Historisierung von Daten mit der Fähigkeit, den historischen Stand zu einem beliebigen Zeitpunkt auch nachträglich jederzeit wieder herstellen zu können, ist eine Kernanforderung an Data Warehouse Systeme.
Im Fall von SAP-Quellsystemen werden häufig durch den SAP Business Content bereits Veränderungssätze (“Delta”) an das Business Warehouse geliefert. Non-SAP Quellsysteme stellen ein Business Warehouse jedoch häufig vor die Herausforderung, dass nur ein aktueller Zustand, nicht jedoch Delta-Sätze mit before/after Images oder Zeitstempeln (“Changed On” Datum) geliefert werden können.
Inhaltsverzeichnis
2. Alternative 2: Inkrementelle Historierung einer Full-Datenquelle
2.1 Ablage der Veränderungshistorie in einem ADSO
2.2 Erstellung eines “History” ADSO mit den Veränderungen
2.3 Reporting auf inkrementeller Historie via Calculation View
2.4 Rank-Funktion
2.6 Vergleich Rank und Aggregation-Funktion
3. Fazit
Für diese Fälle soll hier aufgezeigt werden, welche Möglichkeiten es für ein Data Warehouse hinsichtlich der Historisierung gibt, und wie diese in einer modernen (BW/4HANA) Architektur sowohl mit BW- als auch HANA-Mitteln umgesetzt werden kann.
Alternative 1: Snapshots

Soll eine nicht deltafähige Datenquelle historisiert werden, um den Datenstand zu einem gewählten Stichtag reporten zu können, kann ein regelmäßiger Full-Load mit zusätzlichem Schlüsselfeld (z.B. Ladedatum) die Lösung sein. Bei einer täglichen Historisierung führt das jedoch zu einer enormen Vervielfachung des Datenvolumens, da täglich ein kompletter Snapshot erstellt werden müsste.
Dennoch ist bspw. für ein Monatsreporting dieses Vorgehen durchaus gängig und sinnvoll nutzbar. Dadurch, dass jeweils komplette “Datenscheiben” zu einem Stichtag festgeschrieben werden, ist auch ein sehr simples und sehr performantes Reporting möglich, da nur auf die entsprechende Datenscheibe gefiltert werden muss.
Änderungen, die eine kleinere Granularität als das Erzeugungsintervall der Snapshots aufweisen, sind jedoch nicht nachvollziehbar, oder führen zum eingangs erwähnten überproportionalen Aufblähens des redundant persistent gehaltenen Datenbestands im Data Mart. Eine Alternative zur Festschreibung nur der echten Änderungen ist daher wünschenswert.
Alternative 2: Inkrementelle Historierung einer Full-Datenquelle
Ablage der Veränderungshistorie in einem aDSO
Ändern sich täglich nur wenige Sätze, kann eine inkrementelle Historisierung die Alternative sein. Dabei werden nur geänderte, neue und gelöschte Sätze in den Ziel-InfoProvider mit dem neuen Ladedatum fortgeschrieben:
Inkrementelles Backup (nur Änderungen)
| Datum (Key 1) | Key 2 | Menge | Löschkennzeichen | |
|---|---|---|---|---|
| 01.01.2020 | A | 10 | ||
| 01.01.2020 | B | 15 | ||
| 02.01.2020 | A | 20 | Änderung Eintrag A | |
| 03.01.2020 | C | 5 | Neuer Eintrag C | |
| 04.01.2020 | B | 0 | X | Löschen Eintrag B |
Vollständiges Backup
| Datum (Key 1) | Key 2 | Menge | |
|---|---|---|---|
| 01.01.2020 | A | 10 | |
| 01.01.2020 | B | 15 | |
| 02.01.2020 | A | 20 | Änderung Eintrag A |
| 02.01.2020 | B | 15 | |
| 03.01.2020 | A | 20 | |
| 03.01.2020 | B | 15 | |
| 03.01.2020 | C | 5 | Neuer Eintrag C |
| 04.01.2020 | A | 20 | Löschen Eintrag B |
| 04.01.2020 | C | 5 |
Da in der inkrementellen Historisierung nur die geänderten, gelöschten oder neuen Sätze fortgeschrieben werden, reduziert sich der benötigte Speicherplatz deutlich. Ein Reporting ist weiterhin für jeden Stichtag möglich, indem der jeweils aktuelle Satz einer Schlüsselkombination herangezogen wird (siehe unten → Reporting).
