Nachdem ein Modell trainiert wurde, dass eine hohe Modellgüte aufweist, stellt sich im nächsten Schritt die Frage, wie sich das trainierte Machine-Learning-Modell produktiv nutzen lässt.
Herausforderungen stellen hierbei unter anderem die Automatisierung des Modelltrainings, der Produktivsetzung des Modells sowie der Überwachung dar.
In diesem Blogartikel wird erläutert, wie diese Herausforderungen gelöst werden können und welche Schritte für die Operationalisierung einer Machine-Learning-Lösung durchzuführen sind. Dabei wird ein Beispiel für eine Architektur zur Operationalisierung von Machine-Learning-Modellen dargestellt, welche auf dem MLOps Ansatz basiert.
Zusätzlich wird darauf eingegangen, wie die Ergebnisse schließlich für Endanwender nutzbar gemacht werden können.
Schritte zur Operationalisierung von Machine-Learning-Modellen
Der Beginn eines Data Science Projekts stellt eine experimentelle Phase dar. In dieser Phase liegt der Fokus darauf mittels explorativer Datenanalyse Erkenntnisse bzw. Zusammenhänge aus den Daten zu gewinnen und anschließend ein Modell zu trainieren, dass dem definierten Geschäftsziel dient.
Klassischer Weise findet die explorative Datenanalyse sowie die anfängliche Datenverarbeitung und Modellierung in Jupyter Notebooks statt. Neben Code enthalten diese Markdowns, welche textuelle Bereiche sind und zur Dokumentation der Erkenntnisse genutzt werden.
Für die Operationalisierung eines Machine-Learning-Modells ist dieser anfängliche manuelle Workflow der Modellentwicklung zu automatisieren. Zur Automatisierung dieses Prozesses bzw. zur kontinuierlichen Modellentwicklung ist es erforderlich, den Code in eine Machine-Learning-Pipeline zu überführen. Eine Machine-Learning-Pipeline ist eine Sequenz von Schritten. Die einzelnen Schritte führen jeweils einen Task, wie z.B. Datenversorgung, Datenbereinigung oder Modelltraining, aus.
In der unten stehenden Abbildung ist beispielhaft eine Machine-Learning-Pipeline zur Modellentwicklung dargestellt, welche nachfolgend nochmal aufgefasst und detailliert beschrieben wird:

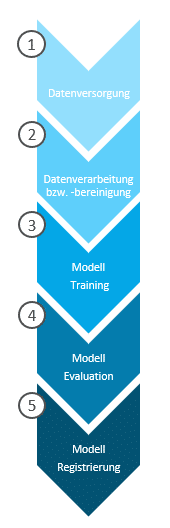
1. Datenversorgung
Der erste Schritt ist die Einrichtung von Schnittstellen zu den Quellsystemen, in denen die Daten zum Trainieren und Testen eines Machine-Learning-Modells vorgehalten werden. Es gibt zwei Möglichkeiten die Daten für die Modellierung zur Verfügung zu stellen. Die erste Variante ist ein virtueller Livezugriff auf die Daten eines Quellsystems.
Dabei verbleiben die Daten im Quellsystem und werden nicht physisch in die Machine-Learning-Umgebung übertragen. Die zweite Variante ist der Import der Daten aus dem Quellsystem in die Machine-Learning-Umgebung. Der Vorteil dieser Variante ist die Möglichkeit einer Datenversionierung.
2. Datenverarbeitung bzw. -bereinigung
- Entfernen von Duplikaten bzw. fehlerhaften Daten
- Entfernen bzw. Füllen von fehlenden Daten durch statistische Werte (z.B. Durchschnitt)
- Übertragen von Daten in ein anderes Format
- Generieren von neuen Variablen
- Aggregation von Daten
- Separation von Daten
3. Modell Training
Der dritte Schritt enthält den Code zum Trainieren des Modells. Nach der Unterteilung der Daten in Trainings- und Testdatensatz erfolgt die Selektion der Variablen und des Machine-Learning-Algorithmus. Auf Basis der Trainingsdaten, der Variablenselektion und des ausgewählten Machine-Learning-Algorithmus wird dann ein Machine-Learning-Modell trainiert.
Für manche Algorithmen sind zuvor noch Hyperparameter, welche Parameter fürs Modelltraining sind, zu definieren. Dafür wird in der Regel per Algorithmus nach den optimalen Hyperparametern gesucht.
4. Modell Evaluation
Anschließend wird im nächsten Schritt das trainierte Modell anhand der Testdaten evaluiert. Das heißt, dass für den Testdatensatz mittels des Modells Prognosen ermittelt werden und diese mit den tatsächlichen Werten verglichen werden, um die Prognosegüte des trainierten Modells zu beurteilen.
