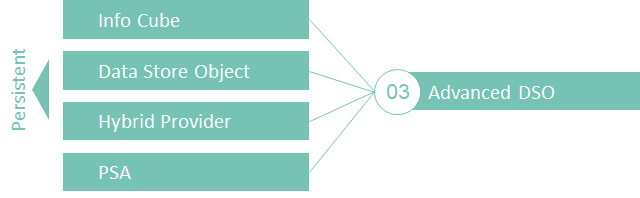
Mit BW/4 HANA hat SAP eine Konsolidierung der Info Provider Arten durchgeführt. Von zentraler Bedeutung ist das advanced Data Store Objekt (DSO), welches die Ablösung gleich mehrerer InfoProviderInfoProvider sind Objekte, auf denen ein Reporting (z.B. Queries) ausgeführt werden kann…. Mehr bedeutet.
In diesem Beitrag gehen wir im Detail auf die Eigenschaften des aDSO ein und erläutern, wie Sie den richtigen aDSO Typ finden.
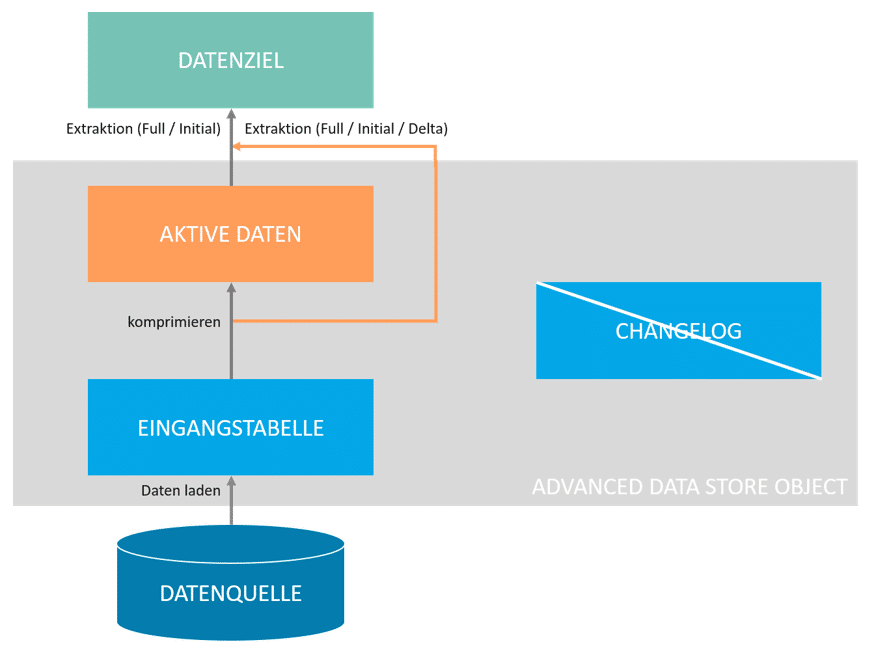
Abb.: advanced Data Store Objects | isr.de
Aufbau eines aDSO
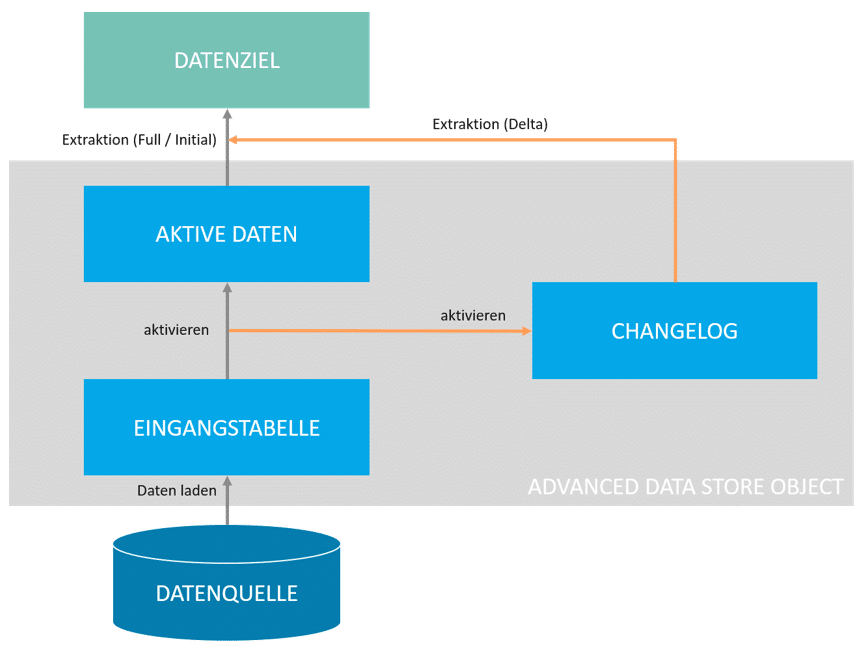
Ein aDSO besteht immer aus drei Tabellen, welche je nach Typ genutzt werden oder auch nicht. Allerdings werden auch nicht genutzte Tabellen im Hintergrund angelegt. Daher muss man bei der Entwicklung aufpassen.
