The data lakehouse is an approach with the potential to significantly simplify data management for Business Intelligence and Analytics.
In addition to the traditional Data Warehouse, Data Lakes have gained significant importance as central storage locations. The integration of both approaches is therefore a crucial question for the further development of a BI and data strategy. Behind the portmanteau of Data Warehouse and Data Lake lies a data management approach that promises to unify the functionalities of both systems within a single technical concept:
- The storage of structured, semi-structured, and unstructured raw data within the open, scalable architecture of the Data Lake.
- The functionalities for data structuring and processing inherent in the Data Warehouse.
In this blog article, we will explain this approach and take a closer look at the architecture and benefits of a Data Lakehouse. For building a Lakehouse, Databricks is currently the most prominent provider, with whom SAP has entered into a strategic partnership, likely for this very reason.
SAP offers current Data Warehouse solutions with the SAP HANA platform and applications such as SAP Datasphere and SAP BW. The investment focus is on Datasphere, SAP's strategic cloud data warehouse solution, which is designed to meet the modern requirements of business departments for data-driven self-service.
1. The Data Lakehouse Concept: Definition and Fundamentals
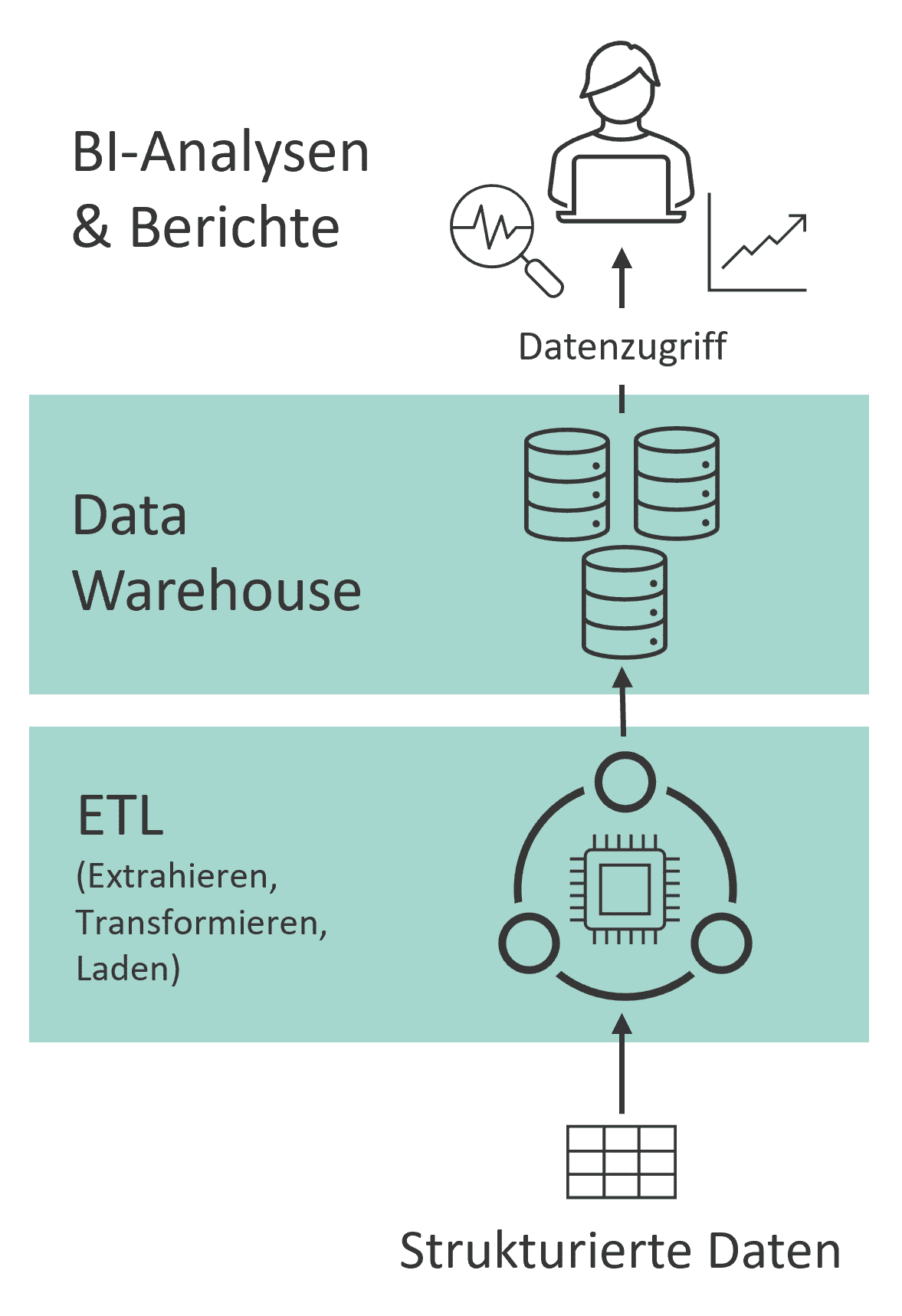
The Traditional Data Warehouse
The traditional Data Warehouse, with its powerful database, features integrated storage and computing resources, ensuring consistently high performance for data transformation and querying. Furthermore, it offers high data quality and rich semantic descriptions of business-relevant data. However, it also necessitates extensive data preparation and exhibits less flexibility in accommodating semi-structured and unstructured data, such as social media or sensor data (see Fig. 1). The continuous availability of powerful computing resources can also lead to high costs, which could be avoided during periods with infrequent write and read operations.
