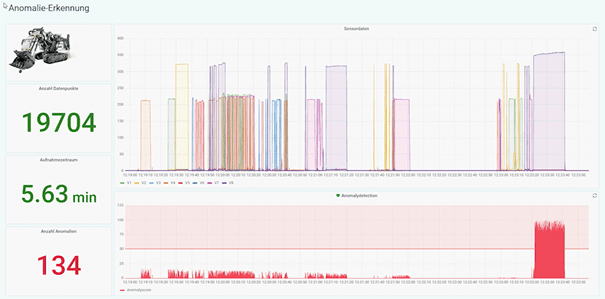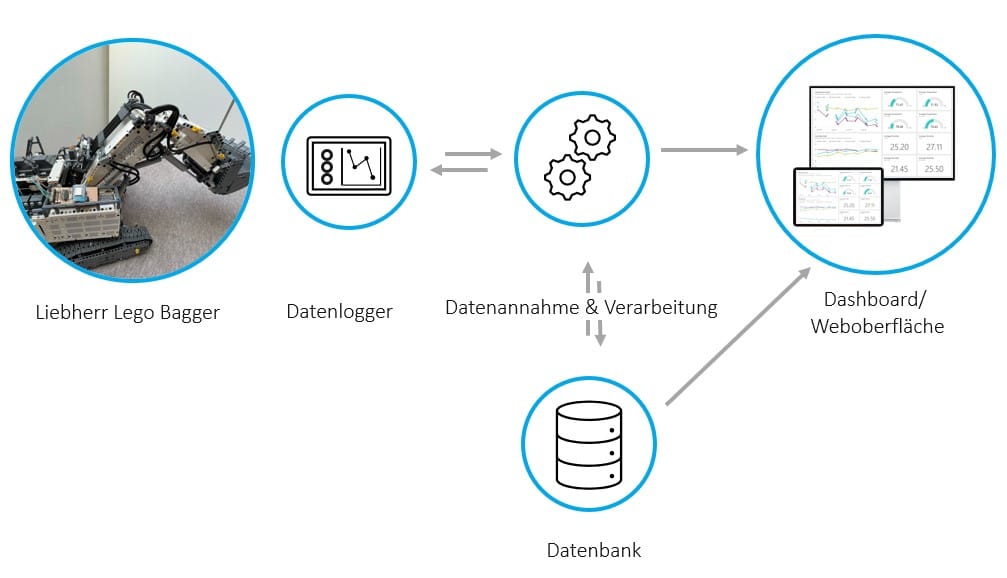
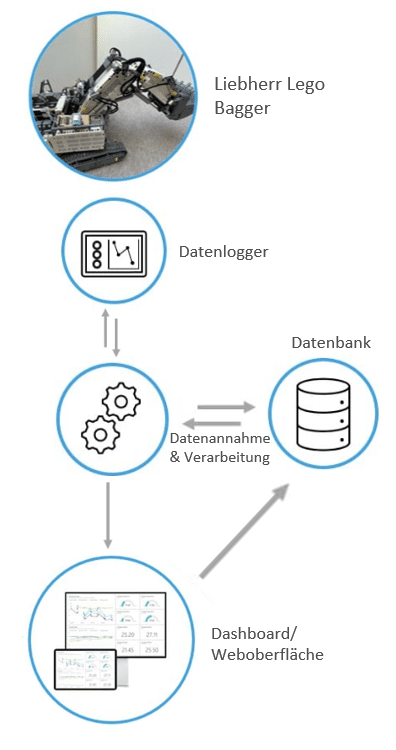
Interquartile range
In the interquartile method, a range is defined around the median of the sample set. All observations outside this range are identified as outliers.
GESD (Generalized Extreme Studentized Deviate Test)
Hypothesis tests are performed using the following test statistics ![]() where x_Strich represents the sample mean and sigma represents the standard deviation of the sample.
where x_Strich represents the sample mean and sigma represents the standard deviation of the sample.
The null hypothesis is that there are no outliers in the data set. The alternative hypothesis is that there are up to r outliers. r tests are performed as long as the test statistic exceeds a critical value. After each test, the data point with the greatest distance from the arithmetic mean is removed from the data set as a detected outlier and the test statistic is recalculated.
Dbscan
Dbscan is a clustering method that determines clusters based on density. A point is considered dense if at least MinPts points are located in an environment with a radius of ɛ around the point. Various metrics, such as the Euclidean metric, can be used to determine the distance between points.
The procedure distinguishes between three types of points. The first type of points are core points. These are points that are dense. The second type are dense-reachable points. These are points whose e-neighborhood contains fewer than MinPt points but which are reachable from a core object of the cluster. Reachable means that the distance between two points is less than e. The third type are outliers. These are points that are not dense-reachable from other points.
A cluster is characterized as follows: All points in the cluster are densely connected. Two points are described as densely connected if there is a point from which both points are densely reachable. If a point is densely reachable from any point in the cluster, then this point is part of the cluster. This method therefore identifies outliers as independent, non-dense clusters.
Isolation Forests
This method is based on binary decision trees. To train a decision tree, a feature is selected at random and a random split is performed based on a value of that feature.
The isolation forest is then created by combining all isolation trees, using the average of their results.
Each observation is compared to the isolation value in a node. The number of isolations is called the path length. The assumption is that outliers have shorter path lengths than normal observations.
The outlier score is then determined as follows 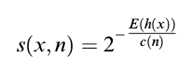 where h(x) is the path length of observation x, c(n) is the maximum path length of the tree, and n is the number of nodes in the tree. The value lies between 0 and 1. The higher the value, the more likely the observation is an outlier.
where h(x) is the path length of observation x, c(n) is the maximum path length of the tree, and n is the number of nodes in the tree. The value lies between 0 and 1. The higher the value, the more likely the observation is an outlier.
K-Nearest Neighbor
The K-Nearest Neighbor algorithm can also be used to identify anomalies. The distance of a data point to the k nearest neighbors is used as the measure for the outlier score.