In der Eingangstabelle eines advanced Data Store Objects befinden sich geladene Requests vor Aktivierung der Daten. Dies bedeutet es hat noch keine Prüfung der Schlüsselattribute, und noch keine SID-Generierung stattgefunden. Alle erfolgreich aktivierten Requests werden in die aktive Datentabelle geschrieben. Im Rahmen der Aktivierung erfolgt unter anderem die Überprüfung der semantischen Schlüssel. Darüber hinaus werden eindeutige Identifizierer (SID’s = SAP System Identifier) erzeugt sofern InfoObjects genutzt worden sind in der Modellierung. In der Changelog-Tabelle werden schließlich alle Änderungen vorgehalten, welche an der aktiven Datentabelle vorgenommen wurden. Dies umfasst neue Datensätze, veränderte Datensätze, sowie gelöschte Datensätze. Die Art der Änderung wird im Attribut 0RECORDMODE festgehalten, welches die folgenden Ausprägungen haben kann:
” ” = Geänderter Datensatz, nach Änderung
“N” = Neuer Datensatz
“X” = Geänderter Datensatz, vor Änderung
“D” = Gelöschter Datensatz
“R” = Umkehrbarer Datensatz, entspricht “X”, jedoch wird beim Laden eines schlüsselgleichen Datensatzes, der mit “R” markierte gelöscht.
Soweit kannte man dies auch aus dem (Standard) Data Store Object des klassischen SAP BW. Doch wie unterscheidet sich das aDSO von dem DSO?
Im folgenden Screenshot sieht man alle DDIC Objekte eines aDSO. Die Struktur dieser ist bei jedem aDSO identisch und einzelne Tabellen oder Views lassen sich anhand der abschließenden Ziffer im Namen erkennen. Hierbei stehen die Ziffern 1-3 für die zuvor genannten Tabellen, welche je nach Konfiguration aktiv oder nicht aktiv sein können.
Einen Unterschied zu herkömmlichen DSO stellen die zusätzlichen Views mit den Endziffern 6-8 dar. Diese werden standardmäßig immer bei Aktivierung eines aDSO erzeugt und können zum Zugriff auf Daten genutzt werden. Die Views können in der HANA Entwicklungsperspektive unter folgendem Pfad gefunden und direkt zur Modellierung verwendet werden. Gegenüber generierten HANA Calculation Views hat der externe SQL View Performancevorteile (siehe auch SAP Note 2723506), weil keine Joins zu Stammdaten gebildet werden (wenn Info Objekte im aDSO sind). Dadurch kann er gut bei Look-ups oder der HANA seitigen Verarbeitung verwendet werden.
Typen eines aDSO
Im Folgenden wird eine kompakte Übersicht zu verfügbaren und sinnvollen Modellierungseigenschaften von aDSO gegeben.