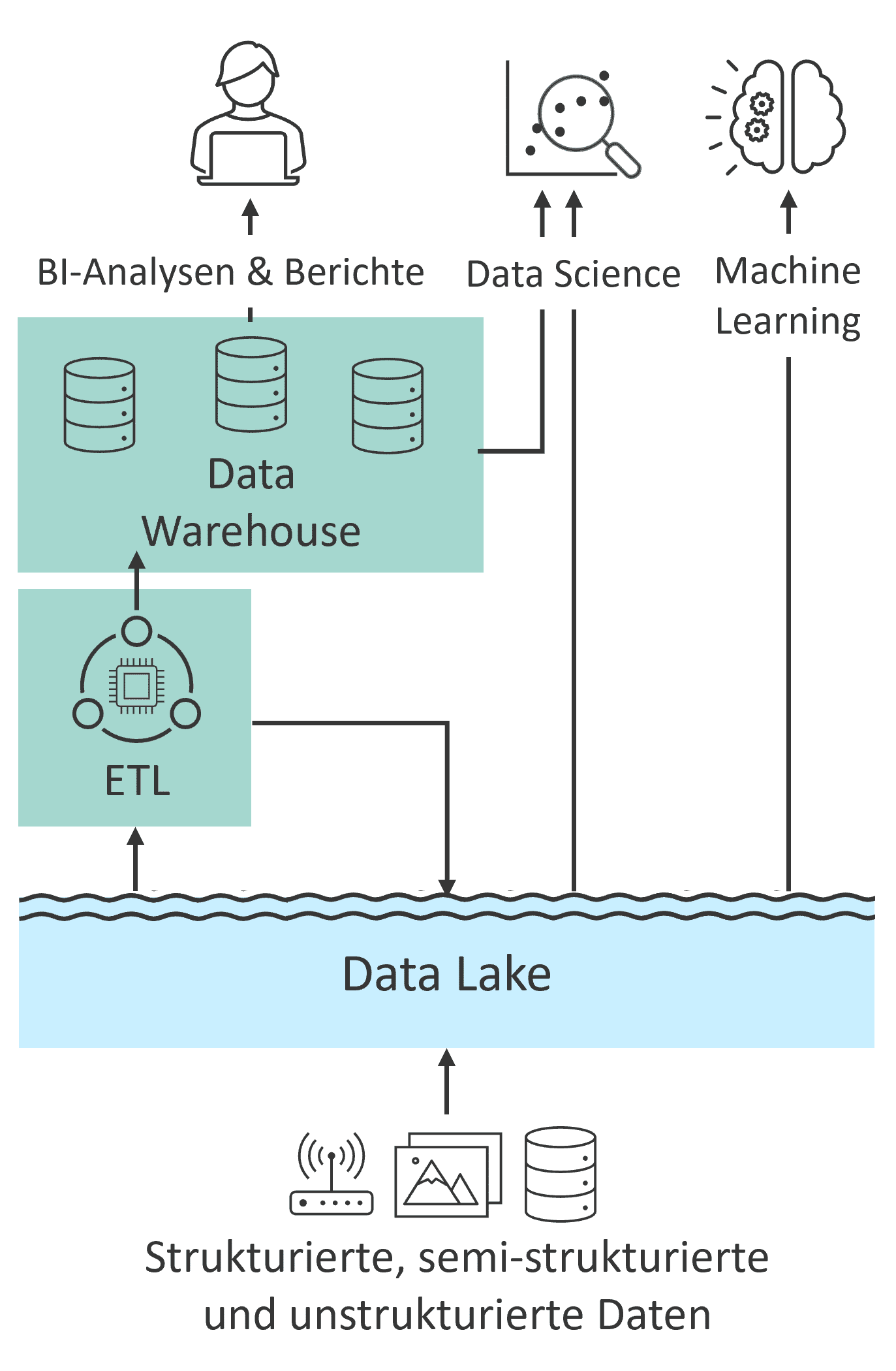
Data Lake
A Data Lake is designed for the centralized storage of large volumes of data, but without providing computing power itself. For write or read operations, services are required to provide the necessary computing resources. Data Lakes form the foundation for use cases such as machine learning and predictive analytics, which are increasingly vital for data-driven business decisions. Consequently, Data Lakes and Data Warehouses have been used in combination in recent years (see Fig. 2).
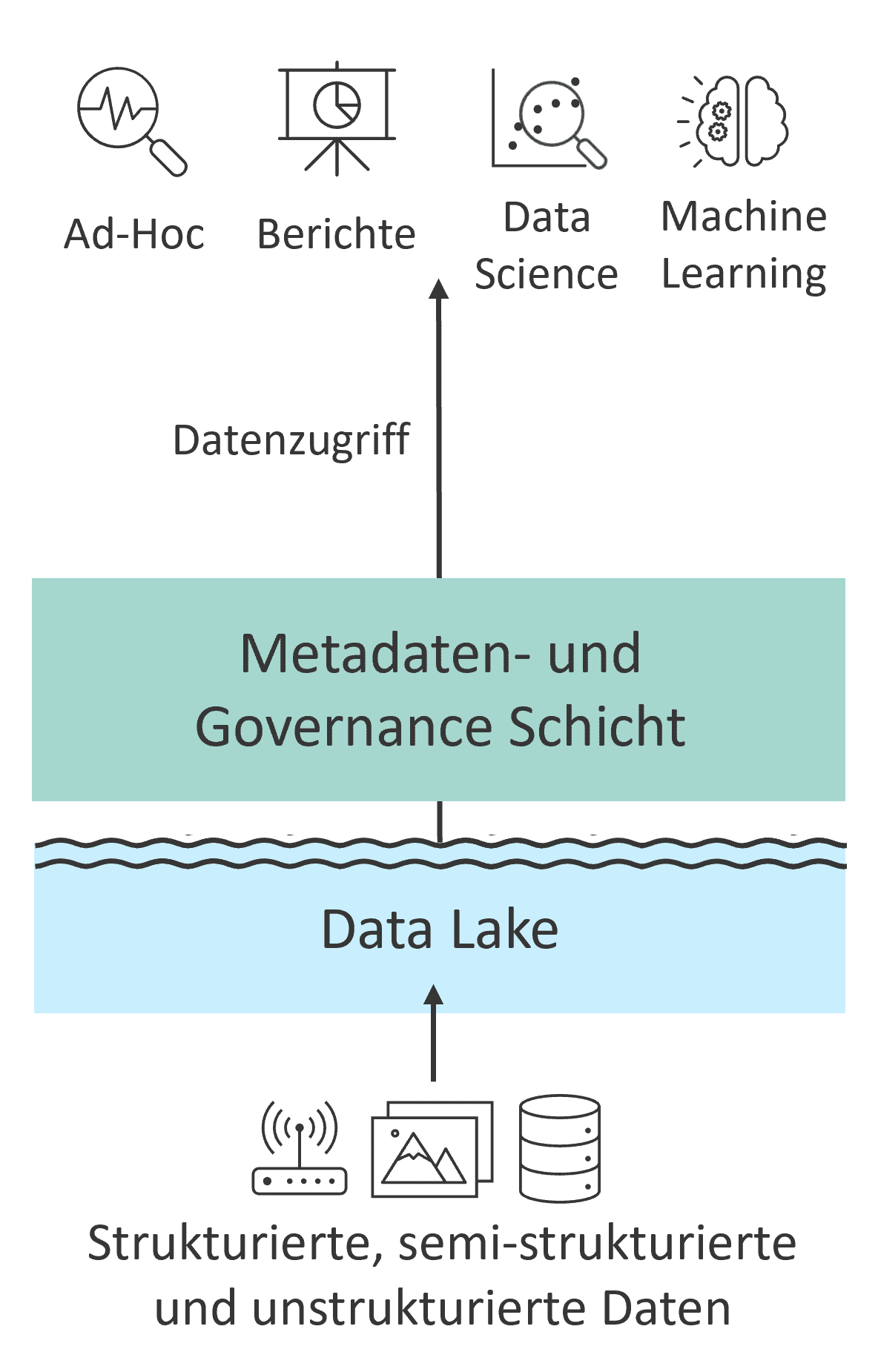
The Data Lakehouse Concept
The Data Lakehouse concept transforms this two-tiered connection into a unified approach, thereby combining the best aspects of both worlds (see Fig. 3). It offers the flexibility of a Data Lake for data ingestion and storage, alongside the structured organization and quality of a Data Warehouse. Central to this is the separation of data storage and computing power (storage and computing resources), ensuring that computing resources are only utilized when needed. This separation enables cost-effective