In this blog series, we focus on the HANA SQL Data Warehouse as an open platform. This first article serves as an introduction and outlines four key aspects that define the openness of the SAP HANA SQL Data Warehouse.
In the coming weeks, each individual aspect will be addressed again in a separate blog post and discussed in detail:
Blog post 1: General interchangeability of components (published August 4, 2020)
Blog post 2: Freedom of modeling (published September 1, 2020)
Blog post 3: Data-driven business apps (published September 29, 2020)
Blog post 4: Deployment infrastructure (published October 20, 2020)
Once the blog posts have been published, you can access them here. We will inform you about the publication via our newsletter and social networks. Below you will find a preview of each blog post, which briefly summarizes what you can expect.
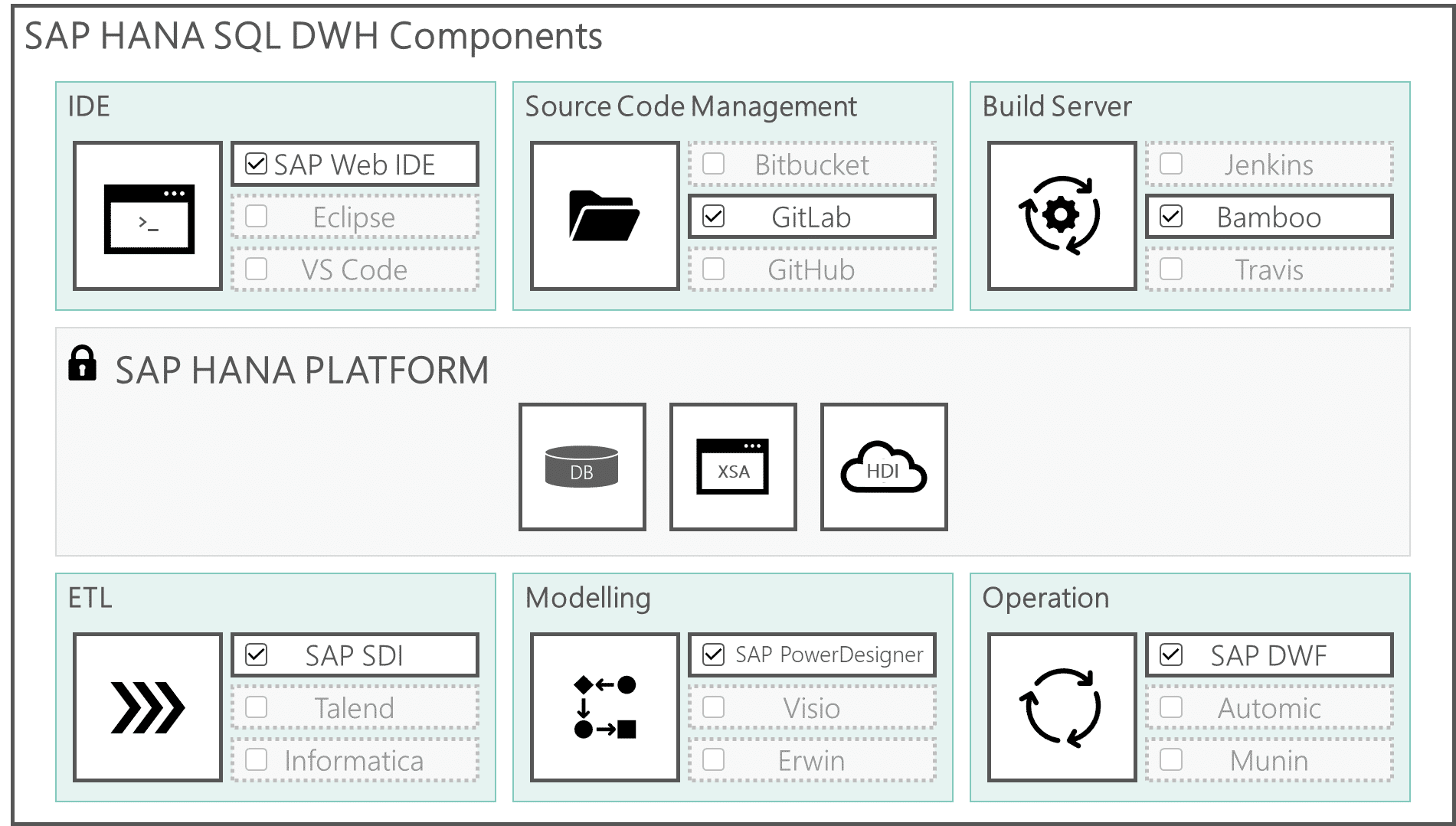
Preview of blog post 1: General interchangeability of components
As its name suggests, the SAP HANA SQL Data Warehouse is based on the SAP–HANA–platform. This platform offers a DBMS, an application server, and a transport infrastructure and other useful tools that can be used for the development and operation of the DWH.
In addition to SAP proprietary software, there are also many open source tools available that can be integrated. Virtually all components are interchangeable.