Allgemein ist es empfehlenswert im Rahmen der Aktivierung eines aDSO immer eine externe SAP-HANA-View erzeugen zu lassen. Diese kann in der HANA-Modellierungsperspektive weiterverwendet, sowie über Frontends konsumiert werden. Dies kann zu einer optimierten Performance verhelfen. Seit BW/4HANA 2.0 werden allerdings auch automatisch drei unterschiedliche Views zu jedem aDSO erzeugt (siehe “Aufbau eines aDSO), sodass nicht notwendigerweise eine Calculation View über die aDSO Konfiguration angelegt werden muss.
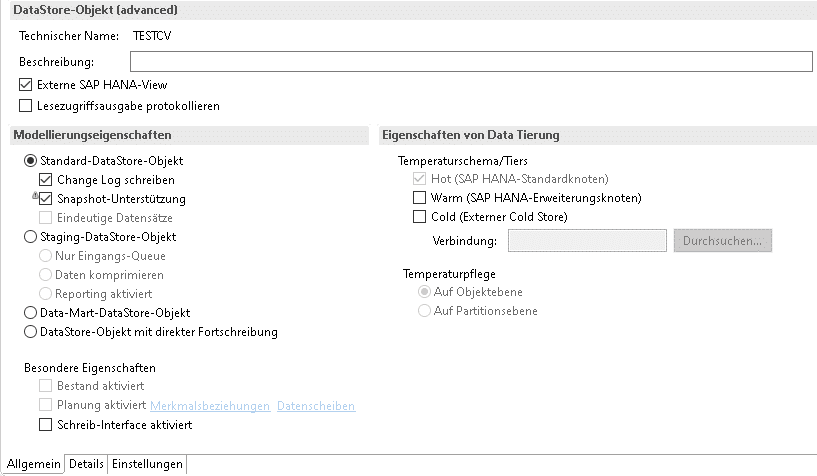
“Standard”
Die Auswahl des Standard-DataStore-Objekt in den Modellierungseigenschaften führt dazu, dass folgende Eigenschaften aus- beziehungsweise abgewählt werden können:
“Change Log schreiben” – Die ChangeLog-Tabelle wird genutzt und es werden Änderungen an der Aktiven-Datentabelle festgehalten. Das Reporting auf dem aDSO ist verfügbar.
“Snapshot-Unterstützung” – Alle Requests werden vollständig in die Aktive-Datentabelle geschrieben und Löschungen werden erkannt. Das Reporting auf dem aDSO ist verfügbar.
“Eindeutige Datensätze” – Während der Aktivierung werden schlüsselgleiche Datensätze nicht fortgeschrieben. Das Reporting auf dem aDSO ist verfügbar.
Die Eingangstabelle, sowie die Aktive-Datentabelle sind in diesem Fall immer aktiv.
Das Standard aDSO kann verschiedene Szenarien abdecken. Zum einen kann es wie ein klassisches DSO in Datenflüsse integriert werden. Dann bietet sich der Change Log an, so dass Delta-Datensätze fortgeschrieben werden können. Falls keine Delta-Fortschreibung benötigt wird, kann grundsätzlich auf das Change Log verzichtet werden und DB-Platz wird gespart. Die Snapshot-Unterstützung ist eine tolle Erweiterung der Delta-Funktionalität, weil Löschungen in Quelltabellen erkannt werden (vorausgesetzt es erfolgt eine Full-Beladung).