Erstellung eines “History” aDSO mit den Veränderungen
Für die Erstellung eines solchen History aDSO gibt es verschiedene Varianten.
Liefert die DataSource unseres Quell-aDSO ein sauberes Delta können wir dies einfach in unser History aDSO weiter prozessieren. Kein Problem. Auch wenn aus der Quelle ein Full übertragen wird, liefert das Change Log aus dem Quell-aDSO ein korrektes Delta zu den erfolgten Änderungen. Mit SAP BW/4 HANA ist diese Funktion nochmals gestärkt worden durch die Identifikation von Löschungen (Einstellung Snapshot).
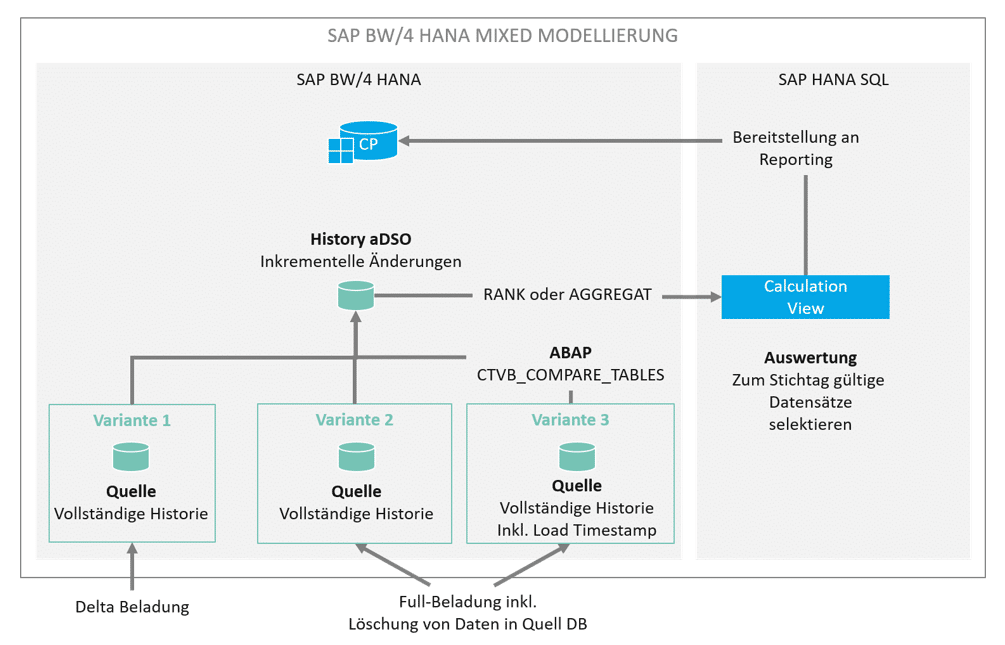
Unser Szenario arbeitet noch etwas anders. Während der Beladung des Quell-aDSO möchten wir ein Timestamp erzeugen je Datensatz, den wir laden. Dieser “Load-Timestamp” zeigt uns den Gültigkeitszeitpunkt des Datensatzes für das Datenmodell im SAP BW. Dies macht später im BW Betrieb Analysen einfacher. Durch die Generierung eines Load-Timestamp funktioniert die Generierung eines Deltas durch den Changelog nicht mehr. Während der Beladung unseres History aDSO die neuen, geänderten oder gelöschten Sätze aus dieser Quelle herauszufiltern ist mitunter schwierig. Neue und geänderte Sätze können manuell nur über komplizierte Tabellenvergleiche ermittelt werden. Abhilfe schafft der Standard-Funktionsbaustein (FuBa) CTVB_COMPARE_TABLES.
CALL FUNCTION ‘CTVB_COMPARE_TABLES’
EXPORTING
table_old = lt_old
table_new = lt_new
key_length = lv_key
* IF_SORTED =
IMPORTING
TABLE_DEL = lt_del
TABLE_ADD = lt_add
TABLE_MOD = lt_mod
* NO_CHANGES = .