storage of large data volumes while simultaneously facilitating powerful analytics. Through these characteristics, the Data Lakehouse aims to simplify data-driven decision-making processes, enhance flexibility, and reduce costs. Consequently, this concept has gained considerable popularity in practice over recent years.
Whitepapers
The Data Lakehouse in Databricks and SAP Datasphere – An Application Example
2. How the Data Lakehouse Works
2.1 Data Consistency and Quality with Open Table Formats
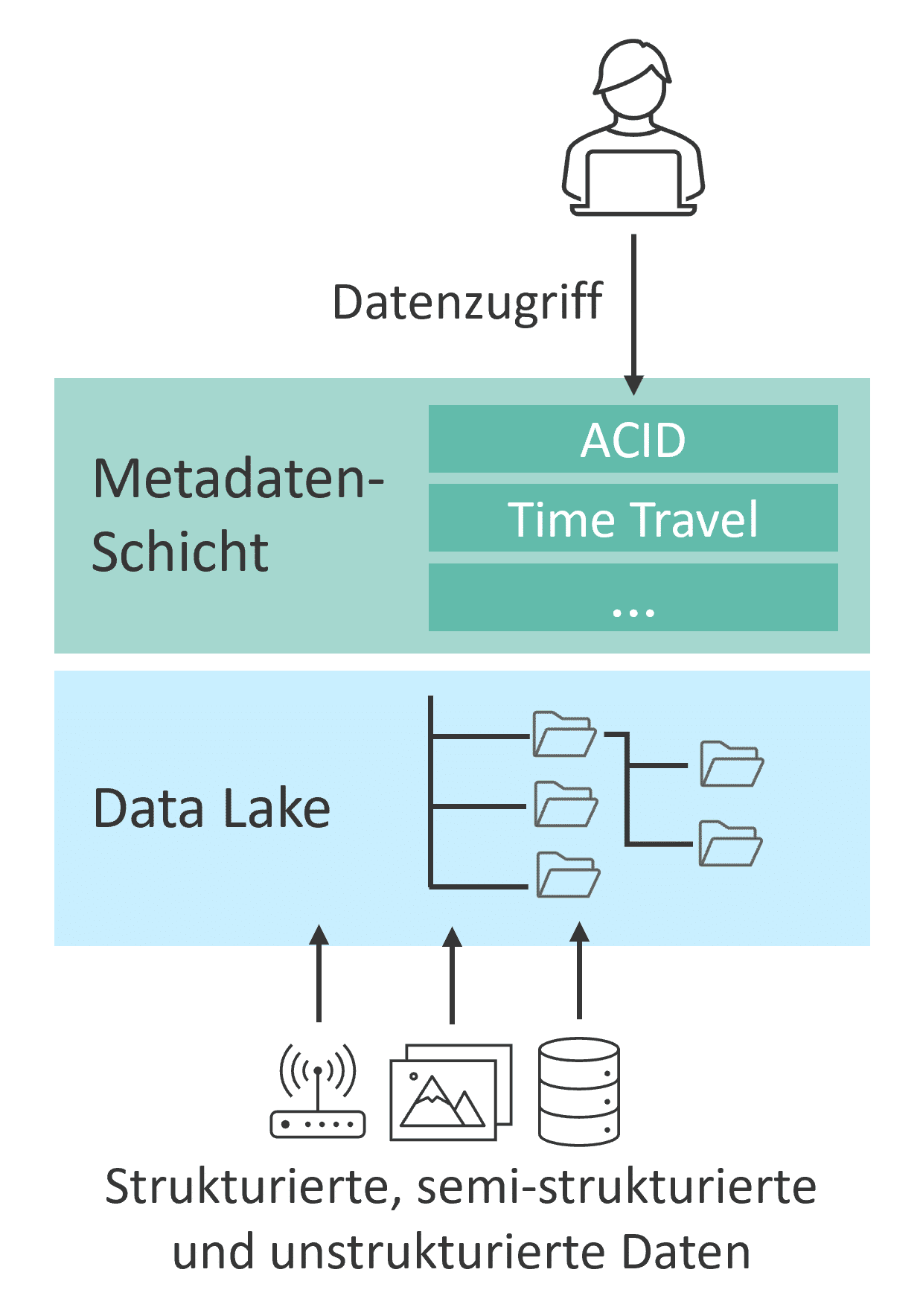
The Data Lakehouse is based on a virtual layer that accesses files within a Data Lake (see Fig. 4). These files are stored in standardized, platform-independent formats optimized for column-based storage of large data volumes. These open and standardized formats enable flexible data management, as they are not tied to a specific technology.
Challenges of Standard Formats:
However, standardized file formats have drawbacks such as inefficient write operations and issues with concurrent transactions, which can lead to data inconsistencies. To address these challenges, files are enriched by a virtual metadata layer, known as the Open Table Format. This metadata layer forms the technical foundation of the Lakehouse approach, offering functionalities traditionally available only in classic databases, thereby resolving several challenges.
Benefits of the Open Table Format:
- ACID-Compliant Transactions (Atomicity, Consistency, Isolation, Durability): Open table formats ensure that read and write operations execute transactions atomically and in isolation, and that data remains consistent and durably available at all times. This enables multiple users to work simultaneously on the same tables or files. Consequently, open table formats guarantee data reliability and integrity.
- Versioning and Historization (“Time Travel”): Changes to tables can be traced back to a specific point in time, and previous versions can be restored. This enhances the traceability of changes and allows for the comparison of different versions. Since only metadata of the changes is recorded, earlier versions do not need to be physically stored.