Abb.: aDSO-Typen: Standard | isr.de
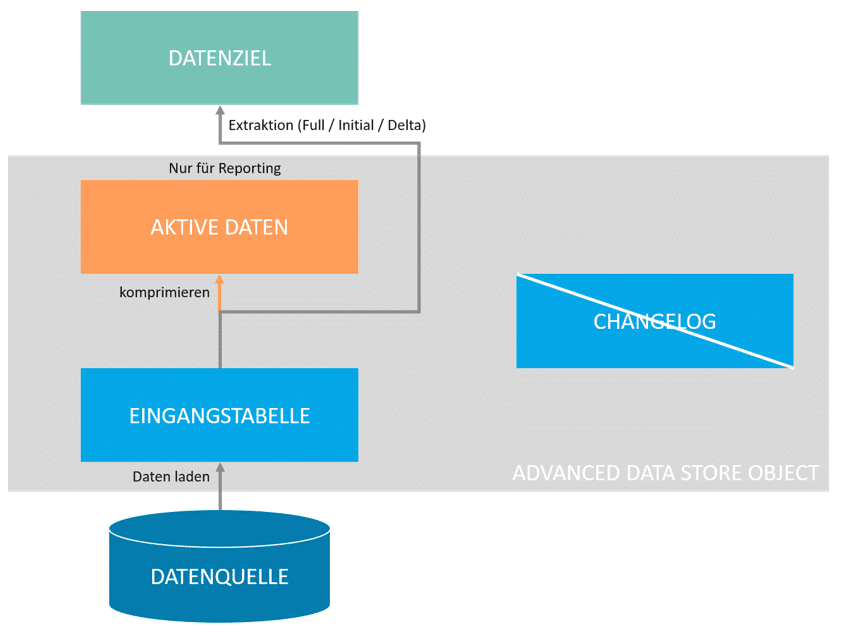
“Staging”
Die Auswahl des Staging-DataStore-Objekts in den Modellierungseigenschaften führt dazu, dass folgende Eigenschaften aus- beziehungsweise abgewählt werden können:
“Nur Eingangs-Queue” – Es wird nur die Eingangstabelle verwendet. Datensätze werden mit einem technischen Schlüssel! = Primärschlüssel gespeichert. Das Reporting auf dem aDSO ist nicht verfügbar.
“Daten komprimieren” – Es werden die Eingangstabelle, sowie zur komprimierten Speicherung der Daten die Aktive-Datentabelle verwendet. Das Reporting auf dem aDSO ist nicht verfügbar.
“Reporting aktiviert” – Es werden die Eingangstabelle, sowie zur Aktivierung der Daten die Aktive-Datentabelle verwendet. Auch nach Aktivierung verbleiben die Daten zusätzlich in der Eingangstabelle. Das Reporting auf dem aDSO ist verfügbar.
Die Eingangstabelle ist in diesem Fall immer aktiv und wird zur Datenextraktion verwendet. Die Aktive-Datentabelle wird ausschließlich für Reportingzwecke genutzt.
In der Regel sollte ein Staging aDSO verwendet werden, wenn Daten weiterverarbeitet werden sollen. Beispielsweise kann ein Staging-aDSO als Zwischenpersistenz dienen, auf welche dann über weitere Transformationen zugegriffen, sowie in weitere Datenziele geladen wird. In der einfachsten Einstellung (nur Eingangs Queue) entspricht das aDSO weitgehend dem alten schreiboptimierten DSO.
Abb.: aDSO-Typen: Staging | isr.de
“Data-Mart”
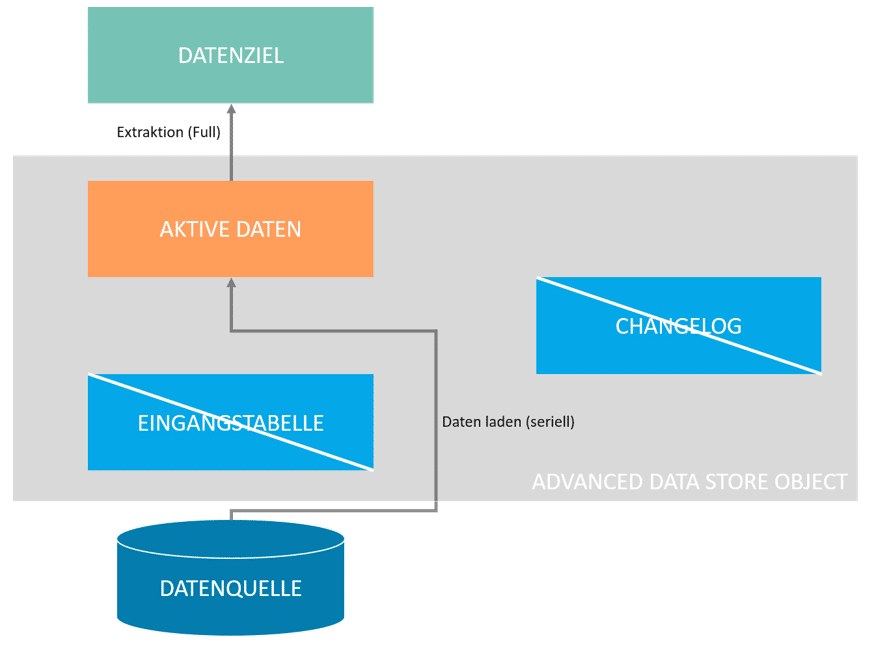
Die Auswahl des Staging-DataStore-Objekts in den Modellierungseigenschaften führt dazu, dass Ladevorgänge nur als Additivdelta ausgeführt werden können. Ein Überschreiben von Datensätze ist nicht vorgesehen. Alle Merkmale sind Schlüsselfelder (analog zu InfoCubes in BW 7.x). Das Reporting auf dem aDSO ist verfügbar. Die Extraktion aus der Quelle findet seriell statt.