5. Modell Registrierung
Im letzten Schritt der Machine-Learning-Pipeline wird das Modell in einer Modell Registry gespeichert. Dabei findet auch eine Versionierung des Modells statt.
Machine-Learning-Ops-Ansatz
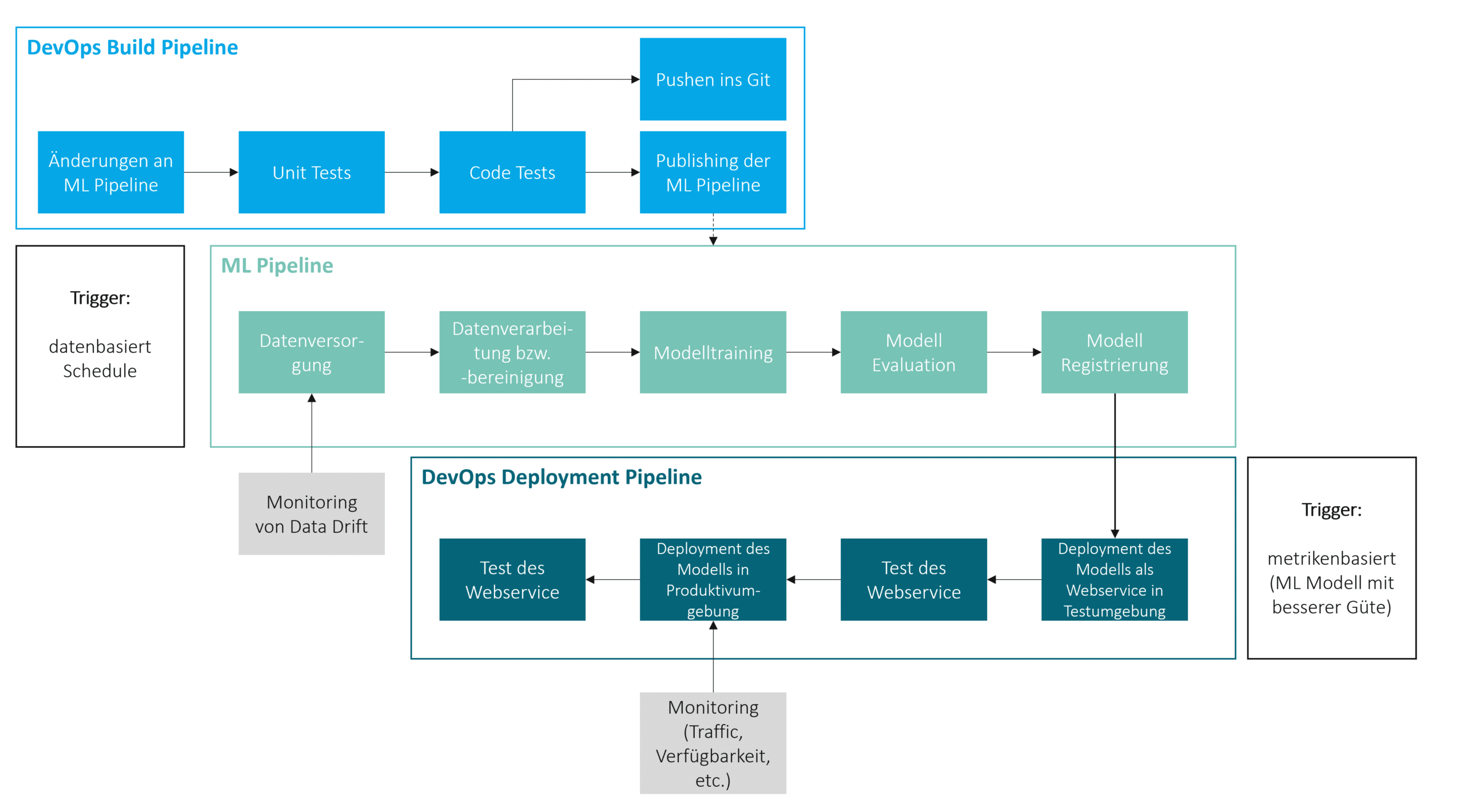
Die automatisierte Ausführung der Machine-Learning-Pipeline kann datenbasiert durch das Vorliegen neuer bzw. veränderter Daten im Quellsystem oder zeitbasiert durch ein Scheduling erfolgen. Neben der Ausführung von Machine-Learning-Pipelines sind die Automatisierung der Veröffentlichung von Machine-Learning-Pipelines nach Anpassungen sowie die Automatisierung der Produktivsetzung und der Überwachung von Machine-Learning-Lösungen weitere Themen bei der Operationalisierung. In diesem Kontext hat sich der MLOps Ansatz etabliert.