- Schema Enforcement and Evolution: By default, it is ensured that the schema of new data conforms to the existing table schema to guarantee data consistency (“schema-on-write”). Furthermore, schema evolution allows for flexible adjustments to the table schema (e.g., adding new columns) without requiring a complete recreation of the table.
- Partition Evolution: Partitions are stored as separate files, which simplifies queries and modifications within specific partitions. New rows and columns can be added to the metadata without rewriting the partitions, thereby optimizing performance.
- Governance and Metadata Management: A transaction log written to the table's storage location enables optimized queries and transactions by providing metadata such as schema and partitions.
- Unified Batch and Streaming Processing: Open table formats enable the processing of real-time data streams and historical data in micro-batches. This reduces the effort required for managing heterogeneous data pipelines and facilitates the provision of information for informed real-time decision-making.
- Integration of Data Science and Machine Learning: Thanks to open and standardized access, machine learning tools can quickly access existing data. Furthermore, the data is already stored in a format readable by common machine learning libraries.
Performance Optimization and Open-Source Solutions
To ensure optimal performance, much of the metadata is cached in cloud storage, which reduces latency for queries and transactions. Well-known open table formats such as Delta Lake, Iceberg, and Hudi are open-source and can be utilized in data lakes and compute services provided by hyperscalers like Microsoft Azure, AWS, or Google Cloud Platform. Despite their differing implementations, these formats offer similar performance characteristics.
These technical foundations and functionalities make open table formats a crucial component of the Data Lakehouse concept, which unifies the advantages of data lakes and data warehouses, thereby enabling efficient and consistent data management.
2.2 Data on the Podium: The Medallion Structure
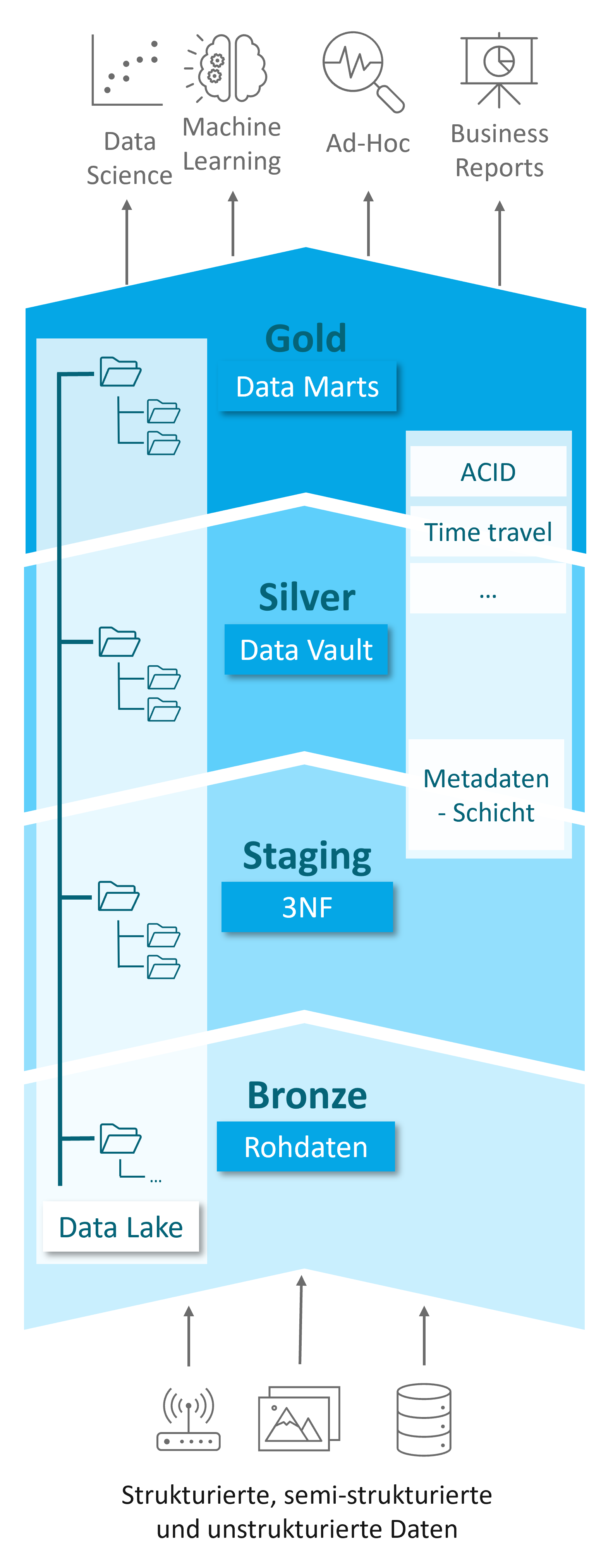
The Data Lakehouse requires a structured architecture to ensure the necessary governance and to flexibly respond to the challenges of constantly evolving data landscapes. For this purpose, a hierarchical data structure is introduced within the Data Lakehouse, which addresses both the requirements of data scientists for data analysis and the needs of data warehouse experts for reporting and BI applications. This hierarchy is referred to as the Medallion Structure (see Fig. 5) and was originally proposed by Databricks. It divides the Lakehouse into three layers, representing different data states: raw, refined, and aggregated. Data progresses through these layers from the lowest to the highest, with each layer having its own modeling conventions and loading rules.