Die Eingangstabelle sowie die Aktive-Datentabelle sind in diesem Fall immer aktiv.
Dieser Typ eines aDSO verhält sich wie ein InfoCube in früheren SAP BW Versionen. So zählen alle Merkmale als Schlüssel. Darüber hinaus wird die aktive Datentabelle in Form eines Additivdeltas aktualisiert.
Abb.: aDSO-Typen: Data Mart | isr.de
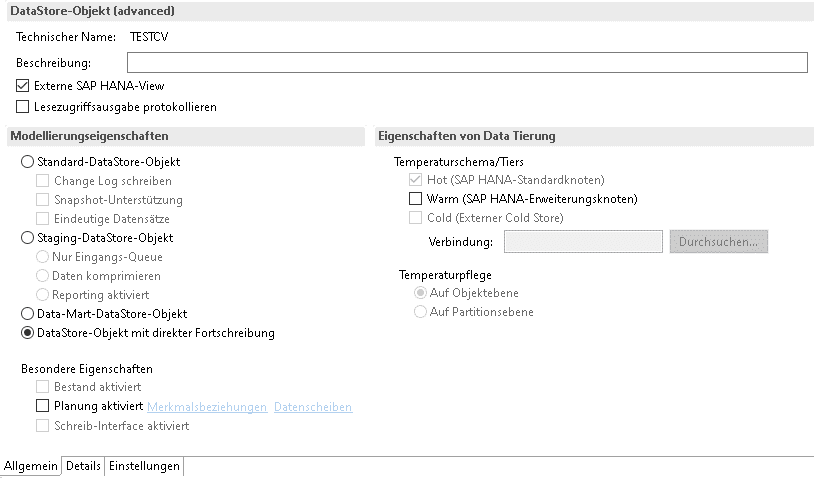
“Direkte Fortschreibung”
Die Auswahl des DataStore-Objekts mit direkter Fortschreibung in den Modellierungseigenschaften führt dazu, dass direkt in die Aktive-Datentabelle geschrieben wird. Es finden zwar einzelne Checks (u.a. SID Verwaltung, Konsistenz von Zeitmerkmalen), jedoch keine Überprüfung auf überlappende Requests statt. Das Reporting auf dem aDSO ist verfügbar.
Die Aktive-Datentabelle ist in diesem Fall immer aktiv.
Diese Konfiguration bietet die Möglichkeit, per DTP, aber auch mittels einer API in die Aktive-Datentabelle eines aDSO zu schreiben. Eine anschließende Extraktion ist jedoch nur als Full möglich.