Machine-Learning-Ops (MLOps) ist die Anwendung des DevOpsWas ist DevOps?Der Begriff DevOps setzt sich aus den Wörtern… Mehr Konzepts aus der Softwareentwicklung auf Machine Learning. Im Rahmen des MLOps werden sogenannte MLOps Pipelines zur Automatisierung der zuvor beschriebenen Tasks definiert. Zum Beispiel kann eine MLOps Pipeline für das automatisierte, kontinuierliche Veröffentlichen der Machine-Learning-Pipeline erstellt werden. Diese MLOps Pipeline wird durch Veränderungen an der Machine-Learning-Pipeline getriggert und führt als erstes zu automatisierten Tests, wie z.B. Unit Tests und Code Quality Tests. Sind die Tests erfolgreich bzw. die Änderungen fehlerfrei, so wird der Code der Machine-Learning-Pipeline automatisiert ins Git gepusht und die neueste Version der Trainingspipeline in der Machine-Learning-Umgebung veröffentlicht. Diese neue Version kann dann für die Modellentwicklung genutzt werden.
Des Weiteren kann eine MLOps Pipeline fürs automatisierte, kontinuierliche Deployment eines Machine-Learning-Modells erstellt werden. Diese Pipeline kann beispielsweise durch das Vorliegen eines neuen Modells mit einer besseren Prognosegüte ausgelöst werden. Die Prognosegüte wird anhand einer zuvor definierten Metrik, wie z.B. dem mittleren absoluten Prognosefehler, ermittelt. In einer 2-Systemlandschaft wird das Modell zuerst in der Testumgebung, i.d.R., als Webservice deployed und getestet. Sind die Tests erfolgreich, so wird das Modell in der Produktivumgebung deployed und auch dort getestet. Nach dem erfolgreichen Testen steht schließlich ein produktives Machine-Learning-Modell, welches Prognosen liefert, zur Verfügung.
Authentifizierung und Monitoring
Für das produktivgesetzte Machine-Learning-Modell sollte eine Authentifizierungsmethode eingerichtet werden, um einen unerlaubten Zugriff zu verhindern. Wurde das Modell als Webservice deployed, dann wird üblicherweise eine Token-basierte oder eine Schlüssel-basierte Authentifizierung verwendet.
Damit gewährleistet ist, dass Ausfälle des produktiven Machine-Learning-Modells vermieden werden bzw. Ausfallzeiten gering gehalten werden, sollte man einen Service zur Überwachung der Verfügbarkeit und der Auslastung des produktiven Machine-Learning-Modells nutzen. Außerdem kann es sinnvoll sein, weitere Teile der Architektur zu monitoren. Beispielsweise kann ein Data Drift, d.h. eine signifikante Veränderung der Quelldaten, dazu führen, dass die Prognosegüte eines Machine-Learning-Modells sich für neue Daten dramatisch verschlechtert. Daher bietet es sich in vielen Fällen an, einen Service zu nutzen, der die Daten aus den Quellsystemen auf Data Drifts überprüft.
Im folgenden ist ein Beispiel für eine MLOps Architektur zur Operationalisierung von Machine-Learning-Modellen dargestellt.
Nutzung der Ergebnisse
In der Regel führen Prognosen aufgrund der Compliance im Unternehmen nicht zu automatisierten Entscheidungen, sondern unterstützen die Mitarbeiter eines Unternehmens im Entscheidungsprozess. Daher sind die generierten Prognosen eines Machine-Learning-Modells üblicherweise den Mitarbeitern bereitzustellen.
Die Ergebnisse bzw. Prognosen können den Endanwendern aus den Fachbereichen entweder durch das Zurückspielen der Prognosen in ein bestehendes System oder durch die Erstellung einer neuen Applikation zur Verfügung gestellt werden.
Je nach Anforderung werden die Prognosen in Realtime oder im Batch zu bestimmten Zeitpunkten generiert und an das Zielsystem übermittelt. Realtime bedeutet, dass direkt neue Prognosen getriggert werden, wenn sich Prognose relevante Inputdaten verändern bzw. neue Prognose relevante Daten im Quellsystem zur Verfügung stehen.