Der FuBa vergleicht zwei typgleiche interne Tabellen und gibt neue, geänderte und gelöschte Sätze in drei entsprechenden internen Tabellen zurück:
- TABLE_DEL mit allen gelöschten Sätzen,
- TABLE_ADD mit allen neuen Sätzen, und
- TABLE_MOD mit allen geänderten Sätzen.
Die Schlüssellänge (key_length) der zu vergleichenden Tabelle wird in Byte angegeben.
Um den Funktionsbaustein nutzen zu können, sind die zu vergleichenden Daten aus Quelle (Full-Datenquelle) und Ziel (mit inkrementeller Historie) entsprechend aufzubereiten.
Dies ist insbesondere für die bestehende Historie notwendig: Während die Full-Datenquelle bereits alle zu vergleichenden Daten enthält, muss aus der Historie erst der zum Ladedatum gültige Stand ermittelt werden. Im obenstehenden Beispiel der inkrementellen Historie ist Schlüssel A mit Menge 20, welches am 02.01. geladen wurde, schließlich auch am 04.01. noch gültig, da keine spätere Änderung oder Löschung mehr folgt.
Der Datenstand am 04.01. sieht also aus wie folgt, Schlüssel B ist nicht mehr relevant, da mit Löschkennzeichen versehen:
Ältere Sätze (z.B. A vom 01.01.2020) werden nicht selektiert, da bereits ein neuerer Satz für A vorliegt. Die Selektion kann bspw. durch einen Loop über die (nach Ladedatum sortierte) Historie erfolgen, bei dem nur die Schlüsselkombinationen mit aktuellstem Ladedatum verarbeitet werden. Über den dann folgenden Funktionsbaustein-Aufruf werden alle Änderungen ermittelt. Die drei internen Tabellen können dann mit neuem Ladedatum der Historie hinzugefügt werden, wobei gelöschte Sätze noch mit einem Löschkennzeichen versehen werden.
Angenommen, der Full-Load am 5.01.2020 sieht aus wie folgt:
| Datum (Key 1) | Key 2 | Menge |
|---|---|---|
| 05.01.2020 | A | 10 |
| 05.01.2020 | D | 10 |
Im Vergleich zum Vortag hat sich also die Menge A geändert, Menge C wurde gelöscht. Verglichen wird der Full-Load mit der Historie vom 04.01.2020:
| Datum (Key 1) | Key 2 | Menge |
|---|---|---|
| 02.01.2020 | A | 20 |
| 03.01.2020 | C | 5 |
Dann haben die internen Tabellen, die der Funktionsbaustein zurückliefert, jeweils einen Eintrag und sehen aus wie folgt:
| Tabelle | Key | Menge |
|---|---|---|
| TABLE_MOD | A | 10 |
| TABLE_DEL | C | 5 |
| TABLE_ADD | D | 10 |
Alle drei Tabellen werden der Historie mit neuem Ladedatum hinzugefügt, die finale Historie sieht also aus wie folgt:
| Datum (Key 1) | Key 2 | Menge | Löschkennzeichen | |
|---|---|---|---|---|
| 01.01.2020 | A | 10 | ||
| 01.01.2020 | B | 15 | ||
| 02.01.2020 | A | 20 | ||
| 03.01.2020 | C | 5 | ||
| 04.01.2020 | B | 0 | X | |
| 05.01.2020 | A | 10 | Änderung Eintrag A | |
| 05.01.2020 | C | 0 | X | Löschen Eintrag C |
| 05.01.2020 | D | 10 | Neuer Eintrag D |
Vorteil dieser Herangehensweise ist, dass die Historie deutlich langsamer anwächst als es bei vollständigen Snapshots der Fall wäre. Auch ist es unabhängig vom Ladedatum. Die Historie kann zu beliebigen Intervallen (auch untertägig) laufen und weist dann stets den zum Ladedatum gültigen Stand auf.
Um die Daten sinnvoll reporten zu können (schließlich würde ein Filter auf das Ladedatum nur die an diesem Tag geladenen Änderungen, nicht aber die dann gültige Historie enthalten), gibt es via Calculation View gleich zwei Möglichkeiten, die im Folgenden vorgestellt werden.
Reporting auf inkrementeller Historie via Calculation View
Möchte man auf einer inkrementellen Historie reporten ist es nicht ausreichend auf das Ladedatum zu filtern. Darüber würden nur die am Ladedatum geänderten Sätze erfasst. Für ein vollständiges Reporting müssen alle Schlüsselkombinationen mit dem jeweils aktuellen Ladedatum gelesen werden.