Abb.: aDSO-Typen: Direkte Fortschreibung
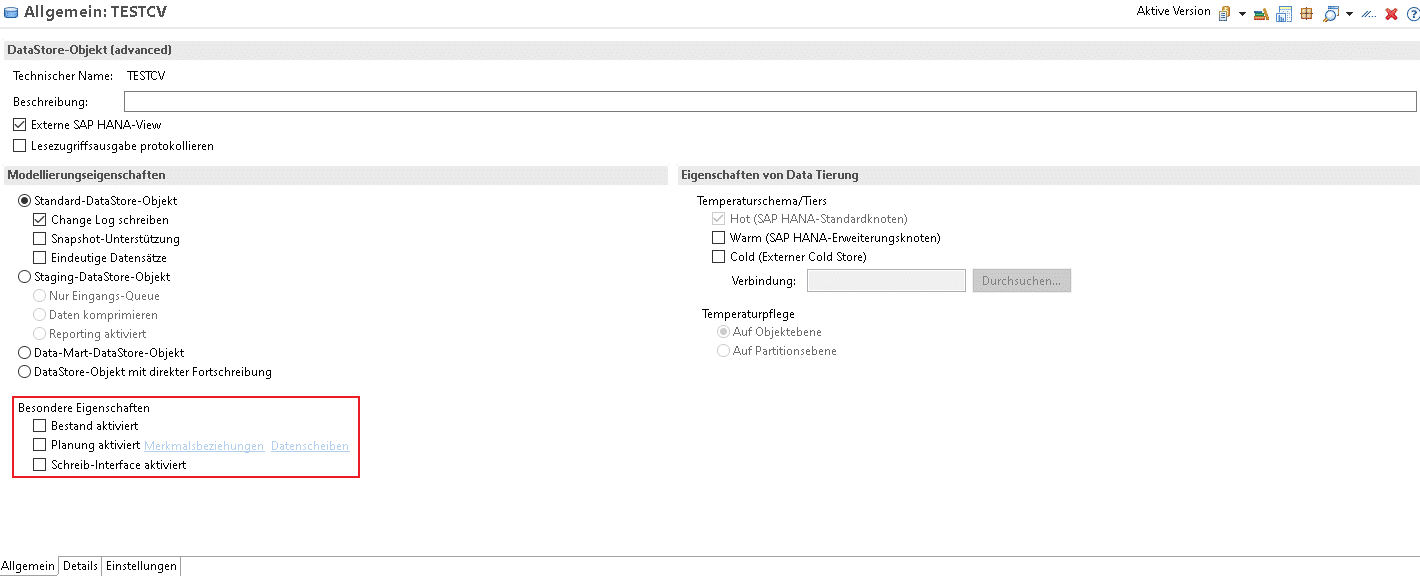
“Besondere Eigenschaften”
Es gibt zusätzliche Eigenschaften, welche einem aDSO zugewiesen werden können. Auf zwei gehen wir im Folgenden ein:
Planung
Hierzu zählt unter anderem die Planungseigenschaft. Wird diese aktiviert, so kann das aDSO zwischen zwei Zuständen wechseln, Lademodus und Planmodus. Im Planmodus kann durch Planungsapplikationen, wie zum Beispiel Analysis for Office oder SAP Analytics Cloud direkt in das aDSO zurückgeschrieben werden. BPC 11 wird für diese Option benötigt. Im Lademodus ist dies nicht möglich damit Daten problemlos geladen werden können.
Schreib-Interface
Eine weitere mögliche Eigenschaft stellt die Aktivierung des Schreib-Interfaces dar. Wird dieses aktiviert, ist es möglich, dass externe Tools, beispielsweise SAP Data Services, Data Intelligence oder Platform Integration direkt in die Eingangstabelle des aDSO schreiben können. Diese Eigenschaft kann nicht zusammen mit der Bestands- oder Planungsaktivierung genutzt werden.
