Gründe gibt, wie beispielsweise Bewegungsdaten zu denen es nicht zwingend Stammdatenwerte gibt.
- Join-Optimierung – Referential Join und Left/Right Join bieten die Möglichkeit, das Flag “Optimize Join” zu setzen.
- Dies erfordert jedoch zwingend, dass die Join-Kardinalität korrekt angegeben ist. Eine inkorrekt gesetzte Kardinalität mit aktiver Join-Optimierung kann zu falschen Ergebnissen führen!
- Die Optimierung bewirkt keine Wunder, sondern arbeitet auf simple Weise: der Join wird optimiert (nicht ausgeführt), wenn er für das Ergebnis nicht notwendig ist. Im Falle eines Left Join also dann, wenn kein Feld aus der rechten Tabelle für die Ergebnismenge angefordert wurde. Da es sich um einen Left Join handelt, bestimmt also die Linke Tabelle alleine die Ergebnismenge, und der Join kann problemlos ignoriert werden.
- HANA bietet Funktionen, die eine Optimierung von Joins oder Ergebnismengen verhindern, in dem ein bestimmtes Granularmerkmal als nicht-optimierbar (nicht aggregierbar) deklariert wird. Diese Funktionen sind Keep Flag sowie Transparent Filter. Diese Funktionen sollten daher mit Vorsicht verwendet werden – sie sind aus fachlichen Gründen zwar teilweise erforderlich, haben aber entsprechende Auswirkungen auf die Laufzeit-Performance und den Speicherbedarf!
Retour
Beispiel
Das folgende Beispiel soll verdeutlichen, wie durch ein Redesign eines CalcViews entsprechend der obigen Prinzipien eine erhebliche Performance-Steigerung erzielt werden kann.
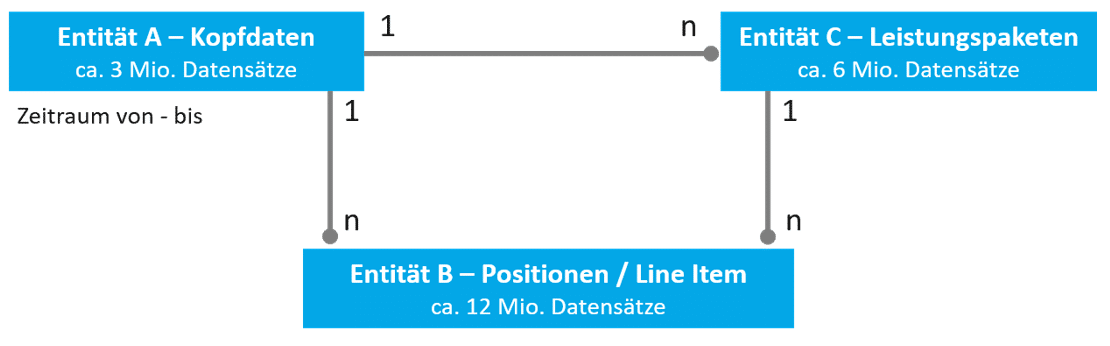
Gegeben sei ein Datenmodell mit den folgenden Entitäten und Relationen:
- Entität A steht in 1:n Relation mit Entität B. A repräsentiert Kopfdaten (ca. 3 Millionen Einträge), B repräsentiert Line Items (>12 Millionen Einträge).
- Entität A steht ebenfalls in 1:n Relation mit Entität C, welche eine Zwischengranularität darstellt (bspw. Leistungspakete). Es sind ca. doppelt so viele Einträge wie A, als knapp 6 Millionen.
- Entität C steht daher auch in 1:n Relation mit Entität B.