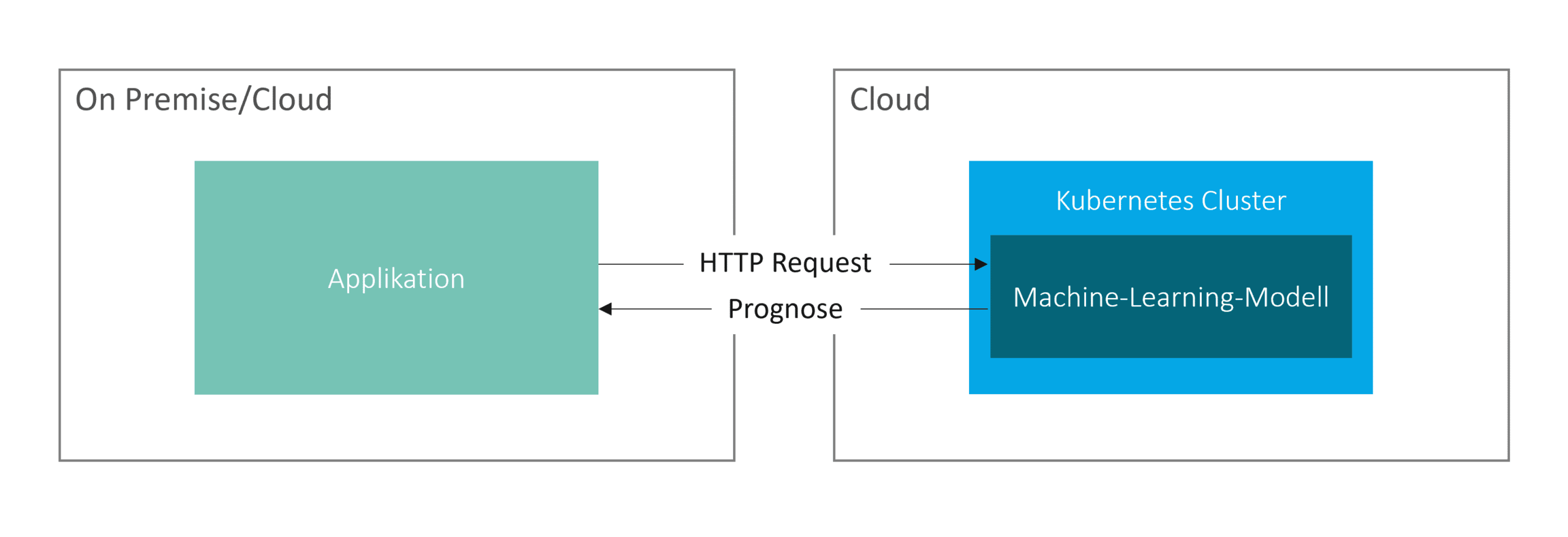
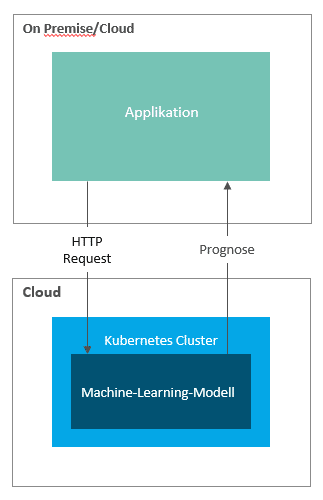
Im klassischen Deployment Szenario wird ein Machine-Learning-Modell als Webservice, z.B. in einem Kubernetes Cluster, deployed. Mittels HTTP Requests, welche die Input Argumente mitliefern, werden dann Prognosen von einem Zielsystem angefordert.
Es sind auch Szenarien umsetzbar, in denen sich das Machine-Learning-Modell die neuesten Prognose relevanten Inputdaten zieht und Prognosen an das Zielsystem übermittelt (Pull Mechanismus).
Zusammenfassung
Best Practice zur Operationalisierung von Machine-Learning-Modellen ist der MLOps Ansatz. Dieser Ansatz erfüllt die Anforderungen an eine kontinuierliche Integration sowie ein kontinuierliches Training und Deployment. Ein zentraler Schritt ist dabei die Überführung des Codes zum Trainieren eines Modells in eine Machine-Learning-Pipeline.
Anschließend sind MLOps Pipelines zur Automatisierung der Ausführung und Veröffentlichung der Machine-Learning-Pipeline sowie zur Automatisierung der Produktivsetzung des Modells zu definieren. Weitere Schritte der Operationalisierung sind die Einrichtung eines Monitorings und einer Authentifizierungsmethode für das produktive Machine-Learning-Modell. Die Bereitstellung der Ergebnisse für den Endanwender bzw. die Einbettung der Ergebnisse in Entscheidungsprozesse stellt die letzte Phase der Operationalisierung dar.
Lösungen zur Operationalisierung von Machine-Learning-Modellen bieten viele große Softwareanbieter, u.a. Microsoft, Google, AWS und SAP, an.
Autor: Alexandros Xiagakis

KONTAKT
Bernd Themann
Managing Consultant
SAP Information Management