This type of processing is not a novel concept; rather, it implements the logic of data transformations and ETL pipelines from classical data warehouse approaches within the Lakehouse, and will be familiar to many data warehouse experts.
The Layers of the Medallion Structure:
- Bronze Layer:
- Function: Storage location for raw data from various sources such as ERP and CRM systems, IoT devices, and other data sources.
- Characteristics: Data is stored in its original form and without transformation. Cost-effective storage in the Data Lake enables compliance with stringent documentation requirements.
- Staging Layer (optional):
- Function: Intermediate stage between the Bronze and Silver Layers.
- Characteristics: Unification and conversion of raw data into the open table format, collection of additional metadata, and correction of obvious errors. This facilitates the transformation into the Silver Layer.
- Silver Layer:
- Function: Central persistence layer for transformed data.
- Characteristics: Data is transformed according to strict and, where applicable, business rules, and stored in a harmonized raw layer (write-optimized). The modular structure of Data Vault modeling ensures flexibility and scalability.
- Gold Layer:
- Function: Query-optimized data preparation for analyses and reports.
- Characteristics: Data is denormalized and presented in dimensions and facts, similar to traditional Data Warehouses, to facilitate the creation of analyses and reports.
Advantages of the Medallion Architecture
The Medallion Architecture provides the Data Lakehouse with a structure that resembles modern Data Warehouses and addresses the diverse requirements of Data Engineers, Data Scientists, Data Governance specialists, and business users. Thanks to technical innovations such as the decoupling of compute and storage resources and the use of open table formats, the challenge lies less in building data pipelines and business logic, but rather in how these innovations can be integrated into existing data strategies and optimally leveraged within the enterprise.
3. Conclusion
The Data Lakehouse combines the strengths of Data Lakes and Data Warehouses by enabling flexible, cost-efficient, and high-performance data processing. The separation of data storage and compute power can contribute to more efficient utilization of cloud resources and cost reductions.
Open table formats ensure data consistency and quality through ACID-compliant transactions, versioning, schema enforcement, and support for batch and streaming processing. The Medallion Architecture (Bronze, Silver, and Gold Layers) provides clear data organization that meets the requirements of both Data Scientists and Data Warehouse experts. Concurrently, the implementation of a Data Lakehouse approach in enterprises requires meticulous planning to meet data consistency, accessibility, and governance requirements and to capitalize on the approach's opportunities.
Whitepaper
The Data Lakehouse

Authors: Damian Garrell & Martin Peitz
Your Point of Contact

Christopher Kampmann
Head of Business Unit
Data & Analytics
christopher.kampmann@isr.de
+49 (0) 151 422 05 448