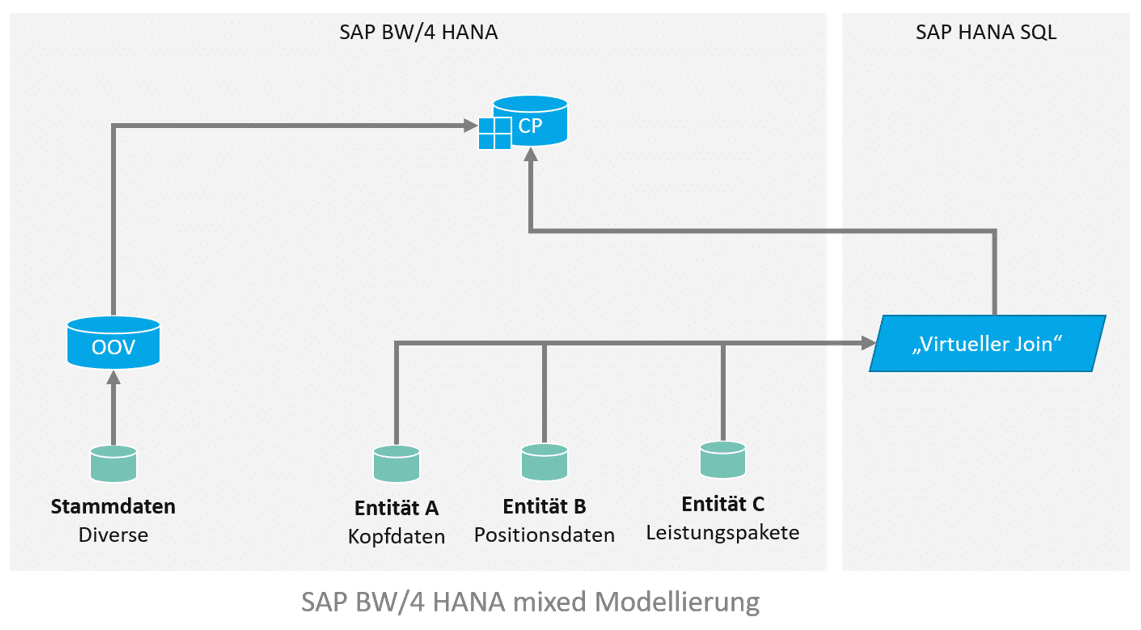
Für die Implementierung sollen alle Line Items und Leistungspakete ausgegeben werden, die in einem bestimmten Zeitraum liegen. Das Datenmodell sieht in etwa so aus und sieht einen virtuellen Join zwischen den Entitäten vor, welcher in einen Composite Provider aufgenommen wird. In dem Composite Provider gibt es weitere Assoziierungen. Die gewünschte Filterung des Zeitraums kann über Input Parameter erfolgen, welche auf die Felder “Von” und “Bis” in Entität A filtert, via eigener Filter Expression (“Von” <= SELEKTIONSZEITRAUM_ENDE and “Bis” >= SELEKTIONSZEITRAUM_ANFANG).
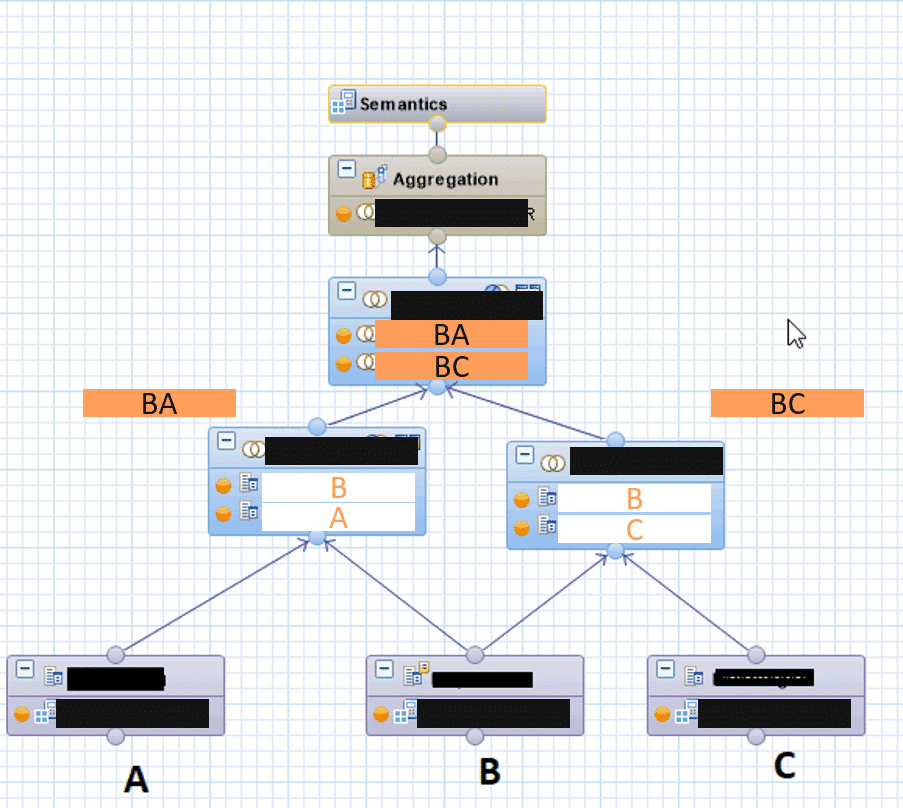
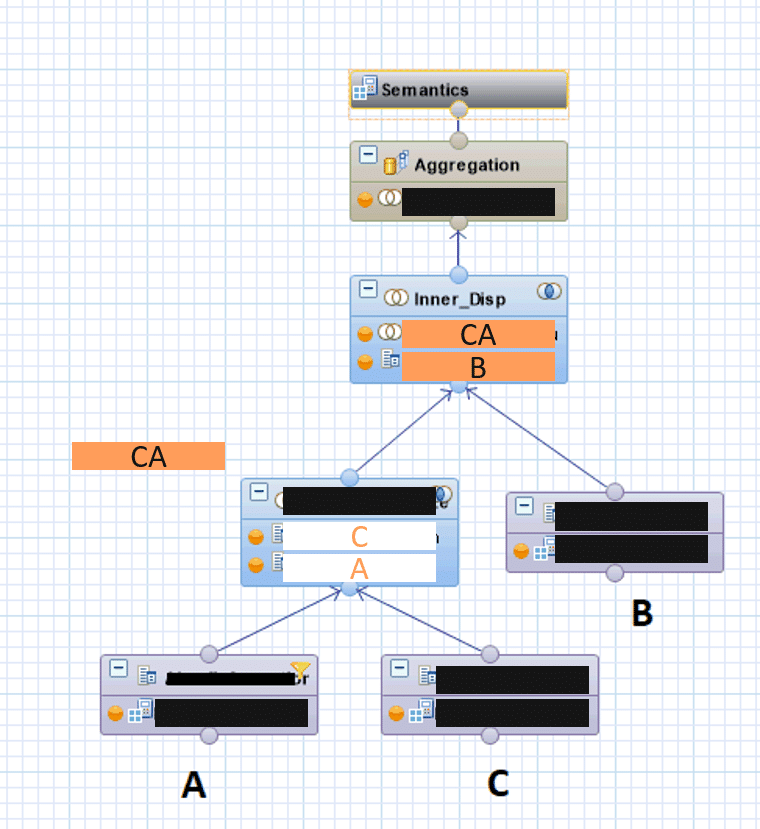
Eine erste naive Implementierung eines CalcViews sieht wie folgt aus:
- alle fachliche vorhandenen Joins werden via Left Join durchgeführt.
- die Teilergebnismengen werden ebenfalls per Join zusammengeführt (Left Join)
- Auf der resultierenden Gesamtergebnismenge wird die Filter Expression definiert.
- Die Verknüpfung mit zusätzlichen Stammdaten erfolgt im BW Composite Provider via Assoziation.
- Weitere Stammdaten werden erst später (per Assoziation mit einem OpenODS View) BW-seitig im Composite Provider dazu gelesen.
Datenmodell
Dies ergibt folgenden CalcView:
Performance
Der CalcView ist lauffähig und liefert fachlich die korrekten Ergebnisse.

Der HANA PlanViz zeigt jedoch, dass der ausgeführte Execution Plan alles andere als optimal ist:
- Die Ausführungszeit beträgt mehrere Minuten
- Der Speicherverbrauch übersteigt 200 GB RAM
Der CalcView ist damit so produktiv nicht nutzbar.
Optimierung
Die wesentliche Optimierung ist, den CalcView grundlegend unter Beachtung von Performance-Aspekten neu zu designen.
Dazu werden folgenden Überlegungen angestellt:
- Die Ergebnismenge soll so frühzeitig wie möglich eingeschränkt werden. Der unterste Knoten im CalcView soll daher eine Projection auf Entität A sein, welche nur den Primärschlüssel sowie die Felder Von und Bis beinhaltet. Diese werden direkt auf der untersten Ebene mittels der Filter Expression (mit den Input Parametern) eingeschränkt.