Modellierung von aDSO mit Feldern und/ oder InfoObjects
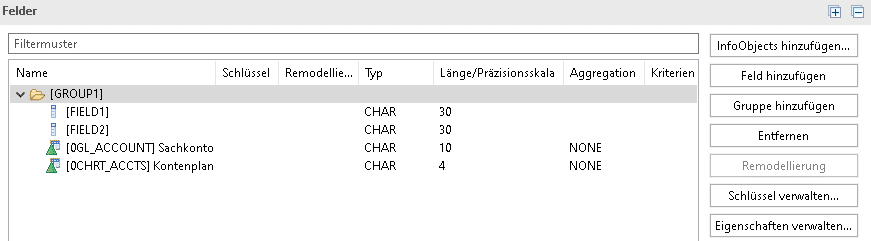
Eine der interessantesten Innovationen, welche das advanced Data Store Object im Gegensatz zum älteren Data Store Object mit sich bringt, ist die Möglichkeit der feldbasierten Modellierung (oder auch Bottom-up Modellierung). Hierfür können im Modellierungsprozess die Felder der Datenquelle meist 1 zu 1 übernommen werden (sofern Datentyp und -länge nutzbar sind). Die Felder können einfach basierend auf dem jeweiligen Quellobjekt generiert werden. Der Zwang zum Anlegen und Konfigurieren von teils sehr vielen InfoObjects (je nach Systemgröße auch >1000) entfällt. Dies kann die Datenmodellierung erheblich beschleunigen. Auf der anderen Seite gibt es auch Vorteile von InfoObjects auf die so verzichtet werden muss. Unzweifelhaft bringt es Vorteile mit, wenn ein InfoObject den Feldtyp und die Länge für eine Business Entität im gesamten System definiert. Bei der feldbasierten Modellierung muss manuell sichergestellt werden, dass bspw. das Feld Kunde überall den gleichen Feldtyp und Länge besitzt. Dies ist notwendig, um später beim Assoziieren keine Probleme zu bekommen. Auch gemischte Szenarien bei denen für bestimmte Business Entitäten Info Objekte genutzt (z.B. Business Content) werden und für andere Informationen Felder. Die Entscheidung sollte kontextbezogen getroffen werden.
Auf diese Frage können wir klar mit eine “Jein” antworten. Die Konsolidierung von vier Info-Providern in das aDSO ist erstmal eine Vereinfachung der Architektur. Andererseits lassen sich die “alten” Objekte durch Einstellungen des aDSO nachbilden, um so benötigte Datenmodell-Szenarien zu bedienen. Dadurch steigt auf der anderen Seite aber wieder die Komplexität, weil Entwickler die Auswirkungen und Zusammenhänge der verschiedenen aDSO-Einstellungen verstehen müssen.
Aus unserer Sicht ist das Konstrukt des aDSO insgesamt eine sehr runde ausgereifte Entwicklung. Wie bereits das Vorgängerobjekt (Data Store Object), kann auch das advanced Data Store Object, als zentrales Speichermedium im SAP Business Warehouse überzeugen. Es bietet bewährte Funktionalitäten aus älteren SAP BW-Systemen, darunter die Deltaverarbeitung sowie das SID- und Schlüsselhandling. Darüber hinaus bringt es einige interessante Neuerungen mit wie zum Beispiel die Möglichkeit der feldbasierten Modellierung durch welche Entwicklungen schneller ablaufen können. Begründet liegt es darin, dass bei der Bottom-Up Modellierung die Datenintegration & Analyse vor der Festlegung der Semantik (= InfoObjects) stattfinden kann, wodurch Anwender sehr schnell erste Datensichtungen durchführen können. Hierzu lohnt sich ein Blick in den Blogpost “Agiles Data Warehousing mit SAP BW/4HANA“.
Dabei sollte stets individuell abgewogen werden, welcher Modellierungsansatz am besten den Anforderungen entspricht. Ansonsten könnten bei zu beschränkter Planung beispielsweise, die bei der feldbasierten Modellierung eingesparten Aufwände schnell wieder verloren gehen, wenn zum Beispiel festgestellt werden sollte, dass man doch aufgrund von komplexen Stammdatenszenarien auf InfoObjects zurückgreifen möchte. Eine nachträgliche Anpassung von der Architektur ist stets möglich und wird durch die “Remodellierungsfunktion” eines aDSO erheblich vereinfacht. Je nach Komplexität der Änderungen müssen jedoch auch bestimmte Voraussetzungen erfüllt sein, da die Remodellierung sonst zu Fehlermeldungen bis hin zum Datenverlust kommen könnte (siehe SAP Help Portal).
Wir agieren seit 1993 als IT-Berater für Data Analytics und Dokumentenlogistik und fokussieren uns auf das Datenmanagement und die Automatisierung von Prozessen. Ganzheitlich und im Rahmen eines umfassenden Enterprise Information Managements (EIM) begleiten wir von der strategischen IT-Beratung über konkrete Implementierungen und Lösungen bis hin zum IT-Betrieb. ISR ist Teil der CENIT EIM-Gruppe.