In this blog post, we will take a closer look at the general interchangeability of these components and highlight the advantages and disadvantages of certain components: Click here for the article.
Preview of blog post 2: Modeling freedom
When it comes to data models, SAP HANA SQL Data Warehouse has no specifications or limitations. Quite the contrary. The modeler can decide entirely on their own what information the model contains and is not dependent on predefined information frameworks.
He can also choose which modeling technique (e.g., third normal form, star schema, data vault, etc.) he would like to use.
In this blog post, we will take a closer look at the modeling freedom of the SAP HANA SQL Data Warehouse and discuss specific modeling techniques in more detail. We will focus primarily on the Data Vault methodology. The post will be published on November 3, 2020.
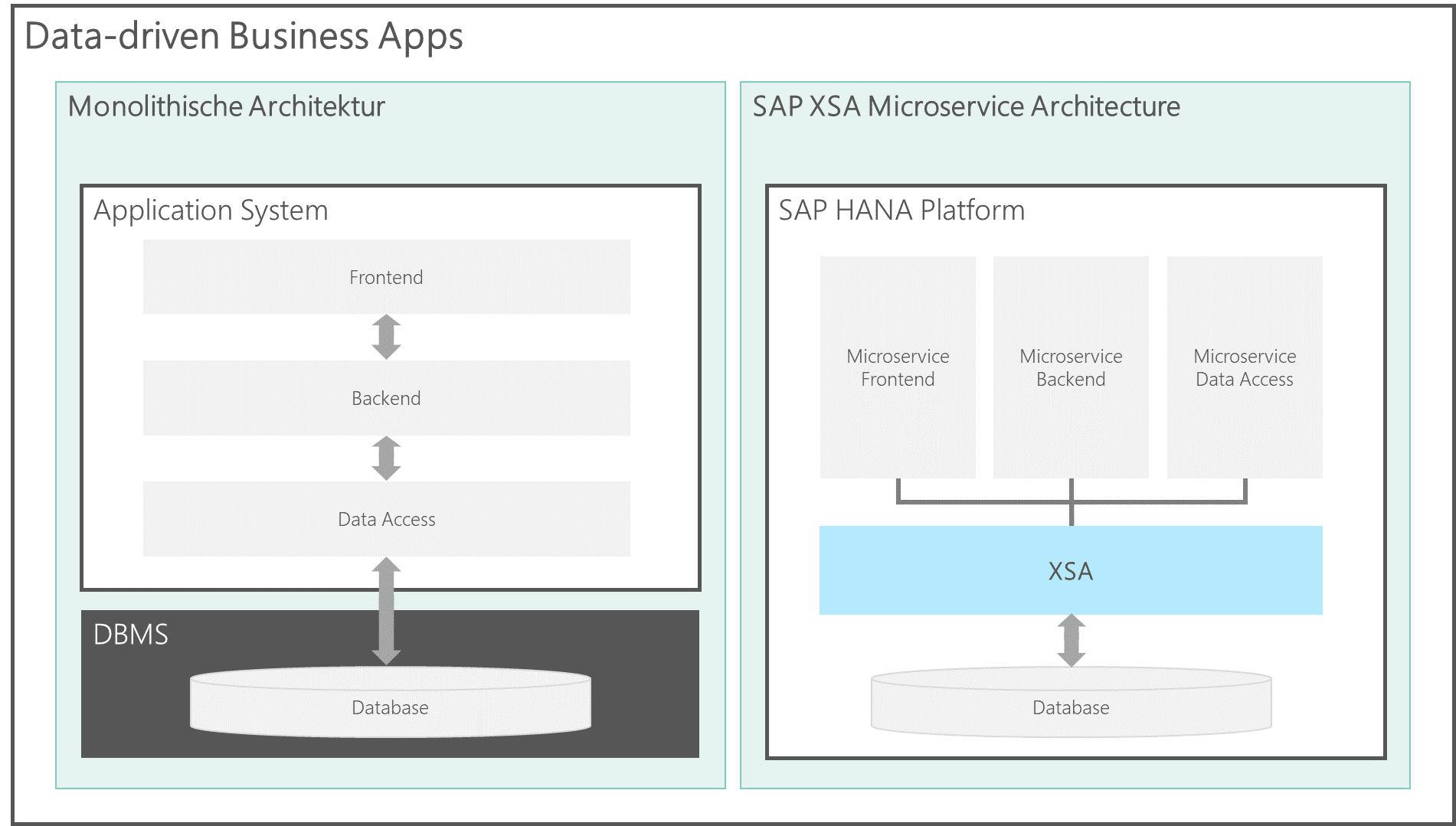
Preview of blog post 3: Data-driven business apps
As already mentioned in blog post 1 (General interchangeability of components), SAP HANA SQL DWH is based on the SAP HANA platform. Technically, this platform is built on a microservice-based cloud architecture (CloudFoundry).