- Diese minimale Ergebnismenge wird mit Join auf Entität C, die nächstdetaillierte Granularität, ergänzt.
- Erst im dritten Schritt erfolgt der Join mit der größten und detailliertesten Menge B, den Line Items.
- Durch Verwendung von Inner Joins werden alle fachlich ohnehin nicht relevanten Daten eliminiert, und gleichzeitig so (aufgrund der Schnittmenge) die Ergebnismenge kleinstmöglich gehalten.
Wäre dies fachlich nicht möglich, so würden weiterhin Left Joins verwendet werden, jedoch diesmal mit gesetzter Kardinalität (1:n) und aktivierter Join-Optimierung.
Im günstigsten Fall könnte der Execution Plan dann den Join mit den Line Items sogar weglassen. - Zusätzlich wurde auf die BW Stammdatenassoziation im Composite Provider verzichtet, und stattdessen mit den Stammdaten A* direkt gejoined.
Zur Modularisierung und Wiederverwendung ist dieser Join in einem separaten CalcView ausgelagert.
Datenmodell
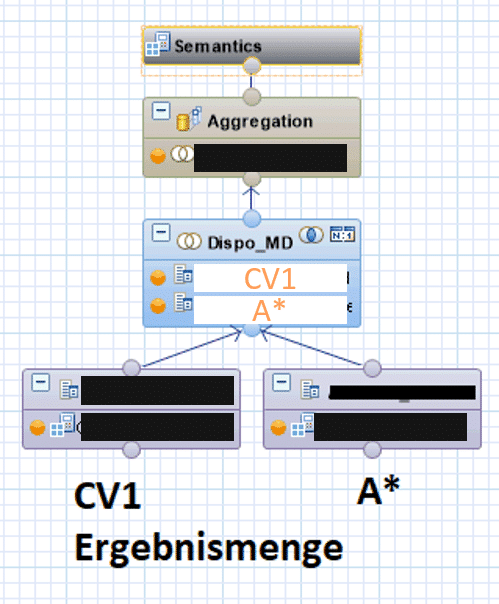
Dies ergibt folgende geschachtelte CalcViews:
Der innere CV verbindet die Ergebnismenge (von Grobgranular hin zu Line Items) und filtert die Ergebnismenge so frühzeitig wie möglich.
Der “äußere” CalcView nimmt diese Ergebnismenge und führt den Join mit den zusätzlichen Stammdaten A* durch.
Da fachlich hier in diesem Fall die Referentielle Integrität sichergestellt ist (es gibt keine Bewegungsdaten ohne Stammdaten), kann ebenfalls ein performanter Inner Join genutzt werden.
Tipp
Diese Optimierung ist auch für die Assoziation in einem Composite Provider verfügbar – Einstellung “User confirmed referential integrity”
(Siehe auch: https://wiki.scn.sap.com/wiki/display/BI/HCPR%3A+Referential+Integrity)
Damit ergibt sich folgender äußerer CalcView (welcher die finale Ergebnismenge erzeugt):
Performance nach Optimierung
Die geschachtelten CalcViews liefern inhaltlich die gleichen Ergebnisse wie die erste Lösung.

Der ausgeführte Execution Plan ist in diesem Fall jedoch deutlich optimaler:
- Die Ausführungszeit beträgt nur noch wenig mehr als 10 Sekunden
- Der Speicherverbrauch beträgt weniger als 10 GB RAM
Der CalcView ist damit nicht nur angenehm für den Endanwender zu nutzen, die Systemstabilität bei einem Deployment in Produktion (und entsprechender paralleler Nutzung durch mehrere Anwender gleichzeitig) ist ebenfalls gewährleistet.
Spiel, Satz und Sieg
Mit einem konsequenten Redesign untert Berücksichtigung der Performance-Aspekte konnte somit der Ressourcenverbrauch zur Laufzeit um Faktor 20 gesenkt werden. In Summe verursachen die entsprechenden Redesigns kaum einen Tag Aufwand; dem gegenüber steht ein erheblicher Nutzen für die Gesamtarchitektur.

Christopher Kampmann
Head of Business Unit
Data & Analytics
christopher.kampmann@isr.de
+49 (0) 151 422 05 448


