After a model has been trained and demonstrates high performance, the subsequent step involves determining how to productively utilize the trained Machine Learning model.
Key challenges in this context include the automation of model training, model deployment, and ongoing monitoring.
This blog post explains how these challenges can be addressed and outlines the steps required for operationalizing a Machine Learning solution. It presents an example architecture for operationalizing Machine Learning models, which is based on the MLOps approach.
Furthermore, it addresses how the results can ultimately be made accessible to end-users.
Steps for Operationalizing Machine Learning Models
The initiation of a Data Science project represents an experimental phase. During this phase, the focus is on gaining insights and identifying relationships from the data through exploratory data analysis, and subsequently training a model that serves the defined business objective.
Typically, exploratory data analysis, initial data processing, and modeling are conducted in Jupyter Notebooks. In addition to code, these notebooks contain markdown cells, which are textual sections used for documenting insights.
For the operationalization of a Machine Learning model, this initial manual workflow of model development must be automated. To automate this process and facilitate continuous model development, it is necessary to integrate the code into a Machine Learning pipeline. A Machine Learning pipeline is a sequence of steps, where each individual step performs a specific task, such as data provisioning, data cleansing, or model training.
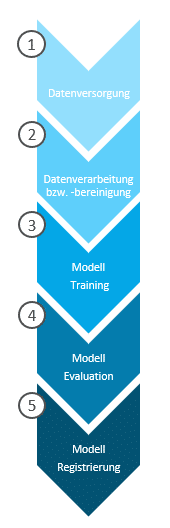
The figure below illustrates an exemplary Machine Learning pipeline for model development, which will subsequently be summarized and described in detail:
Fig. 1: Machine Learning Pipeline | isr.de
Fig. 1: Machine Learning Pipeline | isr.de
1. Data Provisioning
The first step involves establishing interfaces to the source systems where the data for training and testing a Machine Learning model are maintained. There are two methods for providing data for modeling. The first approach is virtual live access to the data within a source system.
In this approach, the data remains within the source system and is not physically transferred to the machine learning environment. The second variant involves importing the data from the source system into the machine learning environment. The benefit of this approach is the capability for data versioning.
2. Data Processing and Cleansing
The second step involves the code for data cleansing and processing. This step includes, but is not limited to, the following tasks:
Removal of duplicates or erroneous data
Removal or imputation of missing data using statistical values (e.g., average)
Transformation of data into a different format
Generation of new variables
Data aggregation
Data separation
Data cleansing and processing is typically the most time-consuming step in the data science process.
3. Model Training
The third step encompasses the code for model training. After dividing the data into training and test datasets, variables and the machine learning algorithm are selected. A machine learning model is then trained based on the training data, variable selection, and the chosen machine learning algorithm.
For certain algorithms, hyperparameters, which govern model training, must be defined in advance. This typically involves an algorithmic search for the optimal hyperparameters.
4. Model Evaluation
Subsequently, the trained model is evaluated using the test data in the next step. This involves generating predictions for the test dataset using the model and comparing them with the actual values to assess the predictive performance of the trained model.