This architecture makes it possible to develop and operate complete full-stack applications on a single platform. Since the front end, back end, and database share a platform in these applications, they deliver high performance—especially when processing large amounts of data.
Under the heading "Data-driven Business Apps," this blog post will show you how to develop customized, high-performance applications on the SAP HANA platform that directly access the data persistence of the SAP HANA SQL Data Warehouse. The post will be published on December 29, 2020.
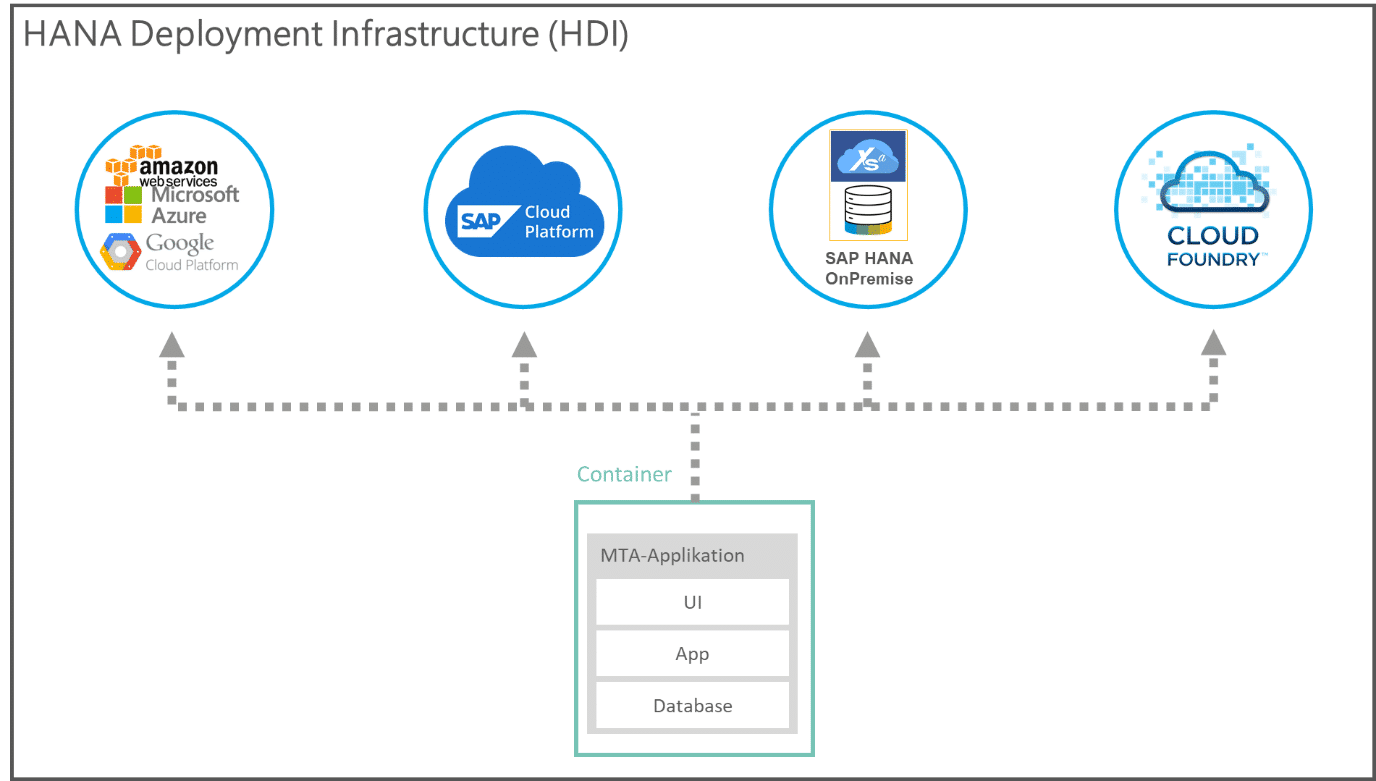
Preview of blog post 4: Deployment infrastructure
Another aspect in which the SAP HANA SQL Data Warehouse stands out for its particular openness is the deployment infrastructure, which results from the technical structure of the SAP HANA platform.
SAP HANA Deployment Infrastructure (HDI) enables objects to be deployed in containers. In addition to database objects, these containers can also contain complete (MTA) applications. With SAP HDI, you can deploy conventionally to an SAP HANA XSA or Cloud Foundry system on-premises or move the deployment to the cloud. A wide range of deployment options are available.
In this blog post, we examine the HANA Deployment Infrastructure in relation to the XSA/Cloud Foundry architecture and show how the HDI affects the openness of the SAP HANA SQL Data Warehouse. We also take a separate look at multi-target applications (MTA) and their significance for deployment.
Since 1993, we have been operating as IT consultants for Data Analytics and Document Logistics, focusing on data management and process automation. We provide comprehensive support, from strategic IT consulting to specific implementations and solutions, all the way to IT operations, within the framework of holistic Enterprise Information Management (EIM). ISR is part of the CENIT EIM Group.