Als Beispiel eine Historie mit Änderungen über 5 Tage:
Mit Stichtag 05.01.2020 müssen folgende Sätze gelesen werden:
| 05.01.2020 | A | 10 |
| 05.01.2020 | D | 10 |
Mit Stichtag 03.01. wären es dagegen folgende Sätze, also auch welche, die schon am 01. und 02.01. geladen wurden, da kein späterer Load mit gleichem Schlüssel erfolgte:
| 01.01.2020 | B | 15 |
| 02.01.2020 | A | 20 |
| 03.01.2020 | C | 5 |
Über einen Calculation View lässt sich dieses Verhalten sehr einfach umsetzen. Zwei Ansätze stehen zur Verfügung: Die RANK-Funktion und die AGGREGATION-Funktion.
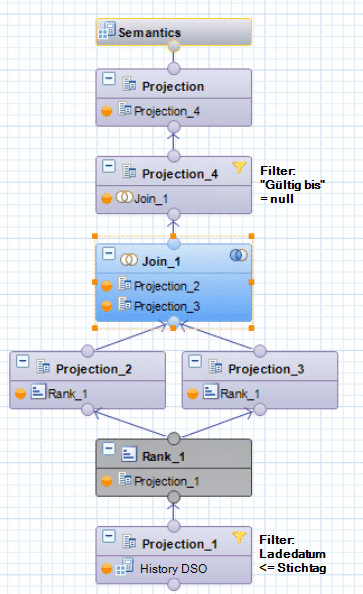
RANK-Funktionen
Der Grundgedanke beim Nutzen der Rank-Funktion liegt darin, die Quelldaten anhand ihrer Schlüssel absteigend nach ihrem Ladedatum zu sortieren und eine Rank-Column einzufügen: Der größte Rank einer Schlüsselkombination spiegelt den neuesten Load dieser Kombination wider, der kleinste Rank den ältesten Load.
Die so erzeugten Daten werden in zwei Projektionen geschrieben:
1. Unverändert inkl. Rank
2. Neue Calculated Column mit Spalte Rank – 1
Joint man die so erstellten Projektionen über Schlüssel und Rank, erhält jeder Satz ein zweites Ladedatum, nämlich das des nachfolgenden Loads. Das Ergebnis ist quasi ein Gültigkeitszeitraum der jeweiligen Schlüsselkombination. Da der jeweils aktuelle Satz einer Schlüsselkombination keinen Nachfolger hat, ist sein „gültig bis“-Feld leer bzw. null.
| Von (Key 1) Projection 2 | Bis (Key 2) Projection 3 | Key 3 | Menge | Löschkennzeichen |
|---|---|---|---|---|
| 01.01.2020 | 01.01.2020 | A | 10 | |
| 01.01.2020 | 03.01.2020 | B | 15 | |
| 02.01.2020 | 04.01.2020 | A | 20 | |
| 03.01.2020 | 04.01.2020 | C | 5 | |
| 04.01.2020 | leer | B | 0 | X |
| 05.01.2020 | leer | A | 10 | |
| 05.01.2020 | leer | C | 0 | X |
| 05.01.2020 | leer | D | 10 |
Durch Filterung auf diesen Nullwert in der neuen „gültig bis“-Spalte können alle zum Stichtag gültigen Daten abgefragt werden. Durch Filterung der Quelldaten auf Ladedatum <= Stichtag, welcher per Parameter etwa bis in eine BW Query durchgereicht werden kann, kann der Snapshot jedes beliebigen Stichtages ermittelt werden.
RANK Einstellung in der Projection
Vollständiger Calculation View
Aggregation-Funktion
Durch eine Aggregation über alle Schlüsselfelder einer inkrementellen Historie und die Nutzung der Engine Aggregation MAX auf dem Ladedatum, lassen sich die jeweils zu einem Stichtag gültigen Schlüsselkombinationen + Ladedatum ermitteln. Damit das für beliebige Stichtage funktioniert, müssen die Quelldaten zunächst gefiltert werden: Ladedatum <= Stichtag. Dieser Filter kann per Parameter bis in eine BW Query durchgereicht werden.