5. Model Registration
In the final stage of the machine learning pipeline, the model is stored in a model registry. This process also includes model versioning.
Machine Learning Operations (MLOps) Approach
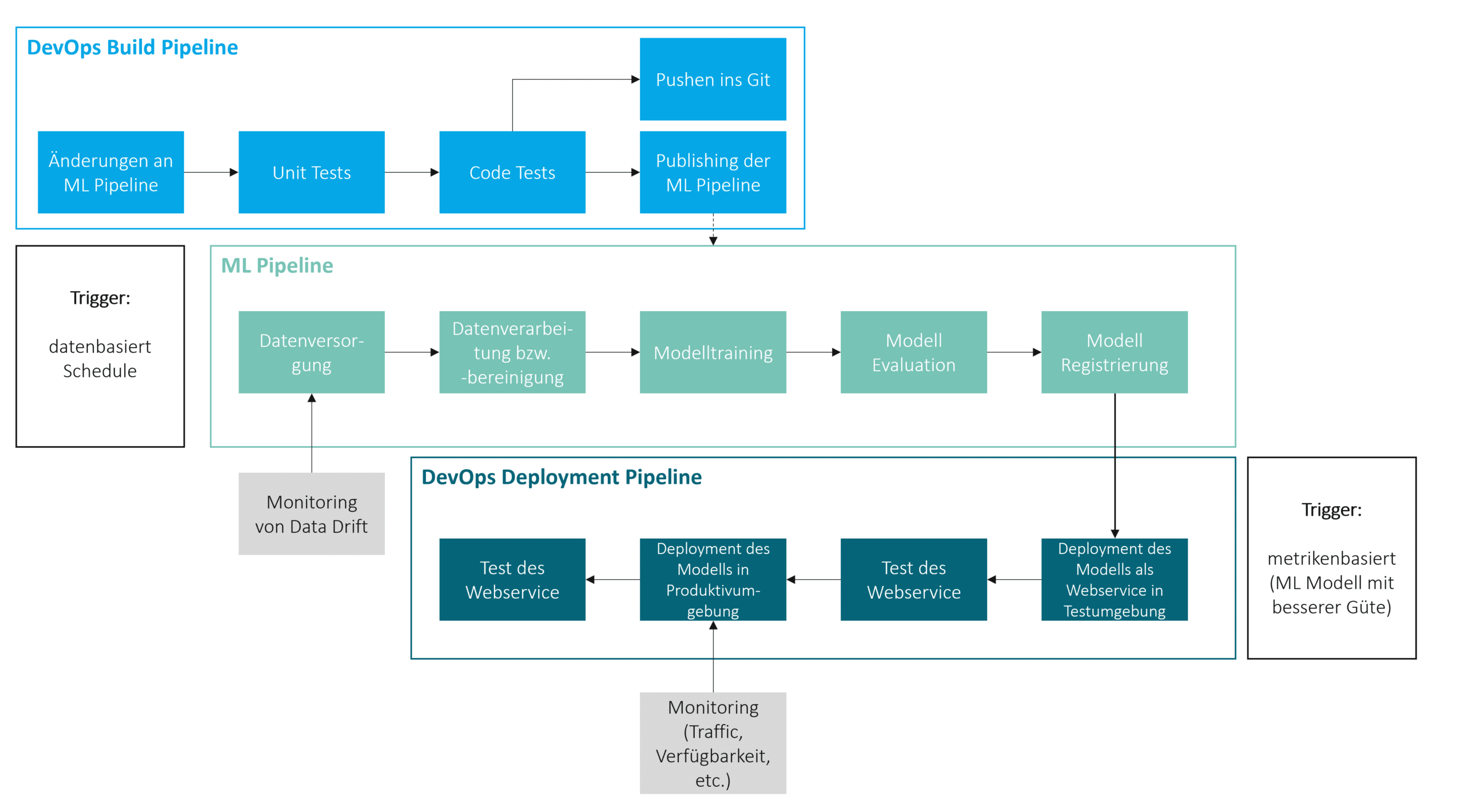
The automated execution of the machine learning pipeline can be data-driven, triggered by the presence of new or modified data in the source system, or time-based, through scheduling. In addition to executing machine learning pipelines, other key aspects of operationalization include automating the publication of machine learning pipelines after adjustments, as well as automating the deployment and monitoring of machine learning solutions. Within this context, the MLOps approach has become well-established.
Machine Learning Operations (MLOps) is the application of the DevOpsWhat is DevOps? The term DevOps is composed of the words... More concept from software development to machine learning. Within the MLOps framework, MLOps pipelines are defined to automate the previously described tasks. For example, an MLOps pipeline can be created for the automated, continuous publication of the machine learning pipeline. This MLOps pipeline is triggered by changes to the machine learning pipeline and first initiates automated tests, such as unit tests and code quality tests. If the tests are successful and the changes are error-free, the machine learning pipeline code is automatically pushed to Git, and the latest version of the training pipeline is published in the machine learning environment. This new version can then be utilized for model development.
Furthermore, an MLOps pipeline can be established for the automated, continuous deployment of a machine learning model. This pipeline can be triggered, for example, by the availability of a new model demonstrating superior predictive performance. The predictive performance is determined using a predefined metric, such as the Mean Absolute Error. In a two-system landscape, the model is typically first deployed and tested as a web service in the test environment. If these tests are successful, the model is then deployed and tested in the production environment. Following successful testing, a production-ready machine learning model, capable of delivering predictions, becomes available.
Authentication and Monitoring
An authentication method should be implemented for the production machine learning model to prevent unauthorized access. If the model is deployed as a web service, token-based or key-based authentication is typically utilized.
To ensure the avoidance of outages and minimization of downtime for the production machine learning model, a service for monitoring its availability and utilization should be employed. Additionally, monitoring other architectural components can be advantageous. For instance, a data drift—a significant alteration in source data—can lead to a dramatic decline in the predictive performance of a machine learning model for new data. Consequently, it is often advisable to utilize a service that continuously checks data from source systems for data drifts.
The following illustrates an example of an MLOps architecture for the operationalization of machine learning models.
Fig. 2: MLOps Architecture for Operationalizing ML Models | isr.de
Utilizing the Results
Typically, due to corporate compliance requirements, predictions do not result in automated decisions but instead support employees in their decision-making processes. Consequently, the predictions generated by a machine learning model should generally be made accessible to employees.
