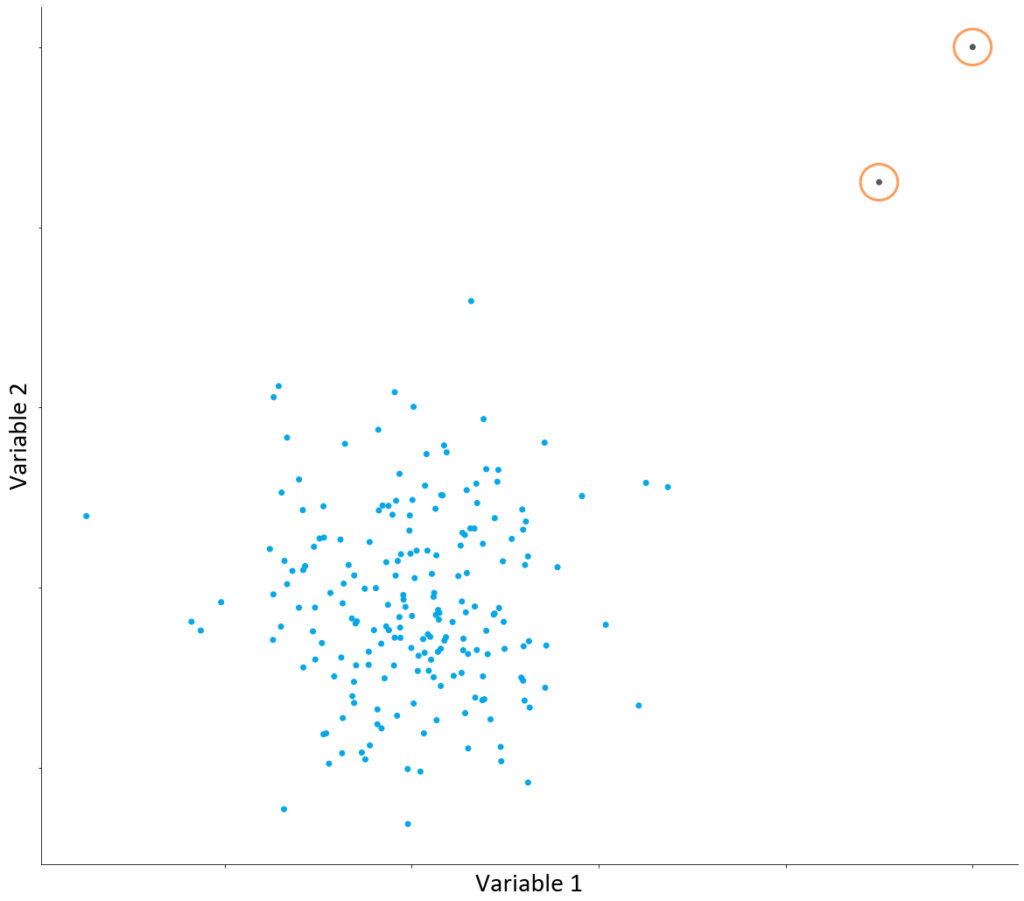
Punktuelle Anomalie
Ein Datensatz wird im Vergleich mit den restlichen Daten als anormal betrachtet.
Kontextuelle Anomalie
Ein Datensatz wird in einem spezifischen Kontext als anormal betrachtet.

Kollektive Anomalie
Mehrere Datensätze werden im Vergleich mit den restlichen Daten als anormal betrachtet.

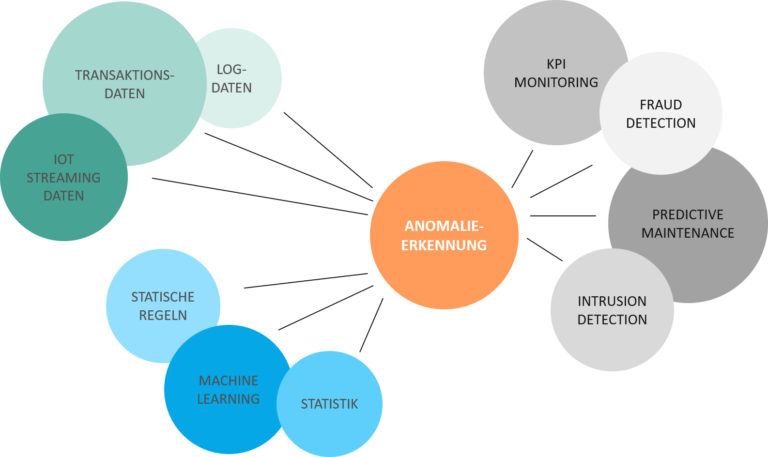
Die steigenden Datenmengen in Unternehmen sowie die Analyse dieser Daten in Echtzeit machen den Einsatz von Machine-Learning-Algorithmen zunehmend attraktiv.
Gerade im Bereich der Anomalie-Erkennung können diese Algorithmen sowohl Erkenntnisse zu interessanten Geschäftsvorfällen liefern als auch Sicherheitslücken für Getinge aufdecken.
Gerade im Bereich der Anomalie-Erkennung können diese Algorithmen sowohl Erkenntnisse zu interessanten Geschäftsvorfällen liefern als auch Sicherheitslücken für Getinge aufdecken.

Arnold Fritz
Senior Director IT Technologies | getinge



IBM Watson Studio