Even the ancient Greeks dreamed of happiness without human intervention and entrusted this task to the goddess Automatia (Georges). Two millennia later, humanity has come a long way toward realizing this dream in many areas and is working hard to further reduce the proportion of human activities in value creation.
One area in which the concept of automation has become increasingly established in recent years is data warehousing. In this blog, we want to clarify what data warehouse automation (DWA) is all about and why it is worth considering automation in this relatively young discipline.
What is the purpose of data warehouse automation?
Data warehouse automation aims to replace manual tasks that repeatedly arise during the development and implementation of a data warehouse and account for a large part of the workload with automated software processes. The aim is to simplify and accelerate data warehousing and conceptually transfer it to lifecycle management, which provides clearly defined and largely automated steps for the development, maintenance, and further development of a data warehouse.
How does data warehouse automation work?
Wastewater management requires implementation at various organizational levels. Looking at the big picture and then moving into the specifics, the following aspects can be noted:
1. Lifecycle concept
In line with the lifecycle concept, automation first requires a fundamental structuring of data warehousing processes. Even today, data warehousing is often a complex area in which different tools are used by different stakeholders. Therefore, when it comes to automating individual tasks, it is important to place the development work on the data warehouse within a uniform framework and to clearly define the interrelationships between the individual activities. In this context, general approaches to agile software development provide a good basis.