The results or predictions can be made available to end-users from the business departments either by feeding the predictions back into an existing system or by creating a new application.
Depending on the requirements, predictions are generated in real-time or in batches at specific intervals and transmitted to the target system. Real-time generation means that new predictions are triggered immediately when prediction-relevant input data changes or new prediction-relevant data becomes available in the source system.
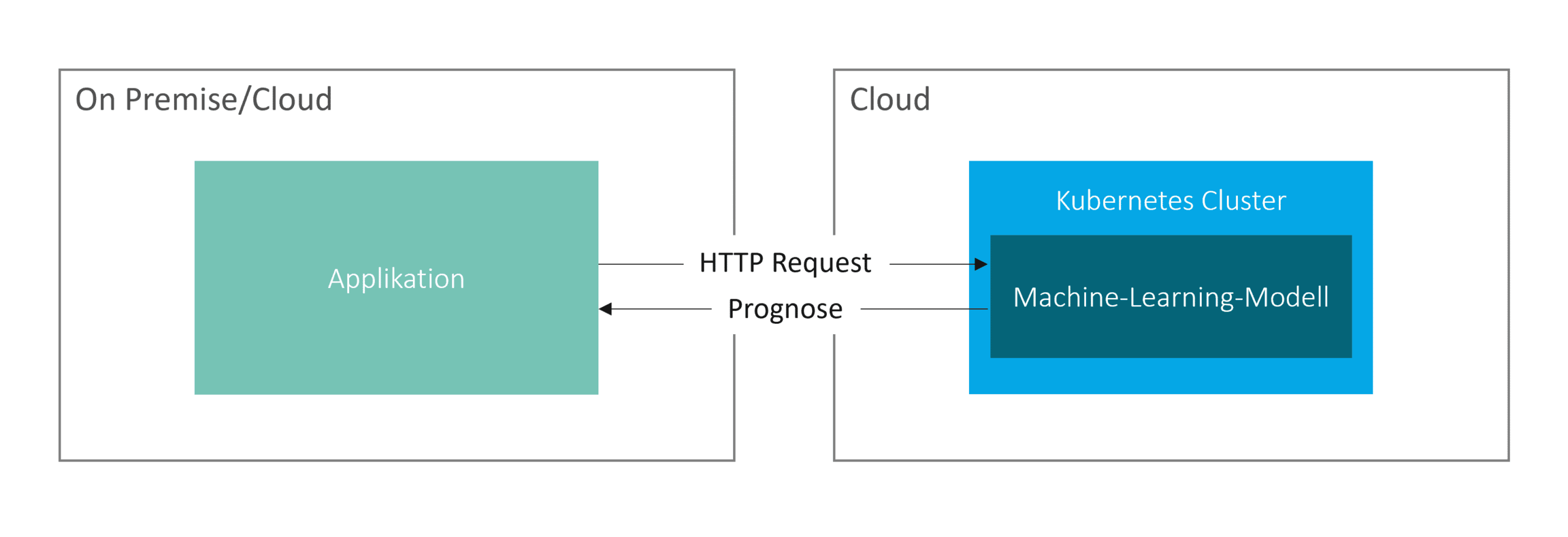
In a classic deployment scenario, a machine learning model is deployed as a web service, for instance, within a Kubernetes cluster. Predictions are then requested from a target system via HTTP requests, which supply the necessary input arguments.
Scenarios are also implementable where the machine learning model retrieves the latest forecast-relevant input data and transmits forecasts to the target system (pull mechanism).
Figure 3: Architecture | isr.de
Figure 3: Architecture | isr.de
Summary
The MLOps approach represents the best practice for operationalizing machine learning models. This approach meets the requirements for continuous integration, continuous training, and continuous deployment. A central step in this process is the transition of the model training code into a machine learning pipeline.
Subsequently, MLOps pipelines must be defined to automate the execution and publication of the machine learning pipeline, as well as to automate the model's production deployment. Further operationalization steps include establishing monitoring and an authentication method for the production machine learning model. The provision of results to the end-user or the embedding of results into decision-making processes constitutes the final phase of operationalization.
Solutions for operationalizing machine learning models are offered by many major software providers, including Microsoft, Google, AWS, and SAP.
Author: Alexandros Xiagakis
CONTACT
Bernd Themann Managing Consultant SAP Information Management
Since 1993, we have been operating as IT consultants for Data Analytics and Document Logistics, focusing on data management and process automation. We provide comprehensive support, from strategic IT consulting to specific implementations and solutions, all the way to IT operations, within the framework of holistic Enterprise Information Management (EIM). ISR is part of the CENIT EIM Group.