Da die Aggregation nur auf den Schlüsselfeldern stattfindet, müssen alle übrigen Felder im Anschluss wieder hinzugefügt werden über einen Join. Da die Aggregation den exakten Schlüssel liefert ist das kein Problem.
AGGREGATION: Ladedatum mit Enginge Aggregation MAX

Join der Aggregation mit komplettem History DSO:
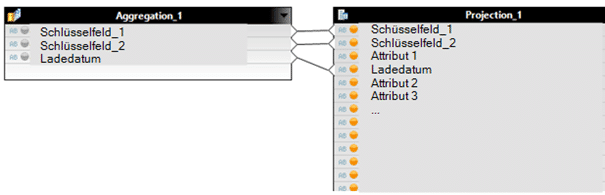
Vollständiger Calculation View:

Vergleich RANK und AGGREGATION-Funktion
Auch wenn die beiden Calculation Views das gleiche Ergebnis liefern, ist die Wahl zwischen RANK- oder AGGREGATION-Funktion eine Frage der Größe der Historie, der Häufigkeit des Ladens und der Reporting-Performance.
Beispielszenario: Eine Historie mit 6 Millionen Schlüsselkombinationen wächst innerhalb eines Jahres auf 60 Millionen Datensätze an. Da bei der RANK-Funktion die komplette Historie mit einem Rang versehen und mit sich selbst joint, muss der Calculation View also einen Join von zwei Tabellen mit 60 Millionen Einträgen verarbeiten, um die aktuelle Sicht der Daten zu erhalten.
Das ist bei der AGGREGATION-Funktion anders: Durch die Aggregation werden zunächst die aktuell gültigen Schlüssel ermittelt (die mit aktuellem Ladedatum), das sind lediglich 6 Millionen. Für das Reporting werden diese 6 Millionen Sätze dann mit der vollständigen Historie verjoint, also 6 und 60 Millionen. Dieser Join ist wesentlich schneller, als es bei zwei gleichgroßen Tabellen mit jeweils 60 Millionen Einträgen der Fall ist.
Mit wachsender Historie wird die Verwendung der RANK-Funktion also immer langsamer, da immer mehr Daten gejoint werden müssen. Die Aggregation-Funktion bleibt dagegen konstant, da zumindest eine der beiden Tabellen nicht groß wächst. Auch der allokierte Speicher ist bei der Aggregation deutlich kleiner.
Die folgenden Screenshots zeigen beispielhaft, wie schnell die Calculation Views ausgeführt werden, wenn die Historie nach einem Jahr von 6 auf 60 Millionen Sätze angewachsen ist. Einmal wurden dabei die aktuellen Daten abgerufen, einmal die ältesten (vor einem Jahr gültigen) Daten:
RANK mit aktuellen Daten (= Stichtag heute, Join von 60 und 60 Millionen Sätzen)
AGGREGATION mit aktuellen Daten (= Stichtag heute, Join von 60 und 60 Millionen Sätzen)
RANK mit einem Jahr alten Daten (= Stichtag vor einem Jahr, Join von 60 und 60 Millionen Sätzen)
AGGREGATION mit einem Jahr alten Daten (= Stichtag vor einem Jahr, Join von 60 und 60 Millionen Sätzen)
Fazit
Lange wurden Historien im SAP BW durch die Bildung von Snapshots gesichert. Diese bewährte Methode funktioniert auch weiterhin gut, jedoch steigt in Abhängigkeit von dem zu sichernden Datenmodell und der Häufigkeit der Sicherung die Datenmenge über den Zeitverlauf stark an. Mit SAP HANA basierten Systemen sollte man Datenredundanzen nach Möglichkeit vermeiden – allein schon aus Kostengründen. Mit mixed Modellierungsansätzen ergeben sich neue elegantere Möglichkeiten Historien zu sichern und diese performant abzufragen. Das Wachstum des Datenvolumens lässt sich so auf ein Minimum reduzieren. Unser Beispiel zeigt auch wie wichtig es für SAP BW Entwickler wird, beide Welten (SAP BW + HANA SQL) zu kennen. In der Kombination liegt die besondere Stärke hybrider Datenmodelle.

Christopher Kampmann
Head of Business Unit
Data & Analytics
christopher.kampmann@isr.de
+49 (0) 151 422 05 448