In particular, the DevOps philosophy has proven itself in recent years as a holistic development approach with a strong focus on continuous output and a high degree of automation in many software projects. Through a clear phase model and specific continuity processes (Figure 01), DevOpsWhat is DevOps? The term DevOps is composed of the words... More also provides a good basic concept for implementing DWA. If you are not yet familiar with DevOps, you can find an introduction.
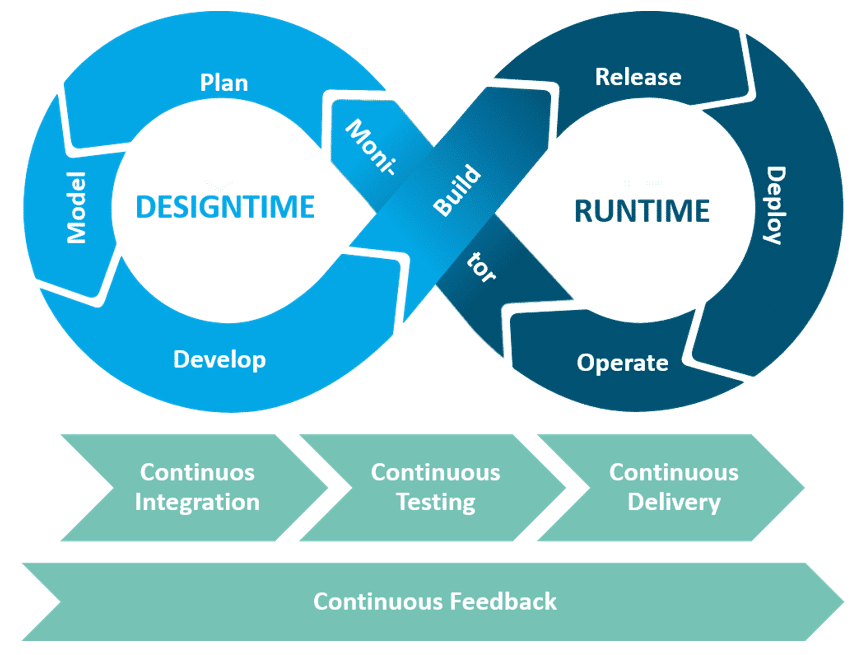
Figure 01:DevOps process model for data warehousing
2. Model-driven development
Database models play an important role in the development of a data warehouse. DWA is therefore usually accompanied by model-driven development approaches that link different models and enable a methodically clean path from abstract business considerations to concrete technical implementation in the data warehouse. This approach already offers a high potential for automation within model-driven approaches, which in this respect only needs to be leveraged within the context of DWA and integrated into the DWA lifecycle concept in a well-defined form (basic information on model-driven development can be found here). One form of modeling that has gained enormous importance in this context in recent years and occupies a central position in many model-driven DWA approaches is Data Vault. The approach to data modeling in data warehouses published by Dan Linsted in the early 2000s is now available in version Data Vault 2.0 and is valued by experts for its characteristics in terms of agility, historization, and automation. Agility refers to the ability to easily adapt the Data Vault model on an ongoing basis, which meets the needs of many companies today. Historization, on the other hand, means that despite ongoing adjustments, no data is lost and analysis options remain available. The potential for automation arises from the simple rules that Data Vault follows (there are only three modeling elements, see Figure 02). This allows models to be generated in whole or in part and corresponding loading processes (ETL) to be created automatically.
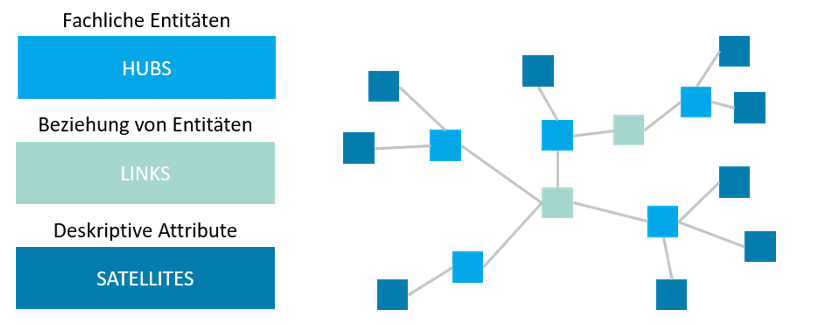
Figure 02:Modeling elements Data Vault
3. Automated activities
After these rather fundamental but nevertheless important aspects of data warehouse automation, the question arises as to which specific activities can be automated. The following work steps and processes can be mentioned:- Source connection: Connecting source systems is a process that can be largely automated through reverse engineering. Reverse engineering involves reading the metadata of the source systems, i.e., the data that provides information about how the data is organized in the respective source system, and making it available for further processing in the data warehouse. In this way, source connection plays a central role in the preparation of the various data models in the data warehouse, as the metadata from the source systems serves as a basis that is simply converted, expanded, and supplemented according to specific rules.
- Object generation: Object generation refers to the individual elements in the various data models of the data warehouse. The different data models result from the layered architecture of a data warehouse, which usually consists of two or three levels. The Data Vault data model is usually at the center. It specifies the essential rules based on real business conditions. The definition of the specific rules cannot therefore be automated. However, once this work has been done, most of the objects can be generated automatically in conjunction with the metadata from the source systems.
- ETL generation: In classic data warehousing, data from OLTP systems is transferred to the OLAP system of the data warehouse using extract, transform, and load (ETL). More modern solutions also work with virtual connections, in which the data is available in the data warehouse but physically remains in the source system. In both cases, the data flows must be designed. With DWA, this work can also be highly automated as a by-product of the previous steps of source connection and object generation.
- Continuous integration, testing, and delivery: Continuous integration, continuous testing, and continuous delivery are terms used in agile software development and are now specifically associated with the DevOps philosophy. Together, these continuity processes aim to continuously integrate smaller developments or development stages and deliver them in production environments in order to achieve usable added value as quickly as possible and to detect undesirable developments as quickly as possible. An important factor here is the highest possible degree of automation, especially with regard to various tests. With DWA, this requirement can also be implemented in the data warehouse, as the models are fully integrated, allowing a delivery chain to be built across the various layers of the DWH. This can be run automatically using specific deployment tools, and predefined tests can be carried out within this framework.
- Documentation: Through the comprehensive integration of various activities, DWA ensures automatic documentation of all processes and dependencies. This includes, in particular, clear data lineage, i.e., the traceability of data through the various layers of the data warehouse or across different OLTP systems, as well as information about who made changes and when.
What are the advantages of data warehouse automation?
The main advantage of DWA, and the main reason for using such approaches, is the acceleration of data warehousing processes. However, DWA only partially fulfills the dream of happiness without human intervention. Business processes still have to be modeled by humans, and the data has to be correlated according to specific rules. In addition, humans continue to play a supervisory role in all areas, using their comprehensive knowledge to control and monitor the entire process. DWA therefore aims to limit human work to the supervisory function, away from analytical modeling tasks, and to simplify this as much as possible. Repetitive tasks that follow schematic rules are taken over by software. In addition, schematic tests are defined once and then continuously executed by software. This results in significant time savings, allowing data warehouse users to benefit more quickly from data-driven analyses in order to drive their core business forward with decisions. From a human perspective, this also makes data warehousing more enjoyable, as the work focuses on creative activities.
Time is closely related to quality. Requirements can usually be met more cleanly when there is not too much time pressure. DWA can improve both aspects by eliminating time-consuming and error-prone repetitive tasks. In addition, DWA seeks to improve the control function of the data warehouse developer. This allows the developer to better monitor whether the development meets the requirements. In terms of quality assurance, there is also the issue of increased initial effort. The rules and tests according to which the DWA software works must be defined at the outset. However, the software's fast and clean execution makes this effort worthwhile in terms of both time and quality. Comprehensive documentation also makes it easier and faster to track down and fix any errors that do occur.
From both perspectives, this basically leads to a reduction in data warehousing costs, as productivity increases. However, due to the necessary investments in software and expertise to implement corresponding DWA approaches, such a calculation cannot be made across the board. The arguments lie primarily in the points mentioned first. Overall, cost savings are most likely to result from increased quality. DWA prevents undesirable developments at an early stage and enables comprehensive and simple control mechanisms despite fast processes. However, this aspect is difficult to measure in monetary terms and reveals the fundamental problem of prevention strategies, which are already successful when processes run as planned.
What solutions are available?
There are now a number of offerings on the market for DWA solutions, ranging from complete solutions to more methodically oriented approaches with individual tooling. We cannot review all solutions here. However, in our next blog on this topic, we would like to explain the DWA processes of SAP HANA SQL Data Warehousing in more detail. You can also find a list of providers from 2019 here.

Conclusion
In this blog, we have explained the basics of data warehouse automation and looked at the advantages of this development concept. In times when dynamic economic conditions require rapid adjustments to evaluation bases in order to make well-founded, data-based decisions, it is worth considering DWA strategies. For the SAP environment, we would like to introduce you to the advantages of SAP HANA SQL data warehousing in our next blog. If you have any questions about DWA or SAP HANA SQL data warehousing, please feel free to contact us.
Author: Eckhard Schulze, Martin Peitz

Christopher Kampmann
Head of Business Unit
Data & Analytics
christopher.kampmann@isr.de
+49 (0) 151 422 05 448


